U bent hier:Start “Machine Vision Gids “Template Matching
Inleiding

Template Matching is een machine vision-techniek op hoog niveau die de onderdelen op een afbeelding identificeert die overeenkomen met een vooraf gedefinieerde template. Geavanceerde template matching algoritmen maken het mogelijk om voorkomens van het template te vinden, ongeacht hun oriëntatie en lokale helderheid.
Template Matching technieken zijn flexibel en relatief eenvoudig te gebruiken, waardoor ze een van de meest populaire methoden voor object lokalisatie zijn. Hun toepasbaarheid wordt vooral beperkt door de beschikbare rekenkracht, omdat identificatie van grote en complexe sjablonen tijdrovend kan zijn.
Concept
Template Matching technieken worden geacht in de volgende behoefte te voorzien: voorzien van een referentiebeeld van een object (het sjabloonbeeld) en een te inspecteren beeld (het invoerbeeld) willen we alle invoerbeeldlocaties identificeren waarop het object uit het sjabloonbeeld aanwezig is. Afhankelijk van het specifieke probleem willen we de geroteerde of geschaalde voorkomens identificeren (of niet).
We beginnen met een demonstratie van een naïeve Template Matching methode, die ontoereikend is voor toepassingen in het echte leven, maar die het kernconcept illustreert waaruit de eigenlijke Template Matching algoritmen voortkomen. Daarna zullen we uitleggen hoe deze methode wordt verbeterd en uitgebreid in geavanceerde Grayscale-based Matching en Edge-based Matching routines.
Naive Template Matching
Stel je voor dat we een afbeelding van een stekker gaan inspecteren en ons doel is om de pinnen te vinden. We krijgen een sjabloonafbeelding van het referentieobject dat we zoeken en de invoerafbeelding die we moeten inspecteren.
 |
 |
|
Sjabloonafbeelding |
Invoerafbeelding |
We zullen de eigenlijke zoekactie op een tamelijk eenvoudige manier uitvoeren – we zullen de sjabloon op elke mogelijke plaats over de afbeelding plaatsen, en elke keer berekenen we een numerieke maat van overeenkomst tussen het sjabloon en het beeldsegment waar het op dat moment mee overlapt. Tenslotte zullen we de posities identificeren die de beste similariteitsmaatstaven opleveren als de waarschijnlijke template occurrences.
Image Correlation
Een van de subproblemen die in de bovenstaande specificatie voorkomen is het berekenen van de similariteitsmaatstaf van het uitgelijnde template-beeld en het overlappende segment van het invoerbeeld, wat equivalent is aan het berekenen van een similariteitsmaatstaf van twee beelden van gelijke afmetingen. Dit is een klassieke taak, en een numerieke maat voor de gelijkenis van afbeeldingen wordt gewoonlijk beeldcorrelatie genoemd.
Cross-Correlation
| Image1 | Image2 | Cross-Correlatie |
|---|---|---|
|
 |
19404780 |
|
 |
23316890 |
|
 |
24715810 |
De fundamentele methode om de beeldcorrelatie te berekenen is de zgn. cross-correlatie, die in wezen een eenvoudige som is van paarsgewijze vermenigvuldigingen van overeenkomstige pixelwaarden van de beelden.
Hoewel we kunnen opmerken dat de correlatiewaarde inderdaad de gelijkenis van de vergeleken beelden lijkt weer te geven, is de cross-correlatie methode verre van robuust. Het grootste nadeel is dat de methode wordt beïnvloed door veranderingen in de globale helderheid van de beelden – als een beeld helderder wordt, kan de correlatie met een ander beeld sterk toenemen, zelfs als het tweede beeld helemaal niet vergelijkbaar is.
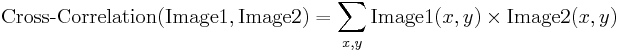
Normalized Cross-Correlation
| Image1 | Image2 | NCC |
|---|---|---|
|
|
-0.417 |
|
|
0.553 |
|
|
0.844 |
Genormaliseerde kruiscorrelatie is een verbeterde versie van de klassieke kruiscorrelatiemethode die twee verbeteringen introduceert ten opzichte van de oorspronkelijke:
- De resultaten zijn invariant ten opzichte van de globale helderheidsveranderingen, d.w.z.d.w.z. consequent helderder of donkerder maken van beide beelden heeft geen effect op het resultaat (dit wordt bereikt door de gemiddelde beeldhelderheid af te trekken van elke pixelwaarde).
