Jesteś tutaj:Start „Przewodnik po wizji maszynowej „Dopasowywanie szablonów
Wprowadzenie

Dopasowywanie szablonów jest wysokopoziomową techniką wizji maszynowej, która identyfikuje elementy na obrazie pasujące do wcześniej zdefiniowanego szablonu. Zaawansowane algorytmy dopasowywania szablonów pozwalają na znalezienie wystąpień szablonu niezależnie od ich orientacji i lokalnej jasności.
Techniki dopasowywania szablonów są elastyczne i stosunkowo proste w użyciu, co czyni je jednymi z najpopularniejszych metod lokalizacji obiektów. Ich zastosowanie jest ograniczone głównie przez dostępną moc obliczeniową, ponieważ identyfikacja dużych i złożonych szablonów może być czasochłonna.
Koncepcja
Techniki dopasowywania szablonów mają odpowiedzieć na następującą potrzebę: mając obraz referencyjny obiektu (obraz szablonu) i obraz do zbadania (obraz wejściowy) chcemy zidentyfikować wszystkie lokalizacje obrazu wejściowego, w których występuje obiekt z obrazu szablonu. W zależności od konkretnego problemu, możemy (lub nie) chcieć zidentyfikować obrócone lub skalowane wystąpienia.
Zaczniemy od demonstracji naiwnej metody Template Matching, która jest niewystarczająca dla rzeczywistych zastosowań, ale ilustruje podstawową koncepcję, z której wywodzą się rzeczywiste algorytmy Template Matching. Następnie wyjaśnimy jak ta metoda jest ulepszana i rozszerzana w zaawansowanych procedurach Grayscale-based Matching i Edge-based Matching.
Naive Template Matching
Wyobraźmy sobie, że będziemy badać obraz wtyczki, a naszym celem jest znalezienie jej pinów. Otrzymujemy obraz szablonu reprezentujący obiekt odniesienia, którego szukamy oraz obraz wejściowy do sprawdzenia.
 |
 |
|
Obraz szablonowy |
Obraz wejściowy |
Właściwe wyszukiwanie przeprowadzimy w dość prosty sposób – ustawimy szablon na obrazie w każdym możliwym miejscu, i za każdym razem będziemy obliczać liczbową miarę podobieństwa pomiędzy szablonem a segmentem obrazu, na który się on aktualnie nakłada. Na koniec zidentyfikujemy te pozycje, które dają najlepsze miary podobieństwa jako prawdopodobne wystąpienia szablonu.
Korelacja obrazów
Jednym z podproblemów występujących w powyższej specyfikacji jest obliczenie miary podobieństwa wyrównanego obrazu szablonu i nałożonego na niego segmentu obrazu wejściowego, co jest równoważne obliczeniu miary podobieństwa dwóch obrazów o jednakowych wymiarach. Jest to klasyczne zadanie, a numeryczna miara podobieństwa obrazu jest zwykle nazywana korelacją obrazu.
Korelacja krzyżowa
| Obraz1 | Obraz2 | KorelacjaKorelacja |
|---|---|---|
|
 |
19404780 |
|
 |
23316890 |
|
 |
24715810 |
Podstawową metodą obliczania korelacji obrazu jest tzw. korelacja krzyżowa.korelacja, która w istocie jest prostą sumą iloczynów parami odpowiadających sobie wartości pikseli obrazów.
Chociaż możemy zauważyć, że wartość korelacji rzeczywiście wydaje się odzwierciedlać podobieństwo porównywanych obrazów, metoda korelacji krzyżowej jest daleka od solidności. Jej główną wadą jest to, że jest zniekształcona przez zmiany w globalnej jasności obrazów – rozjaśnienie obrazu może spowodować gwałtowny wzrost jego korelacji krzyżowej z innym obrazem, nawet jeśli ten drugi obraz nie jest w ogóle podobny.
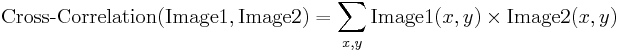
Normalized Cross-Correlation
| Image1 | Image2 | NCC |
|---|---|---|
|
|
-0.417 |
|
|
0.553 |
|
|
0.844 |
Normalizowana korelacja krzyżowa jest ulepszoną wersją klasycznej metody korelacji krzyżowej, która wprowadza dwa ulepszenia w stosunku do oryginalnej metody:
- Wyniki są niezmienne na globalne zmiany jasności, tj.tzn. konsekwentne rozjaśnianie lub przyciemnianie każdego z obrazów nie ma wpływu na wynik (jest to osiągane przez odjęcie średniej jasności obrazu od wartości każdego piksela).
