Du är här:Start ”Machine Vision Guide ”Mallmatchning
Introduktion

Mallmatchning är en teknik för maskinseende på hög nivå som identifierar de delar i en bild som matchar en fördefinierad mall. Avancerade algoritmer för mallmatchning gör det möjligt att hitta förekomster av mallen oavsett deras orientering och lokala ljusstyrka.
Mallmatchningstekniker är flexibla och relativt enkla att använda, vilket gör dem till en av de mest populära metoderna för lokalisering av objekt. Deras användbarhet begränsas främst av den tillgängliga beräkningskraften, eftersom identifiering av stora och komplexa mallar kan vara tidskrävande.
Koncept
Template Matching-tekniker förväntas tillgodose följande behov: om vi får en referensbild av ett objekt (mallbilden) och en bild som ska inspekteras (inmatningsbilden) vill vi identifiera alla inmatningsbildens platser där objektet från mallbilden är närvarande. Beroende på det specifika problemet kan vi (eller kanske inte) vilja identifiera de roterade eller skalade förekomsterna.
Vi kommer att börja med en demonstration av en naiv mallmatchningsmetod, som är otillräcklig för verkliga tillämpningar, men som illustrerar kärnkonceptet från vilket de faktiska mallmatchningsalgoritmerna härstammar. Därefter kommer vi att förklara hur denna metod förbättras och utökas i avancerade rutiner för gråskalabaserad matchning och kantbaserad matchning.
Naiv Template Matching
Föreställ dig att vi ska inspektera en bild av en plugg och att vårt mål är att hitta dess stift. Vi får en mallbild som representerar det referensobjekt vi letar efter och den inmatningsbild som ska inspekteras.
 |
 |
|
Mallbild |
Inputbild |
Vi kommer att utföra själva sökningen på ett ganska okomplicerat sätt – vi kommer att placera mallen över bilden på varje möjlig plats, och varje gång kommer vi att beräkna ett numeriskt mått på likheten mellan mallen och det bildsegment som den för närvarande överlappar med. Slutligen kommer vi att identifiera de positioner som ger de bästa likhetsmåtten som de sannolika mallförekomsterna.
Bildkorrelation
Ett av de delproblem som förekommer i specifikationen ovan är att beräkna likhetsmåttet för den anpassade mallbilden och det överlappande segmentet av inmatningsbilden, vilket är likvärdigt med att beräkna ett likhetsmått för två bilder med samma dimensioner. Detta är en klassisk uppgift, och ett numeriskt mått på bildlikhet brukar kallas bildkorrelation.
Cross-Correlation
| Image1 | Image2 | Cross-Korrelation |
|---|---|---|
|
 |
19404780 |
|
 |
23316890 |
|
 |
24715810 |
Den grundläggande metoden för att beräkna bildkorrelationen är så kallad korskoppling.korrelation, som i huvudsak är en enkel summa av parvisa multiplikationer av motsvarande pixelvärden i bilderna.
Tyvärr kan vi konstatera att korrelationsvärdet verkligen verkar spegla likheten mellan de jämförda bilderna, men korskorrelationsmetoden är långt ifrån robust. Dess största nackdel är att den påverkas av förändringar i bildernas globala ljusstyrka – om en bild blir ljusare kan korskorrelationen med en annan bild skjuta i höjden, även om den andra bilden inte alls liknar den.
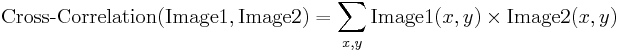
Normaliserad korrelation
| Bild1 | Bild2 | NCC |
|---|---|---|
|
|
-0.417 |
|
|
0.553 |
|
|
0.844 |
Normaliserad korskorrelation är en förbättrad version av den klassiska korrelationsmetoden som introducerar två förbättringar jämfört med originalet:
- Resultaten är invariant för globala ljushetsförändringar, dvs.D.v.s. en konsekvent upp- eller nedtoning av någon av bilderna har ingen effekt på resultatet (detta åstadkoms genom att subtrahera medelbildens ljusstyrka från varje pixelvärde).
- Det slutliga korrelationsvärdet skalas till intervallet, så att NCC för två identiska bilder är lika med 1,0, medan NCC för en bild och dess negation är lika med -1,0.
