Du er her:Start “Machine Vision Guide “Skabelonmatchning
Indledning

Skabelonmatchning er en maskinsynsteknik på højt niveau, der identificerer de dele på et billede, der passer til en foruddefineret skabelon. Avancerede skabelonmatchningsalgoritmer gør det muligt at finde forekomster af skabelonen uanset deres orientering og lokale lysstyrke.
Skabelonmatchningsteknikker er fleksible og relativt enkle at anvende, hvilket gør dem til en af de mest populære metoder til lokalisering af objekter. Deres anvendelighed begrænses mest af den tilgængelige computerkraft, da identifikation af store og komplekse skabeloner kan være tidskrævende.
Koncept
Template Matching-teknikker forventes at imødekomme følgende behov: Forudsat et referencebillede af et objekt (skabelonbilledet) og et billede, der skal inspiceres (indgangsbilledet), ønsker vi at identificere alle indgangsbilledplaceringer, hvor objektet fra skabelonbilledet er til stede. Afhængigt af det specifikke problem ønsker vi måske (eller måske ikke) at identificere de roterede eller skalerede forekomster.
Vi vil starte med en demonstration af en naiv Template Matching-metode, som er utilstrækkelig til virkelige anvendelser, men som illustrerer det kernekoncept, som de egentlige Template Matching-algoritmer udspringer af. Derefter vil vi forklare, hvordan denne metode forbedres og udvides i avancerede gråskala-baserede matchningsrutiner og kantbaserede matchningsrutiner.
Naive Template Matching
Forestil dig, at vi skal inspicere et billede af en stikprop, og at vores mål er at finde dens stifter. Vi får et skabelonbillede, der repræsenterer det referenceobjekt, vi leder efter, og det indgangsbillede, der skal inspiceres.
 |
 |
|
Skabelonbillede |
Inputbillede |
Vi vil udføre selve søgningen på en ret simpel måde – vi vil placere skabelonen over billedet på alle mulige steder, og hver gang vil vi beregne et numerisk mål for ligheden mellem skabelonen og det billedsegment, som den i øjeblikket overlapper med. Til sidst vil vi identificere de positioner, der giver de bedste lighedsmål som de sandsynlige skabelonforekomster.
Billedkorrelation
Et af de delproblemer, der forekommer i ovenstående specifikation, er beregning af lighedsmålet for det justerede skabelonbillede og det overlappede segment af indgangsbilledet, hvilket svarer til beregning af et lighedsmål for to billeder af samme dimensioner. Dette er en klassisk opgave, og et numerisk mål for billedlighed kaldes normalt billedkorrelation.
Kryds-Korrelation
| Billede1 | Billede2 | Kryds-Korrelation |
|---|---|---|
|
 |
19404780 |
|
 |
23316890 |
|
 |
24715810 |
Den grundlæggende metode til beregning af billedkorrelationen er såkaldt cross-korrelation, som i bund og grund er en simpel sum af parvise multiplikationer af de tilsvarende pixelværdier i billederne.
Selv om vi kan bemærke, at korrelationsværdien faktisk synes at afspejle ligheden mellem de billeder, der sammenlignes, er kryds-korrelationsmetoden langt fra robust. Dens største ulempe er, at den er forudindtaget af ændringer i billedernes globale lysstyrke – hvis et billede bliver lysere, kan dets krydskorrelation med et andet billede stige voldsomt, selv om det andet billede slet ikke ligner hinanden.
\mbox{Cross-Correlation}(\mbox{Billede1}, \mbox{Billede2})= \sum_{x,y} \mbox{Image1}(x,y) \times \mbox{Image2}(x,y)
Normaliseret krydskorrelation
| Billede1 | Billede2 | NCC |
|---|---|---|
|
|
-0.417 |
|
|
0.553 |
|
|
0.844 |
Normaliseret krydskorrelation er en forbedret version af den klassiske krydskorrelationsmetode, der indfører to forbedringer i forhold til den oprindelige:
- Resultaterne er invariante over for de globale lysstyrkeændringer, dvs.Dvs. konsekvent lysning eller mørkfarvning af begge billeder har ingen effekt på resultatet (dette opnås ved at subtrahere billedets gennemsnitlige lysstyrke fra hver pixelværdi).