- Końcowa wartość korelacji jest skalowana do zakresu, tak że NCC dwóch identycznych obrazów równa się 1.0, podczas gdy NCC obrazu i jego negacji równa się -1.0.
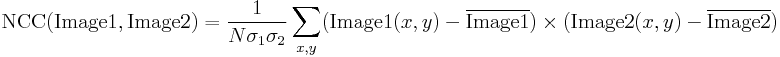
Template Correlation Image
Powróćmy do omawianego problemu. Po wprowadzeniu znormalizowanej korelacji krzyżowej – solidnej miary podobieństwa obrazu – jesteśmy w stanie określić, jak dobrze szablon pasuje do każdej z możliwych pozycji. Wyniki możemy przedstawić w postaci obrazu, gdzie jasność każdego piksela reprezentuje wartość NCC szablonu umieszczonego nad tym pikselem (czarny kolor reprezentuje minimalną korelację -1.0, biały kolor reprezentuje maksymalną korelację 1.0).
|
|
 |
|
Obraz szablonu |
Obraz wejściowy |
Obraz korelacji szablonu |
Identyfikacja dopasowań
Wszystko, co należy zrobić w tym momencie, to zdecydować, które punkty obrazu korelacji szablonów są wystarczająco dobre, aby uznać je za rzeczywiste dopasowania. Zazwyczaj identyfikujemy jako dopasowania pozycje, które (jednocześnie) reprezentują korelację szablonu:
- silniejszą niż pewna predefiniowana wartość progowa (np. silniejsza niż 0.5)
- lokalnie maksymalna (silniejsza niż korelacja szablonu w sąsiednich pikselach)
 |
 |
 |
|
Obszary korelacji szablonu powyżej 0.75 |
Punkty lokalnie maksymalnej korelacji szablonów |
Punkty lokalnie maksymalnej korelacji szablonów powyżej 0.75 |
Podsumowanie
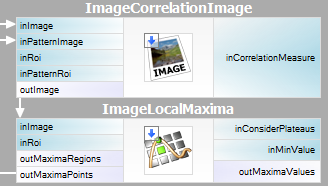
Dość łatwo jest wyrazić opisaną metodę w Adaptive Vision Studio – wystarczą nam dwa wbudowane filtry. Obliczymy obraz korelacji szablonu za pomocą filtra ImageCorrelationImage, a następnie zidentyfikujemy dopasowania za pomocą ImageLocalMaxima – wystarczy ustawić parametr inMinValue, który odetnie słabe maksima lokalne od wyników, co zostało omówione w poprzednim rozdziale.
Chociaż wprowadzona technika była wystarczająca do rozwiązania rozważanego problemu, możemy zauważyć jej istotne wady:
- Występowanie szablonów musi zachowywać orientację obrazu szablonu referencyjnego.
- Metoda jest nieefektywna, gdyż obliczanie obrazu korelacji szablonu dla średnich i dużych obrazów jest czasochłonne.
W kolejnych podrozdziałach omówimy jak te problemy są rozwiązywane w zaawansowanych technikach dopasowywania szablonów: Grayscale-based Matching oraz Edge-based Matching.
Grayscale-based Matching, Edge-based Matching
Grayscale-based Matching to zaawansowany algorytm dopasowywania szablonów, który rozszerza oryginalną ideę detekcji szablonów opartej na korelacji zwiększając jej efektywność i pozwalając na wyszukiwanie wystąpień szablonu niezależnie od jego orientacji. Edge-based Matching jeszcze bardziej ulepsza tę metodę poprzez ograniczenie obliczeń do obszarów krawędzi obiektu.
W tym rozdziale opiszemy wewnętrzne szczegóły obu algorytmów. W następnej sekcji (Filter toolset) wyjaśnimy, jak używać tych technik w Adaptive Vision Studio.