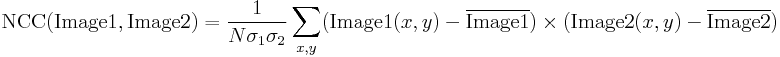
Mall för korrelationsbild
Låt oss återgå till det aktuella problemet. Efter att ha infört Normalized Cross-Correlation – ett robust mått på bildlikhet – kan vi nu avgöra hur väl mallen passar i var och en av de möjliga positionerna. Vi kan representera resultaten i form av en bild, där varje pixels ljusstyrka representerar NCC-värdet för mallen som placeras över denna pixel (svart färg representerar minimal korrelation på -1,0, vit färg representerar maximal korrelation på 1,0).
|
|
 |
|
Mallbild |
Inputbild |
Mallkorrelationsbild |
Identifiering av matchningar
Det enda som behöver göras i det här skedet är att bestämma vilka punkter i bilden av mallkorrelationen som är tillräckligt bra för att betraktas som faktiska matchningar. Vanligtvis identifierar vi som matchningar de positioner som (samtidigt) representerar mallkorrelationen:
- stärkare än något fördefinierat tröskelvärde (dvs. starkare att 0.5)
- lokalt maximal (starkare än mallkorrelationen i grannpixlarna)
 |
 |
 |
|
Asområden med en mallkorrelation över 0.75 |
Punkter med lokalt maximal mallkorrelation |
Punkter med lokalt maximal mallkorrelation över 0,75 |
Sammanfattning
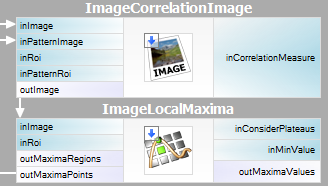
Det är ganska enkelt att uttrycka den beskrivna metoden i Adaptive Vision Studio – vi behöver bara två inbyggda filter. Vi kommer att beräkna mallkorrelationsbilden med hjälp av filtret ImageCorrelationImage och sedan identifiera matchningarna med hjälp av ImageLocalMaxima – vi behöver bara ställa in parametern inMinValue som kommer att avskärma de svaga lokala maxima från resultaten, vilket diskuterades i föregående avsnitt.
Trots att den introducerade tekniken var tillräcklig för att lösa det aktuella problemet kan vi notera dess viktiga nackdelar:
- Mallförekomster måste bevara orienteringen av referensmallbilden.
- Metoden är ineffektiv, eftersom det är tidskrävande att beräkna mallkorrelationsbilden för medelstora till stora bilder.
I de kommande avsnitten kommer vi att diskutera hur dessa problem hanteras i avancerade mallmatchningstekniker: Grayscale-based Matching och Edge-based Matching.
Grayscale-based Matching, Edge-based Matching
Grayscale-based Matching är en avancerad mallmatchningsalgoritm som utökar den ursprungliga idén om korrelationsbaserad malldetektering, vilket förbättrar effektiviteten och gör det möjligt att söka efter förekomster av mallar oberoende av deras orientering. Edge-based Matching förbättrar denna metod ytterligare genom att begränsa beräkningen till objektets kantområden.
I det här avsnittet kommer vi att beskriva de inneboende detaljerna i båda algoritmerna. I nästa avsnitt (Filter toolset) kommer vi att förklara hur man använder dessa tekniker i Adaptive Vision Studio.
Image Pyramid
Image Pyramid är en serie bilder, där varje bild är ett resultat av downsampling (nedskalning, med faktorn två i det här fallet) av det föregående elementet.
|
 |
 |
|
Nivå 0 (ingångsbild) |
Nivå 1 |
Nivå 2 |
Pyramidbehandling
Bildpyramider kan användas för att öka effektiviteten i korrelations-baserad malldetektering. Den viktiga iakttagelsen är att den mall som avbildas i referensbilden vanligtvis fortfarande är urskiljbar efter en betydande nedskalning av bilden (även om fina detaljer naturligtvis går förlorade i processen). Därför kan vi identifiera matchningskandidater i den nedskalade (och därför mycket snabbare att bearbeta) bilden på den högsta nivån i vår pyramid, och sedan upprepa sökningen på de lägre nivåerna i pyramiden, varvid vi varje gång endast tar hänsyn till de positioner av mallen som fick höga poäng på den föregående nivån.
På varje nivå i pyramiden behöver vi en lämpligt nedskalad bild av referensmallen, dvs. både en inmatningsbildspyramid och en pyramid av mallen bör beräknas.
 |
 |
 |
|
Nivå 0 (referensbild för mall) |
Nivå 1 |
Nivå 2 |
Gråskala-based Matching
Och i vissa tillämpningar är objektens orientering enhetlig och fast (som vi har sett i proppexemplet), är det ofta så att de objekt som ska upptäckas ser roterade ut. I algoritmer för mallmatchning anpassas den klassiska pyramidsökningen för att möjliggöra matchning med flera vinklar, dvs. identifiering av roterade instanser av mallen.