- De uiteindelijke correlatiewaarde wordt geschaald naar bereik, zodat NCC van twee identieke beelden gelijk is aan 1.0, terwijl NCC van een beeld en zijn negatie gelijk is aan -1.0.
Template Correlation Image
Laten we teruggaan naar het probleem waar we mee te maken hebben. Nu we de genormaliseerde kruiscorrelatie hebben ingevoerd – een robuuste maatstaf voor de gelijkenis tussen afbeeldingen – kunnen we bepalen hoe goed het sjabloon in elk van de mogelijke posities past. Wij kunnen de resultaten weergeven in de vorm van een afbeelding, waarbij de helderheid van elke pixel de NCC-waarde vertegenwoordigt van het sjabloon dat over deze pixel is geplaatst (de zwarte kleur vertegenwoordigt de minimale correlatie van -1,0, de witte kleur de maximale correlatie van 1,0).
|
|
 |
|
Template afbeelding |
Input afbeelding |
Template correlatie afbeelding |
Identificatie van matches
Het enige dat nu nog moet gebeuren, is beslissen welke punten van de template correlatie-afbeelding goed genoeg zijn om als echte matches te worden beschouwd. Gewoonlijk identificeren we als matches de posities die (gelijktijdig) de template correlatie weergeven:
- sterker dat een vooraf gedefinieerde drempelwaarde (d.w.z. sterker dat 0.5)
- lokaal maximaal (sterker dan de template correlatie in de naburige pixels)
 |
 |
 |
|
Zones van template correlatie boven 0.75 |
Punten van lokaal maximale template correlatie |
Punten van lokaal maximale template correlatie boven 0.75 |
Samenvatting
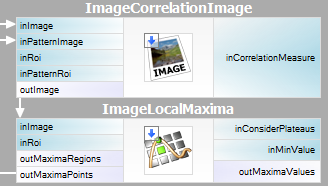
Het is vrij eenvoudig om de beschreven methode in Adaptive Vision Studio uit te voeren – we hebben slechts twee ingebouwde filters nodig. We berekenen het sjablooncorrelatiebeeld met het filter ImageCorrelationImage en identificeren vervolgens de overeenkomsten met ImageLocalMaxima – we hoeven alleen maar de parameter inMinValue in te stellen, waarmee de zwakke lokale maxima uit de resultaten worden verwijderd, zoals in het vorige gedeelte is besproken.
Hoewel de geïntroduceerde techniek voldoende was om het beschouwde probleem op te lossen, kunnen we de belangrijke nadelen ervan opmerken:
- Template occurrences moeten de oriëntatie van het referentie-sjabloonbeeld behouden.
- De methode is inefficiënt, omdat het berekenen van het sjabloon-correlatiebeeld voor middelgrote tot grote beelden tijdrovend is.
In de volgende secties zullen we bespreken hoe deze problemen worden aangepakt in geavanceerde technieken voor sjabloonmatching: Grayscale-based Matching en Edge-based Matching.
Grayscale-based Matching, Edge-based Matching
Grayscale-based Matching is een geavanceerd sjabloonmatching-algoritme dat het oorspronkelijke idee van correlatiegebaseerde sjabloondetectie uitbreidt, waardoor de efficiëntie wordt verbeterd en naar sjabloonvoorkomens kan worden gezocht, ongeacht de oriëntatie. Edge-based Matching verbetert deze methode nog meer door de berekening te beperken tot de randgebieden van het object.
In deze sectie zullen we de intrinsieke details van beide algoritmen beschrijven. In de volgende sectie (Filter toolset) zullen we uitleggen hoe deze technieken in Adaptive Vision Studio gebruikt kunnen worden.