Image Pyramid
Image Pyramid to seria obrazów, z których każdy jest wynikiem downsamplingu (skalowania w dół, w tym przypadku o współczynnik dwa) poprzedniego elementu.
|
 |
 |
|
Poziom 0 (obraz wejściowy) |
Poziom 1 |
Poziom 2 |
Przetwarzanie piramid
Piramidy obrazów mogą być zastosowane w celu zwiększenia efektywności wykrywania szablonów opartego na korelacji.opartej na korelacji. Ważną obserwacją jest to, że szablon przedstawiony na obrazie referencyjnym zazwyczaj jest nadal dostrzegalny po znacznym zmniejszeniu próbkowania obrazu (choć, oczywiście, drobne szczegóły są tracone w tym procesie). Dlatego możemy zidentyfikować kandydatów do dopasowania w downsamplowanym (a więc znacznie szybciej przetwarzanym) obrazie na najwyższym poziomie naszej piramidy, a następnie powtórzyć wyszukiwanie na niższych poziomach piramidy, za każdym razem biorąc pod uwagę tylko te pozycje szablonu, które uzyskały wysoki wynik na poprzednim poziomie.
Na każdym poziomie piramidy będziemy potrzebowali odpowiednio downsamplowanego obrazu szablonu referencyjnego, tj. zarówno piramida obrazu wejściowego jak i piramida obrazu szablonu powinny być obliczone.
 |
 |
 |
|
Poziom 0 (obraz referencyjny szablonu) |
Poziom 1 |
Poziom 2 |
Grayscale-based Matching
Chociaż w niektórych zastosowaniach orientacja obiektów jest jednolita i stała (jak widzieliśmy w przykładzie z wtyczką), często zdarza się, że obiekty, które mają być wykryte, są obrócone. W algorytmach Template Matching klasyczne przeszukiwanie piramid jest przystosowane do umożliwienia dopasowania pod wieloma kątami, tj. identyfikacji obróconych instancji szablonu.
Osiąga się to poprzez obliczenie nie tylko jednej piramidy obrazu szablonu, ale zestawu piramid – po jednej dla każdego możliwego obrotu szablonu. Podczas przeszukiwania piramidy na obrazie wejściowym algorytm identyfikuje pary (pozycja szablonu, orientacja szablonu), a nie same pozycje szablonów. Podobnie jak w przypadku oryginalnego schematu, na każdym poziomie wyszukiwania algorytm weryfikuje tylko te pary (pozycja, orientacja), które uzyskały dobry wynik na poprzednim poziomie (tj. wydawały się pasować do szablonu na obrazie o niższej rozdzielczości).
 |
 |
|
|
Obraz wzorcowy |
Obraz wejściowy |
Wyniki dopasowania wielodopasowania kątowego |
Technika dopasowania piramidowego wraz z wyszukiwaniem wielokątowym stanowią metodę Grayscale-based Template Matching.
Dopasowanie oparte na krawędziach
Dopasowanie oparte na krawędziach rozszerza poprzednio omówione Dopasowanie oparte na skali szarości wykorzystując jedną kluczową obserwację – że kształt dowolnego obiektu jest zdefiniowany głównie przez kształt jego krawędzi. Dlatego też, zamiast dopasowywać cały szablon, możemy wyodrębnić jego krawędzie i dopasować tylko pobliskie piksele, unikając w ten sposób zbędnych obliczeń. W typowych zastosowaniach uzyskane przyspieszenie jest zazwyczaj znaczące.
| Pasowanie oparte na skali szarości: | |
 |
 |
|---|---|---|---|
| Pasowanie oparte na krawędziach: |  |
 |
 |
|
Różne rodzaje piramid szablonów stosowanych w algorytmach Template Matching. |
|||
Dopasowanie krawędzi obiektu zamiast obiektu jako całości wymaga niewielkiej modyfikacji oryginalnej metody dopasowania piramidowego: wyobraźmy sobie, że dopasowujemy obiekt o jednolitym kolorze umieszczony na jednolitym tle. Wszystkie piksele krawędzi obiektu miałyby taką samą intensywność i oryginalny algorytm dopasowywałby obiekt wszędzie tam, gdzie jest wystarczająco duży plamka odpowiedniego koloru, a to oczywiście nie jest to, co chcemy osiągnąć. Aby rozwiązać ten problem, w Edge-based Matching to kierunek gradientu (reprezentowany jako kolor w przestrzeni HSV dla celów ilustracyjnych) pikseli krawędzi, a nie ich intensywność, jest dopasowywany.