Detta uppnås genom att beräkna inte bara en pyramid för mallbilden, utan en uppsättning pyramider – en för varje möjlig rotation av mallen. Under pyramidsökningen på inmatningsbilden identifierar algoritmen paren (mallposition, mallorientering) snarare än enbart mallpositioner. På samma sätt som i det ursprungliga schemat kontrollerar algoritmen på varje nivå av sökningen endast de par (position, orientering) som fick bra resultat på föregående nivå (dvs. som verkade matcha mallen i bilden med lägre upplösning).
 |
 |
|
|
Mallbild |
Inputbild |
Resultat av multi-vinkelmatchning |
Tekniken med pyramidmatchning tillsammans med sökning i flera vinklar utgör den gråskalabaserade metoden för mallmatchning.
Kantbaserad matchning
Kantbaserad matchning förbättrar den tidigare diskuterade gråskalabaserade matchningen med hjälp av en avgörande observation – att formen på ett objekt huvudsakligen definieras av formen på dess kanter. I stället för att matcha hela mallen kan vi därför extrahera dess kanter och matcha endast de närliggande pixlarna, vilket gör att vi undviker vissa onödiga beräkningar. I vanliga tillämpningar är den uppnådda hastighetsökningen vanligtvis betydande.
| Gråskalabaserad matchning: | |
 |
 |
|---|---|---|---|
| Kantbaserad matchning: |  |
 |
 |
|
Olika typer av mallpyramider som används i algoritmer för mallmatchning. |
|||
För att matcha objektkanter i stället för ett objekt som helhet krävs en liten modifiering av den ursprungliga pyramidmatchningsmetoden: tänk dig att vi matchar ett objekt med enhetlig färg som är placerat över en enhetlig bakgrund. Alla objektets kantpixlar skulle ha samma intensitet och den ursprungliga algoritmen skulle matcha objektet var som helst där det finns en tillräckligt stor klump av lämplig färg, och detta är uppenbarligen inte vad vi vill uppnå. För att lösa detta problem är det i kantbaserad matchning gradientriktningen (representerad som en färg i HSV-rymden för illustrativa ändamål) för kantpixlarna, inte deras intensitet, som matchas.
Filterverktygssats
Adaptive Vision Studio tillhandahåller en uppsättning filter som implementerar både gråskalabaserad matchning och kantbaserad matchning. För en lista över filtren se Filter för mallmatchning.
Eftersom mallbilden måste förbehandlas före pyramidmatchningen (vi måste beräkna mallbildens pyramider för alla möjliga rotationer) är algoritmerna uppdelade i två delar:
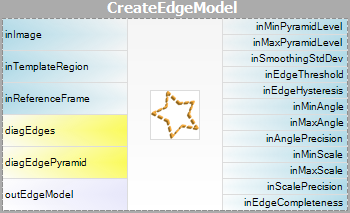
- Modellskapande – i det här steget beräknas mallbildens pyramider och resultaten sparas i en modell – ett atomärt objekt som representerar alla data som behövs för att köra pyramidmatchningen.
- Matchning – i detta steg används mallmodellen för att matcha mallen i inmatningsbilden.
En sådan organisation av bearbetningen gör det möjligt att beräkna modellen en gång och återanvända den flera gånger.
Available Filters
För båda metoderna för mallmatchning tillhandahålls två filter, ett för varje steg i algoritmen.
| Grayscale-based Matching | Edge-based Matching | |
|---|---|---|
| Modellskapande: | 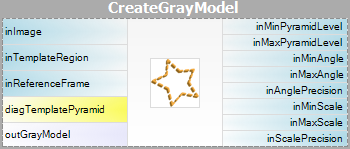 |
 |
| Matchning: | 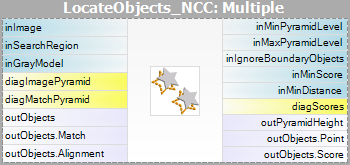 |
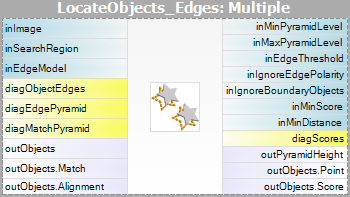 |
Observera att filtren CreateGrayModel och CreateEdgeModel endast behövs i mer avancerade tillämpningar. Annars räcker det med att använda ett enda filter i steget Matching och skapa modellen genom att ställa in parametern inGrayModel eller inEdgeModel för filtret. För mer information se Skapa modeller för mallmatchning.