Image Pyramid
Image Pyramid is een serie afbeeldingen, waarbij elke afbeelding het resultaat is van downsampling (schalen, met de factor twee in dit geval) van het vorige element.
|
 |
 |
|
Level 0 (invoerafbeelding) |
Level 1 |
Level 2 |
Pyramideverwerking
Image piramides kunnen worden toegepast om de efficiëntie van de correlatie-gebaseerde template detectie. De belangrijke observatie is dat het sjabloon dat in het referentiebeeld is afgebeeld, gewoonlijk nog steeds kan worden onderscheiden na aanzienlijke downsampling van het beeld (hoewel natuurlijk fijne details verloren gaan in het proces). Daarom kunnen we op het hoogste niveau van onze piramide kandidaten voor een match identificeren in het gedownsamplede (en dus veel sneller te verwerken) beeld, en vervolgens de zoektocht herhalen op de lagere niveaus van de piramide, waarbij we telkens alleen de sjabloonposities in aanmerking nemen die op het vorige niveau hoog scoorden.
Op elk niveau van de piramide hebben we een adequaat gedownsampled beeld van het referentiesjabloon nodig, d.w.z. zowel de invoerbeeldpiramide als de sjabloonbeeldpiramide moeten worden berekend.
 |
 |
 |
|
Level 0 (sjabloon referentiebeeld) |
Level 1 |
Level 2 |
Grayscale-based Matching
Hoewel in sommige toepassingen de oriëntatie van de objecten uniform en vast is (zoals we hebben gezien in het stekkervoorbeeld), is het vaak zo dat de objecten die moeten worden gedetecteerd, gedraaid lijken. In Template Matching algoritmen wordt de klassieke piramide-zoekopdracht aangepast om multi-angle matching mogelijk te maken, d.w.z. identificatie van geroteerde instanties van het sjabloon.
Dit wordt bereikt door niet slechts één sjabloonbeeldpiramide te berekenen, maar een reeks piramiden – één voor elke mogelijke rotatie van het sjabloon. Tijdens het zoeken naar de piramide op het invoerbeeld identificeert het algoritme de paren (sjabloonpositie, sjabloonoriëntatie) in plaats van alleen de sjabloonposities. Net als bij het oorspronkelijke schema controleert het algoritme op elk zoekniveau alleen de (positie, oriëntatie) paren die op het vorige niveau goed scoorden (d.w.z. leken overeen te komen met het sjabloon in het beeld met lagere resolutie).
 |
 |
|
|
Template-afbeelding |
Input-afbeelding |
Resultaten van multi-hoekvergelijking |
De techniek van piramidevergelijking vormt samen met het zoeken onder meerdere hoeken de op grijswaarden gebaseerde methode voor sjabloonvergelijking.
Edge-based Matching
Edge-based Matching verbetert de eerder besproken Grayscale-based Matching met behulp van één cruciale observatie – dat de vorm van een object voornamelijk wordt bepaald door de vorm van de randen. In plaats van het gehele sjabloon te matchen, kunnen we dus de randen extraheren en alleen de nabijgelegen pixels matchen, waardoor enkele onnodige berekeningen worden vermeden. In gewone toepassingen is de bereikte snelheid meestal aanzienlijk.
| Grayscale-based Matching: | |
 |
 |
|---|---|---|---|
| Edge-based Matching: |  |
 |
 |
|
Verschillende soorten sjabloonpiramides die in sjabloonmatchingalgoritmen worden gebruikt. |
|||
Het matchen van objectranden in plaats van een object in zijn geheel vereist een kleine wijziging van de oorspronkelijke pyramide-matchingsmethode: stel dat we een object met een uniforme kleur matchen dat zich op een uniforme achtergrond bevindt. Alle pixels aan de randen van het object zouden dezelfde intensiteit hebben en het originele algoritme zou het object overal matchen waar er een voldoende grote klodder van de juiste kleur is, en dit is duidelijk niet wat we willen bereiken. Om dit probleem op te lossen, wordt bij Edge-based Matching de gradiëntrichting (ter illustratie weergegeven als een kleur in HSV-ruimte) van de randpixels gematcht, en niet hun intensiteit.
Filter Toolset
Adaptive Vision Studio biedt een set filters waarmee zowel Grayscale-gebaseerde Matching als Edge-gebaseerde Matching wordt geïmplementeerd. Voor de lijst van filters zie Template Matching filters.
Aangezien het template beeld moet worden voorbewerkt voor de pyramide matching (we moeten de template beeldpiramides berekenen voor alle mogelijke rotaties), zijn de algoritmes opgesplitst in twee delen:
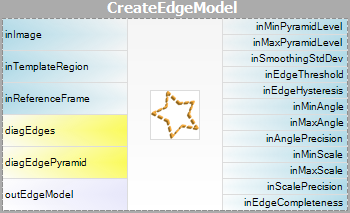
- Model Creatie – in deze stap worden de template beeldpiramides berekend en de resultaten worden opgeslagen in een model – atomair object dat alle gegevens weergeeft die nodig zijn om de pyramide matching uit te voeren.