Zestaw narzędzi filtrów
Adaptive Vision Studio dostarcza zestaw filtrów implementujących zarówno Grayscale-based Matching jak i Edge-based Matching. Lista filtrów znajduje się w sekcji Filtry dopasowania szablonu.
Ponieważ obraz szablonu musi być wstępnie przetworzony przed dopasowaniem piramidowym (musimy obliczyć piramidy obrazu szablonu dla wszystkich możliwych rotacji), algorytmy są podzielone na dwie części:
- Tworzenie modelu – w tym kroku piramidy obrazu szablonu są obliczane, a wyniki są przechowywane w modelu – atomowym obiekcie reprezentującym wszystkie dane potrzebne do uruchomienia dopasowania piramidowego.
- Dopasowywanie – w tym kroku model szablonu jest używany do dopasowania szablonu w obrazie wejściowym.
Taka organizacja przetwarzania umożliwia jednorazowe obliczenie modelu i wielokrotne jego użycie.
Dostępne filtry
Dla obu metod Template Matching zapewnione są dwa filtry, po jednym dla każdego kroku algorytmu.
| Grayscale-based Matching | Edge-based Matching | |
|---|---|---|
| Model Creation: | 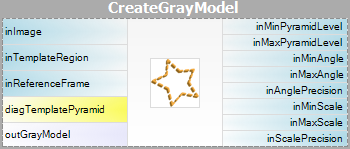 |
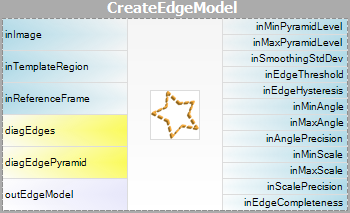 |
| Matching: | 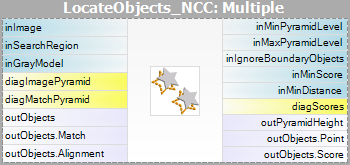 |
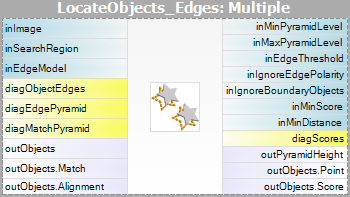 |
Proszę zauważyć, że użycie filtrów CreateGrayModel i CreateEdgeModel będzie konieczne tylko w bardziej zaawansowanych aplikacjach. W innych przypadkach wystarczy użyć pojedynczego filtra kroku Matching i utworzyć model ustawiając parametr inGrayModel lub inEdgeModel tego filtra. Aby uzyskać więcej informacji, zobacz Tworzenie modeli dla Template Matching.
Główne wyzwanie związane z zastosowaniem techniki Template Matching polega raczej na starannym dopasowaniu parametrów filtrów niż na zaprojektowaniu struktury programu.
Schemat zaawansowanych aplikacji
Istnieje kilka rodzajów zaawansowanych aplikacji, dla których interaktywne GUI dla Template Matching nie jest wystarczające i użytkownik musi użyć bezpośrednio filtru CreateGrayModel lub CreateEdgeModel. Na przykład:
- Gdy tworzenie modelu wymaga nietrywialnego wstępnego przetwarzania obrazu.
- Gdy potrzebujemy całej tablicy modeli tworzonych automatycznie na podstawie zestawu obrazów.
- Gdy użytkownik końcowy powinien mieć możliwość definiowania własnych szablonów w aplikacji runtime (np. poprzez dokonanie wyboru na obrazie wejściowym).