- Den endelige korrelationsværdi er skaleret til området, således at NCC for to identiske billeder er lig med 1,0, mens NCC for et billede og dets negation er lig med -1,0.
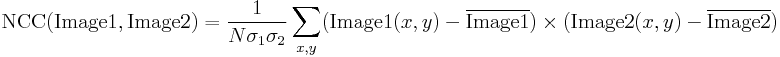
Skabelon korrelationsbillede
Lad os vende tilbage til det aktuelle problem. Efter at have indført den normaliserede krydskorrelation – et robust mål for billedets lighed – er vi nu i stand til at bestemme, hvor godt skabelonen passer ind i hver af de mulige positioner. Vi kan repræsentere resultaterne i form af et billede, hvor lysstyrken på hver enkelt pixel repræsenterer NCC-værdien af skabelonen placeret over denne pixel (sort farve repræsenterer den minimale korrelation på -1,0, hvid farve repræsenterer den maksimale korrelation på 1,0).
|
|
 |
|
|
Skabelonbillede |
Inputbillede |
Skabelonkorrelationsbillede |
Skabelonkorrelationsbillede |
Identifikation af matches
Det eneste, der skal gøres på dette tidspunkt, er at beslutte, hvilke punkter i skabelonkorrelationsbilledet, der er gode nok til at blive betragtet som egentlige matches. Normalt identificerer vi som matches de positioner, der (samtidig) repræsenterer skabelonkorrelationen:
- stærkere end en eller anden foruddefineret tærskelværdi (dvs. stærkere end 0.5)
- lokalt maksimalt (stærkere end skabelonkorrelationen i de tilstødende pixels)
 |
 |
 |
|
Områder med skabelonkorrelation over 0.75 |
Punkter med lokalt maksimal skabelonkorrelation |
Punkter med lokalt maksimal skabelonkorrelation over 0,75 |
Summary
Det er ret nemt at udtrykke den beskrevne metode i Adaptive Vision Studio – vi skal blot bruge to indbyggede filtre. Vi beregner skabelonkorrelationsbilledet ved hjælp af filteret ImageCorrelationImage og identificerer derefter matchningerne ved hjælp af ImageLocalMaxima – vi skal blot indstille parameteren inMinValue, som vil afskære de svage lokale maksima fra resultaterne, som diskuteret i det foregående afsnit.
Selv om den introducerede teknik var tilstrækkelig til at løse det pågældende problem, kan vi bemærke dens vigtige ulemper:
- Skabelonforekomster skal bevare orienteringen af referenceskabelonbilledet.
- Metoden er ineffektiv, da beregning af skabelonkorrelationsbilledet for mellemstore til store billeder er tidskrævende.
I de næste afsnit vil vi diskutere, hvordan disse problemer løses i avancerede skabelonmatchningsteknikker: Grayscale-based Matching og Edge-based Matching.
Grayscale-based Matching, Edge-based Matching
Grayscale-based Matching er en avanceret skabelonmatchningsalgoritme, der udvider den oprindelige idé om korrelationsbaseret skabelondetektering og forbedrer dens effektivitet og gør det muligt at søge efter skabelonforekomster uanset dens orientering. Edge-based Matching forbedrer denne metode endnu mere ved at begrænse beregningen til objektets kantområder.
I dette afsnit vil vi beskrive de iboende detaljer i begge algoritmer. I næste afsnit (Filterværktøjssæt) vil vi forklare, hvordan disse teknikker kan anvendes i Adaptive Vision Studio.