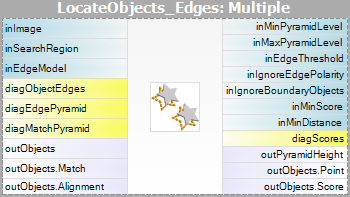
- Matching – in deze stap wordt het sjabloonmodel gebruikt om het sjabloon in het invoerbeeld te matchen.
Een dergelijke organisatie van de verwerking maakt het mogelijk om het model eenmaal te berekenen en het meerdere malen te hergebruiken.
Beschikbare filters
Voor beide Template Matching methoden zijn twee filters beschikbaar, een voor elke stap van het algoritme.
| Grayscale-based Matching | Edge-based Matching | |
|---|---|---|
| Model Creation: | 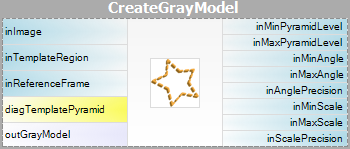 |
 |
| Matching: | 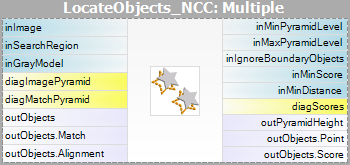 |
 |
Merk op dat het gebruik van de filters CreateGrayModel en CreateEdgeModel alleen nodig zal zijn in meer geavanceerde toepassingen. Anders is het voldoende om een enkel filter van de Matching stap te gebruiken en het model te maken door de inGrayModel of inEdgeModel parameter van het filter in te stellen. Zie voor meer informatie Creating Models for Template Matching.
De grootste uitdaging bij het toepassen van de Template Matching techniek ligt in het zorgvuldig afstellen van de filterparameters, en niet zozeer in het ontwerpen van de programmastructuur.
Advanced Application Schema
Er zijn verschillende soorten geavanceerde toepassingen, waarvoor de interactieve GUI voor Template Matching niet voldoende is en de gebruiker het filter CreateGrayModel of CreateEdgeModel rechtstreeks moet gebruiken. Bijvoorbeeld:
- Wanneer het maken van het model niet-triviale beeldvoorbewerking vereist.
- Wanneer we een hele reeks modellen nodig hebben die automatisch worden gemaakt van een set afbeeldingen.
- Wanneer de eindgebruiker in staat moet zijn om zijn eigen sjablonen te definiëren in de runtime toepassing (b.v. door een selectie te maken op een invoer afbeelding).
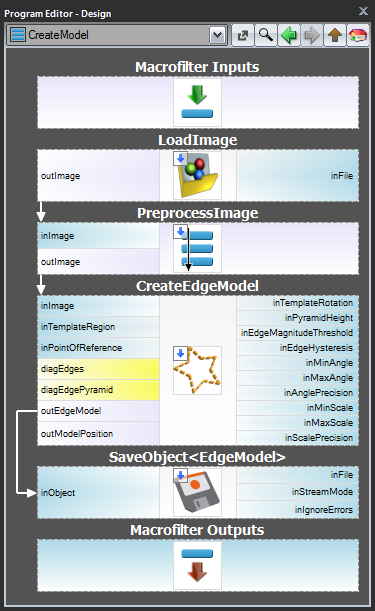
Schema 1: Modelcreatie in een apart programma
Voor de gevallen 1 en 2 is het raadzaam om de modelcreatie in een apart Task macrofilter uit te voeren, het model op te slaan in een AVDATA bestand en dat bestand vervolgens te koppelen aan de invoer van het bijbehorende filter in het hoofdprogramma:
| Modelcreatie: | Hoofdprogramma: |
|---|---|
 |
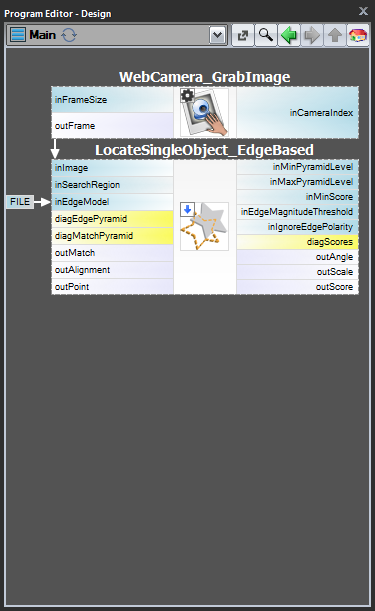 |
Wanneer dit programma klaar is, kunt u de “CreateModel”-taak als een programma uitvoeren op elk moment dat u het model wilt maken. De koppeling naar het gegevensbestand op de invoer van het matching filter behoeft dan geen wijzigingen, omdat dit slechts een koppeling is en alleen het bestand op schijf wordt gewijzigd.