Schemat 1: Tworzenie modelu w oddzielnym programie
W przypadkach 1 i 2 zaleca się implementację tworzenia modelu w oddzielnym makrofiltrze Task, zapisanie modelu do pliku AVDATA, a następnie powiązanie tego pliku z wejściem filtru dopasowującego w programie głównym:
| Tworzenie modelu: | Program główny: |
|---|---|
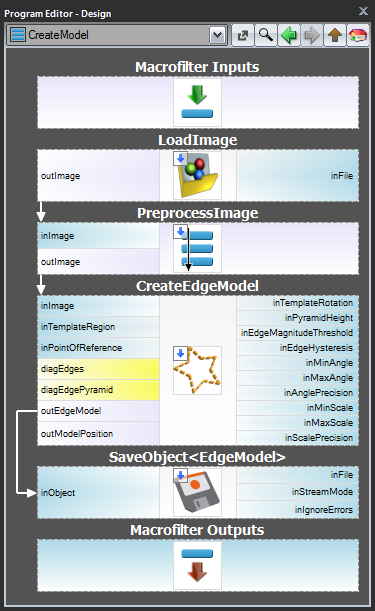 |
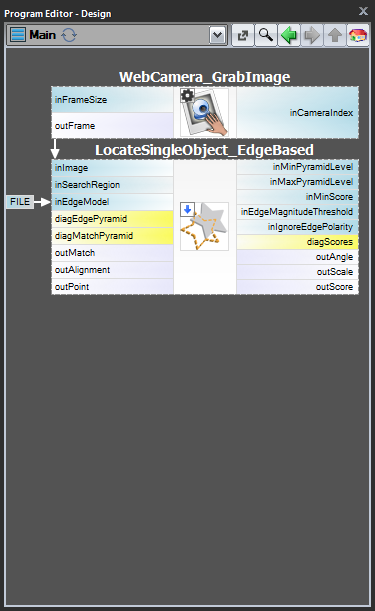 |
Gdy ten program jest gotowy, można uruchomić zadanie „CreateModel” jako program w dowolnym momencie, gdy chcemy odtworzyć model. Link do pliku danych na wejściu filtra dopasowującego nie wymaga wtedy żadnych modyfikacji, ponieważ jest to tylko link, a zmieniany jest tylko plik na dysku.
Schemat 2: Dynamiczne tworzenie modelu
W przypadku 3, gdy model ma być tworzony dynamicznie, zarówno filtr tworzący model, jak i filtr dopasowujący muszą być w tym samym zadaniu. Ten pierwszy powinien być jednak wykonywany warunkowo, po wystąpieniu odpowiedniego zdarzenia HMI (np. kliknięcie przez użytkownika przycisku ImpulseButton lub wykonanie jakiejś akcji myszką w VideoBox). Do reprezentacji modelu należy użyć registerof EdgeModel? type, który będzie przechowywał najnowszy model (inną opcją jest użycie filtra LastNotNil).Oto przykładowa realizacja, w której model jest tworzony z predefiniowanego pola na obrazie wejściowym po kliknięciu przycisku w interfejsie HMI:
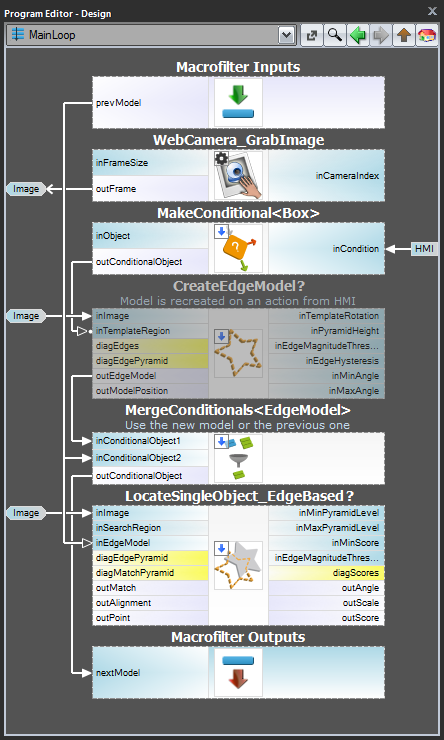
Tworzenie modelu
Wysokość piramidy
Parametr inPyramidHeight określa liczbę poziomów dopasowania piramidy i powinien być ustawiony na największą liczbę, dla której szablon jest jeszcze rozpoznawalny na najwyższym poziomie piramidy. Wartość ta powinna być wybrana poprzez interaktywne eksperymenty przy użyciu wyjścia diagnostycznego diagPatternPyramid (Grayscale-based Matching) lub diagEdgePyramid (Edge-based Matching).