Billedpyramide
Billedpyramide er en serie billeder, hvor hvert billede er et resultat af downsampling (nedskalering, i dette tilfælde med en faktor to) af det foregående element.
|
 |
 |
|
Niveau 0 (indgangsbillede) |
Niveau 1 |
Niveau 2 |
Pyramidebehandling
Billedpyramider kan anvendes til at øge effektiviteten af korrelations-baserede skabelondetektion. Den vigtige observation er, at den skabelon, der er afbildet i referencebilledet, normalt stadig er synlig efter en betydelig downsampling af billedet (selv om der naturligvis går fine detaljer tabt i processen). Derfor kan vi identificere matchkandidater i det nedjusterede (og derfor meget hurtigere at behandle) billede på det højeste niveau i vores pyramide og derefter gentage søgningen på de lavere niveauer i pyramiden, idet vi hver gang kun tager hensyn til de skabelonpositioner, der scorede højt på det foregående niveau.
På hvert niveau i pyramiden skal vi bruge et passende nedjusteret billede af referenceskabelonen, dvs. der skal beregnes både en pyramide af indgangsbilledet og en pyramide af skabelonbilledet.
 |
 |
 |
|
Niveau 0 (skabelonreferencebillede) |
Niveau 1 |
Niveau 2 |
Gråskala-based Matching
Men i nogle af applikationerne er objektets orientering ensartet og fastlåst (som vi har set det i stikeksemplet), er det ofte tilfældet, at de objekter, der skal detekteres, ser roterede ud. I Template Matching-algoritmer tilpasses den klassiske pyramidesøgning til at multivinkelmatchning, dvs. identifikation af roterede forekomster af skabelonen.
Dette opnås ved at beregne ikke blot én pyramide af skabelonbilledet, men et sæt pyramider – én for hver mulig rotation af skabelonen. Under pyramidesøgningen på indgangsbilledet identificerer algoritmen parrene (skabelonposition, skabelonorientering) i stedet for kun skabelonpositioner. På samme måde som i det oprindelige skema kontrollerer algoritmen på hvert niveau af søgningen kun de par (position, orientering), der scorede godt på det foregående niveau (dvs. at de syntes at passe til skabelonen i billedet med lavere opløsning).
 |
 |
|
|
|
Skabelonbillede |
Inputbillede |
Resultater af multi-vinkeltilpasning |
Teknikken med pyramidetilpasning udgør sammen med søgning efter flere vinkler den gråskala-baserede skabelontilpasningsmetode.
Kantbaseret matchning
Kantbaseret matchning forbedrer den tidligere omtalte gråskala-baserede matchning ved hjælp af en afgørende observation – nemlig at formen af ethvert objekt hovedsageligt defineres af formen af dets kanter. I stedet for at matche hele skabelonen kan vi derfor udtrække dens kanter og kun matche de nærliggende pixels, hvorved vi undgår nogle unødvendige beregninger. I almindelige applikationer er den opnåede hastighedsforøgelse normalt betydelig.
| Grayscale-baseret matchning: | |
 |
 |
|---|---|---|---|
| Kantbaseret matchning: |  |
 |
 |
|
Differente former for skabelonpyramider, der anvendes i algoritmer for skabelonmatchning. |
|||
Matching af objektkanter i stedet for et objekt som helhed kræver en lille ændring af den oprindelige pyramidetilpasningsmetode: Forestil dig, at vi matcher et objekt med ensartet farve placeret over en ensartet baggrund. Alle objektets kantpixels ville have den samme intensitet, og den oprindelige algoritme ville matche objektet overalt, hvor der er en tilstrækkelig stor klat af den relevante farve, og det er tydeligvis ikke det, vi ønsker at opnå. For at løse dette problem er det i kantbaseret matchning gradientretningen (repræsenteret som en farve i HSV-rummet til illustrative formål) for kantpixelerne og ikke deres intensitet, der matches.