Den största utmaningen med att tillämpa tekniken för mallmatchning ligger i noggrann justering av filterparametrar, snarare än att utforma programstrukturen.
Avancerat applikationsschema
Det finns flera typer av avancerade applikationer, för vilka det interaktiva grafiska gränssnittet för mallmatchning inte räcker till och användaren måste använda filtret CreateGrayModel eller CreateEdgeModel direkt. Till exempel:
- När skapandet av modellen kräver icke-trivial förbehandling av bilder.
- När vi behöver en hel rad modeller som skapas automatiskt från en uppsättning bilder.
- När slutanvändaren bör kunna definiera sina egna mallar i körtidstillämpningen (t.ex. genom att göra ett urval på en inmatningsbild).
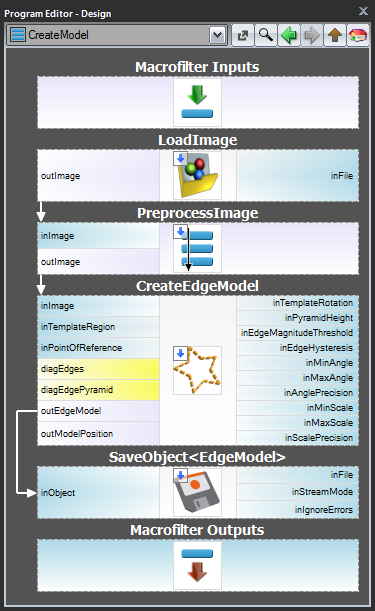
Schema 1: Modellskapande i ett separat program
För fallen 1 och 2 är det tillrådligt att implementera modellskapande i ett separat Task-makrofilter,spara modellen i en AVDATA-fil och sedan länka den filen till inmatningen av det matchande filtret i huvudprogrammet:
| Modellskapande: | Huvudprogram: |
|---|---|
 |
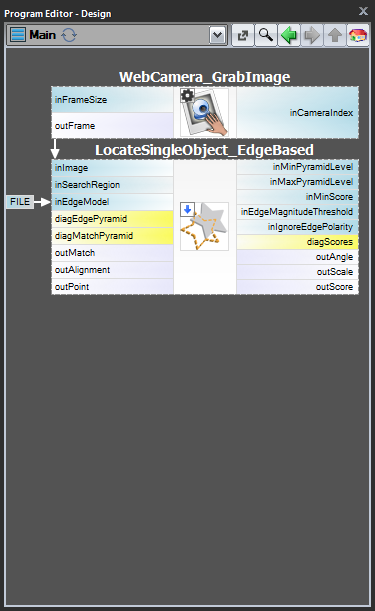 |
När det här programmet är färdigt kan du köra uppgiften ”CreateModel” som ett program när du vill skapa modellen. Länken till datafilen i matchningsfiltrets ingång behöver inte ändras då, eftersom det bara är en länk och det som ändras är filen på disken.
Schema 2: Dynamisk modellskapande
För fall 3, när modellen måste skapas dynamiskt, måste både det modellskapande filtret och matchningsfiltret finnas i samma uppgift. Det förstnämnda ska dock exekveras villkorligt när en HMI-händelse inträffar (t.ex. när användaren klickar på en ImpulseButton eller gör någon musaktion i en VideoBox). För att representera modellen bör man använda ett register av typen Registerof EdgeModel? som lagrar den senaste modellen (ett annat alternativ är att använda filtret LastNotNil).Här är ett exempel på realisering där modellen skapas från en fördefinierad ruta på en inmatningsbild när en knapp klickas på i HMI:
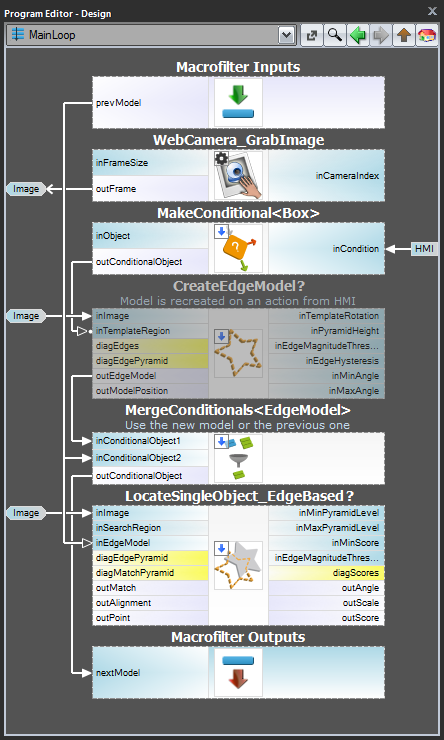
Modellskapande
Pyramidens höjd
Parametern inPyramidHeight bestämmer antalet nivåer i pyramidmatchningen och bör ställas in på det största antalet för vilket mallen fortfarande kan kännas igen på den högsta pyramidnivån. Detta värde bör väljas genom interaktivt experimenterande med hjälp av den diagnostiska utgången diagPatternPyramid (gråskalabaserad matchning) eller diagEdgePyramid (kantbaserad matchning).