W poniższym przykładzie wartość inPyramidHeight równa 4 byłaby zbyt wysoka (dla obu metod), ponieważ struktura szablonu jest całkowicie utracona na tym poziomie piramidy. Również wartość 3 wydaje się być nieco przesadzona (szczególnie w przypadku Edge-based Matching), podczas gdy wartość 2 byłaby zdecydowanie bezpiecznym wyborem.
| Poziom 0 | Poziom 1 | Poziom 2 | Poziom 3 | Poziom 4 | |
|---|---|---|---|---|---|
| Dopasowanie oparte na skali szarości (diagPatternPyramid): |
 |
 |
 |
 |
 |
| Edge-based Matching (diagEdgePyramid): |
 |
 |
 |
 |
 |
Angle Range
Parametry inMinAngle, inMaxAngle określają zakres orientacji szablonów, które będą brane pod uwagę w procesie dopasowywania. Na przykład (wartości w nawiasach reprezentują pary wartości inMinAngle, inMaxAngle):
- (0.0, 360.0): wszystkie obroty są brane pod uwagę (wartość domyślna)
- (-15.0, 15.0): wystąpienia szablonu mogą odchylać się od orientacji szablonu odniesienia co najwyżej o 15.0 stopni (w każdym kierunku)
- (0.0, 0.0): oczekuje się, że wystąpienia szablonu zachowają orientację szablonu odniesienia
Szeroki zakres możliwych orientacji wprowadza znaczny narzut (zarówno w zużyciu pamięci, jak i w czasie obliczeń), więc zaleca się ograniczenie zakresu, gdy tylko jest to możliwe.
Ustawienia wykrywania krawędzi (tylko dopasowanie oparte na krawędziach)
Parametry inEdgeMagnitudeThreshold, inEdgeHysteresis filtru CreateEdgeModel określają ustawienia progowania histerezy używanego do wykrywania krawędzi w obrazie szablonu. Im niższa wartość inEdgeMagnitudeThreshold, tym więcej krawędzi zostanie wykrytych na obrazie szablonu. Parametry te powinny być tak ustawione, aby wszystkie istotne krawędzie szablonu zostały wykryte, a ilość nadmiarowych krawędzi (szumów) w wyniku była jak najmniejsza. Podobnie jak wysokość piramidy, progi detekcji krawędzi powinny być dobierane w drodze interaktywnego eksperymentu z wykorzystaniem wyjścia diagnostycznego diagEdgePyramid – tym razem musimy przyjrzeć się tylko obrazowi na najniższym poziomie.
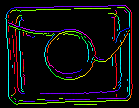 |
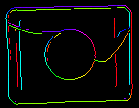 |
 |
|
(15.0, 30.0) – nadmierna ilość szumu |
(40.0, 60.0) – OK |
(60.0, 70.0) – znaczące krawędzie utracone |
Filtr CreateEdgeModel nie pozwoli na utworzenie modelu, w którym na szczycie piramidy nie wykryto żadnych krawędzi (czyli utracono nie tylko niektóre znaczące krawędzie, ale wszystkie), generując w takim przypadku błąd. W takim przypadku należy zmniejszyć wysokość piramidy lub progi krawędziowe, lub jedno i drugie.
Matching
Parametr inMinScore określa, jak bardzo pobłażliwy będzie algorytm w weryfikacji kandydatów na dopasowanie – im wyższa wartość, tym mniej wyników będzie zwracanych. Parametr ten powinien być ustawiony poprzez interaktywne eksperymenty na wartość wystarczająco niską, aby zapewnić, że wszystkie poprawne dopasowania zostaną zwrócone, ale nie dużo niższą, ponieważ zbyt niska wartość spowalnia algorytm i może spowodować, że fałszywe dopasowania pojawią się w wynikach.
Wskazówki i najlepsze praktyki
Jak wybrać metodę?
Dla większości aplikacji metoda Edge-based Matching będzie zarówno bardziej odporna jak i bardziej wydajna niż Grayscale-based Matching. Ta ostatnia powinna być rozważana tylko wtedy, gdy rozważany szablon ma gładkie obszary przejścia kolorów, które nie są zdefiniowane przez dostrzegalne krawędzie, ale mimo to powinny być dopasowane.
| Previous: Shape Fitting | Next: Lokalne układy współrzędnych |
.