Filterværktøjssæt
Adaptive Vision Studio indeholder et sæt filtre, der implementerer både gråskala-baseret matchning og kantbaseret matchning. En liste over filtrene findes under Filtre til skabelonmatchning.
Da skabelonbilledet skal forbehandles før pyramidetilpasningen (vi skal beregne skabelonbilledpyramiderne for alle mulige rotationer), er algoritmerne opdelt i to dele:
- Modeloprettelse – i dette trin beregnes skabelonbilledpyramiderne, og resultaterne gemmes i en model – et atomart objekt, der repræsenterer alle de data, der er nødvendige for at køre pyramidetilpasningen.
- Matchning – i dette trin bruges skabelonmodellen til at matche skabelonen i indgangsbilledet.
En sådan organisering af behandlingen gør det muligt at beregne modellen én gang og genbruge den flere gange.
Afailable Filters
For begge Template Matching-metoder er der to filtre, ét for hvert trin i algoritmen.
| Grayscale-baseret matchning | Kantbaseret matchning | |
|---|---|---|
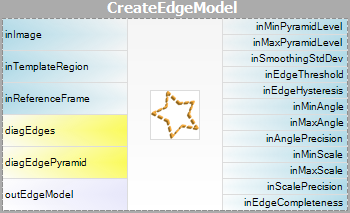
| Modeloprettelse: | 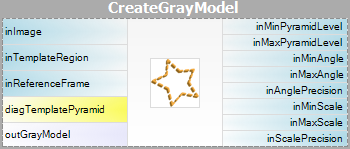 |
 |
| Matchning: | 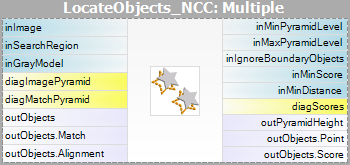 |
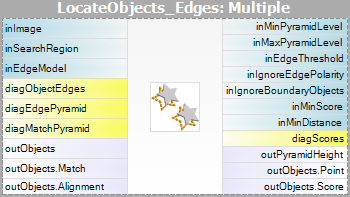 |
Bemærk venligst, at brugen af filtrene CreateGrayModel og CreateEdgeModel kun vil være nødvendig i mere avancerede applikationer. Ellers er det nok at bruge et enkelt filter i Matching-trinnet og oprette modellen ved at indstille parameteren inGrayModel eller inEdgeModel for filteret. For yderligere oplysninger se Oprettelse af modeller til skabelonmatchning.
Den største udfordring ved anvendelse af Template Matching-teknikken ligger i omhyggelig justering af filterparametre, snarere end i udformning af programstrukturen.
Advanced Application Schema
Der findes flere typer avancerede programmer, hvor den interaktive GUI til Template Matching ikke er tilstrækkelig, og hvor brugeren har brug for at bruge CreateGrayModel- eller CreateEdgeModel-filteret direkte. For eksempel:
- Når oprettelsen af modellen kræver ikke-triviel billedforbehandling.
- Når vi har brug for en hel række modeller, der oprettes automatisk ud fra et sæt billeder.
- Når slutbrugeren skal kunne definere sine egne skabeloner i runtime-applikationen (f.eks. ved at foretage et valg på et indgangsbillede).