I följande exempel skulle inPyramidHeight-värdet 4 vara för högt (för båda metoderna), eftersom mallen helt förlorar sin struktur på denna nivå av pyramiden. Värdet 3 verkar också lite överdrivet (särskilt när det gäller kantbaserad matchning), medan värdet 2 definitivt skulle vara ett säkert val.
| Nivå 0 | Nivå 1 | Nivå 2 | Nivå 3 | Nivå 4 | |
|---|---|---|---|---|---|
| Grayscale-based Matching (diagPatternPyramid): |
 |
 |
 |
 |
 |
| Edge-based Matching (diagEdgePyramid): |
 |
 |
 |
 |
 |
Angle Range
Parametrarna inMinAngle, inMaxAngle bestämmer det intervall av mallorienteringar som kommer att beaktas i matchningsprocessen. Till exempel (värden inom parentes representerar paren av inMinAngle- och inMaxAngle-värden):
- (0.0, 360.0): alla rotationer beaktas (standardvärde)
- (-15.0, 15.0): mallens förekomster tillåts avvika från referensmallens orientering med högst 15,0 grader (i vardera riktningen)
- (0.0, 0.0): mallens förekomster förväntas behålla referensmallens orientering
Ett brett utbud av möjliga orienteringar medför betydande overhead (både i fråga om minnesanvändning och beräkningstid), så det är tillrådligt att begränsa utbudet när det är möjligt.
Inställningar för kantdetektering (endast kantbaserad matchning)
Parametrarna inEdgeMagnitudeThreshold, inEdgeHysteresis i CreateEdgeModel-filtret bestämmer inställningarna för den hysteresetröskel som används för att upptäcka kanter i mallbilden. Ju lägre värdet för inEdgeMagnitudeThreshold är, desto fler kanter kommer att upptäckas i mallbilden. Dessa parametrar bör ställas in så att alla signifikanta kanter i mallen upptäcks och mängden överflödiga kanter (brus) i resultatet är så begränsad som möjligt. På samma sätt som pyramidhöjden bör tröskelvärdena för kantdetektering väljas genom interaktivt experimenterande med hjälp av den diagnostiska utgången diagEdgePyramid – den här gången behöver vi bara titta på bilden på den lägsta nivån.
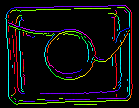 |
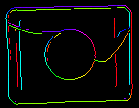 |
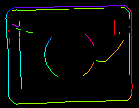 |
|
(15.0, 30.0) – för mycket buller |
(40.0, 60.0) – OK |
(60.0, 70.0) – betydande kanter förlorade |
Filtret CreateEdgeModel tillåter inte att man skapar en modell där inga kanter upptäcktes i toppen av pyramiden (vilket innebär att inte bara några betydande kanter förlorades, utan alla), vilket ger ett fel i sådana fall. Närhelst detta händer bör pyramidens höjd eller kanttrösklarna, eller båda, minskas.
Matching
Parametern inMinScore bestämmer hur tillåtande algoritmen kommer att vara vid verifiering av matchningskandidaterna – ju högre värde desto färre resultat kommer att returneras. Denna parameter bör ställas in genom interaktivt experimenterande till ett tillräckligt lågt värde för att säkerställa att alla korrekta matchningar returneras, men inte mycket lägre, eftersom ett för lågt värde saktar ner algoritmen och kan leda till att falska matchningar visas i resultaten.
Tips and Best Practices
Hur man väljer metod?
För den stora majoriteten av tillämpningar kommer Edge-based Matching-metoden att vara både mer robust och mer effektiv än Grayscale-based Matching. Den sistnämnda metoden bör endast övervägas om mallen har jämna färgövergångsområden som inte definieras av urskiljbara kanter, men som ändå bör matchas.
| Previous: Shape Fitting | Next: Shape Fitting | Next: Lokala koordinatsystem |