Skema 1: Modeloprettelse i et separat program
For tilfælde 1 og 2 er det tilrådeligt at implementere modeloprettelse i et separat Task-makrofilter,gemme modellen til en AVDATA-fil og derefter linke denne fil til indgangen til det matchende filter i temainprogrammet:
| Modeloprettelse: | Hovedprogram: |
|---|---|
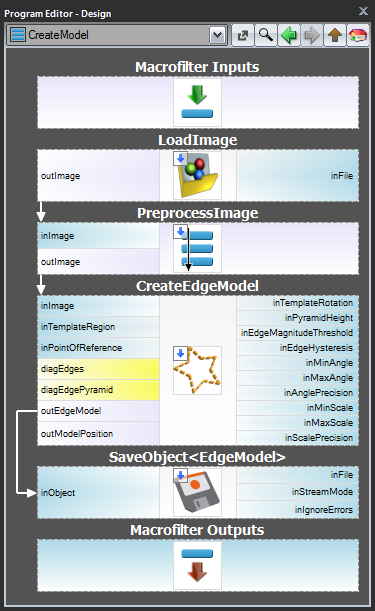 |
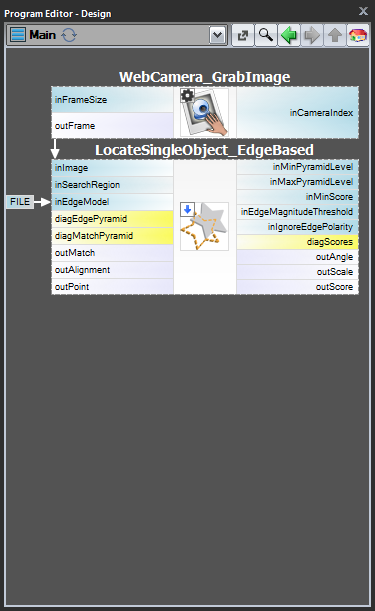 |
Når dette program er klar, kan du køre opgaven “CreateModel” som et program, når som helst du ønsker at oprette modellen. Linket til datafilen på input til matchingfilteret behøver så ikke at blive ændret, for det er kun et link, og det, der ændres, er kun filen på disken.
Skema 2: Dynamisk modeloprettelse
I tilfælde 3, hvor modellen skal oprettes dynamisk, skal både det modeloprettende filter og matchingfilteret være i den samme opgave. Førstnævnte skal dog udføres betinget, når en relevant HMI-begivenhed udløses (f.eks. når brugeren klikker på en ImpulseButton eller foretager en musebevægelse i en VideoBox). Til repræsentation af modellen bør der anvendes en registerof EdgeModel? type, som gemmer den seneste model (en anden mulighed er at anvende LastNotNil filteret).Her er et eksempel på en realisering, hvor modellen oprettes fra en foruddefineret boks på et indgangsbillede, når der klikkes på en knap i HMI:
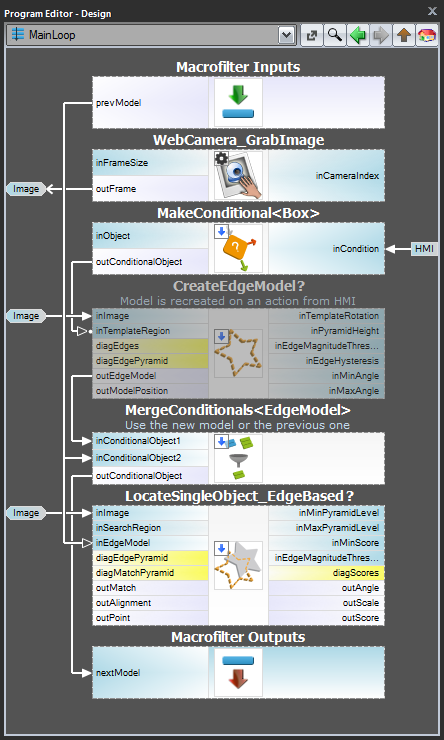
Model Creation
Height of the Pyramid
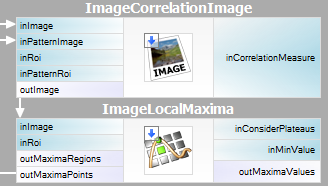
Parameteren inPyramidHeight bestemmer antallet af niveauer i pyramiden, der matcher, og bør sættes til det største antal, for hvilket modellen stadig kan genkendes på det højeste pyramideniveau. Denne værdi bør vælges ved interaktiv eksperimentering ved hjælp af diagnoseudgangen diagPatternPyramid (gråskala-baseret matchning) eller diagEdgePyramid (kantbaseret matchning).
I det følgende eksempel ville inPyramidHeight-værdien 4 være for høj (for begge metoder), da skabelonens struktur går helt tabt på dette niveau af pyramiden. Også værdien 3 virker en smule overdrevet (især i tilfælde af Edge-based Matching), mens værdien 2 helt sikkert ville være et sikkert valg.
| Niveau 0 | Niveau 1 | Niveau 2 | Niveau 3 | Niveau 4 | |
|---|---|---|---|---|---|
| Grayscale-based Matching (diagPatternPyramid): |
 |
 |
 |
 |
 |
| Kantbaseret matchning (diagEdgePyramid): |
 |
 |
 |
 |
 |
Angle Range
Parametrene inMinAngle, inMaxAngle bestemmer det område af skabelonorienteringer, der vil blive taget i betragtning i matchningsprocessen. For eksempel (værdierne i parentes repræsenterer parrene af inMinAngle- og inMaxAngle-værdier):
- (0.0, 360.0): Alle rotationer tages i betragtning (standardværdi)
- (-15.0, 15.0): Skabelonforekomsterne må højst afvige fra referenceskabelonens orientering med 15,0 grader (i hver retning)
- (0.0, 0.0): det forventes, at skabelonernes forekomster bevarer referenceskabelonens orientering
En stor række af mulige orienteringer medfører et betydeligt overhead (både i form af hukommelsesforbrug og beregningstid), så det er tilrådeligt at begrænse området, når det er muligt.
Indstillinger for detektion af kanter (kun kantbaseret matchning)
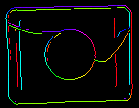
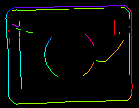
Parametrene inEdgeMagnitudeThreshold, inEdgeHysteresis i CreateEdgeModel-filteret bestemmer indstillingerne for den hysteresetærskel, der bruges til at detektere kanter i skabelonbilledet. Jo lavere inEdgeMagnitudeThreshold-værdien er, jo flere kanter vil blive registreret i skabelonbilledet. Disse parametre bør indstilles således, at alle de signifikante kanter i skabelonen registreres, og at mængden af overflødige kanter (støj) i resultatet er så begrænset som muligt. På samme måde som pyramidehøjden bør tærskelværdierne for kantdetektion vælges gennem interaktive eksperimenter ved hjælp af det diagnostiske output diagEdgePyramid – denne gang skal vi kun se på billedet på det laveste niveau.
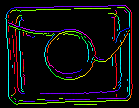 |
 |
 |
|
|
(15.0, 30.0) – overdreven meget støj |
(40.0, 60.0) – OK |
(60.0, 70.0) – signifikante kanter tabt |
Filteret CreateEdgeModel tillader ikke, at der oprettes en model, hvor der ikke er fundet nogen kanter i toppen af pyramiden (hvilket betyder, at ikke kun nogle signifikante kanter er tabt, men alle), hvilket giver en fejl i et sådant tilfælde. Når det sker, skal pyramidens højde eller kanttærsklerne eller begge dele reduceres.
Matching
Parameteren inMinScore bestemmer, hvor eftergivende algoritmen vil være i verifikationen af matchkandidaterne – jo højere værdi, jo færre resultater vil blive returneret. Denne parameter bør indstilles ved interaktiv eksperimentering til en værdi, der er lav nok til at sikre, at alle korrekte matches returneres, men ikke meget lavere, da en for lav værdi gør algoritmen langsommere og kan medføre, at der vises falske matches i resultaterne.
Tips og bedste praksis
Hvordan vælges en metode?
For langt de fleste applikationer vil den kantbaserede matchningsmetode være både mere robust og mere effektiv end den gråskala-baserede matchningsmetode. Sidstnævnte bør kun overvejes, hvis den skabelon, der overvejes, har glatte farveovergangsområder, der ikke er defineret af tydelige kanter, men som stadig skal matches.
| Forrige: Shape Fitting | Næste: Lokale koordinatsystemer |