Schema 2: Dynamische modelcreatie
Voor geval 3, wanneer het model dynamisch moet worden gemaakt, moeten zowel het modelcreatie filter als het matching filter in dezelfde taak zitten. De eerste taak moet echter voorwaardelijk worden uitgevoerd, wanneer een HMI-gebeurtenis optreedt (b.v. wanneer de gebruiker op een ImpulseButton klikt of een muisactie in een VideoBox uitvoert). Voor de weergave van het model moet een register van het type EdgeModel? worden gebruikt, dat het laatste model zal opslaan (een andere optie is het gebruik van het LastNotNil filter).Hier volgt een voorbeeld waarbij het model wordt gecreëerd vanuit een voorgedefinieerd vak op een invoerafbeelding wanneer op een knop wordt geklikt in de HMI:
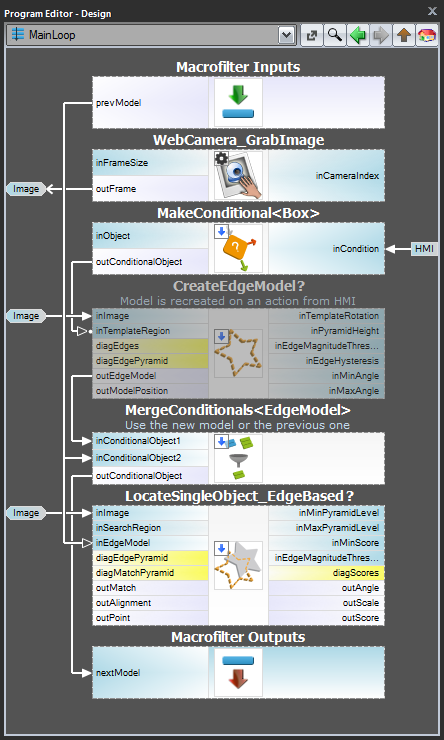
Modelcreatie
Hoogte van de piramide
De parameter inPyramidHeight bepaalt het aantal niveaus van de overeenkomende piramide en moet worden ingesteld op het grootste aantal waarvoor het sjabloon nog herkenbaar is op het hoogste piramideniveau. Deze waarde moet worden gekozen door interactief experimenteren met behulp van de diagnostische uitvoer diagPatternPyramid (Grayscale-based Matching) of diagEdgePyramid (Edge-based Matching).
In het volgende voorbeeld zou de waarde inPyramidHeight van 4 te hoog zijn (voor beide methoden), aangezien de structuur van het sjabloon op dit niveau van de piramide geheel verloren gaat. Ook de waarde van 3 lijkt een beetje overdreven (vooral in het geval van Edge-based Matching) terwijl de waarde van 2 zeker een veilige keuze zou zijn.
| Level 0 | Level 1 | Level 2 | Level 3 | Level 4 | |
|---|---|---|---|---|---|
| Grayscale-based Matching (diagPatternPyramid): |
 |
 |
 |
 |
 |
| Edge-based Matching (diagEdgePyramid): |
 |
 |
 |
 |
 |
Angle Range
De parameters inMinAngle en inMaxAngle bepalen het bereik van de sjabloonoriëntaties die bij het matchen in aanmerking worden genomen. Bijvoorbeeld (waarden tussen haakjes vertegenwoordigen de paren van inMinAngle, inMaxAngle waarden):
- (0.0, 360.0): alle rotaties worden beschouwd (standaard waarde)
- (-15.0, 15.0): de template voorkomens mogen maximaal 15.0 graden afwijken van de referentie sjabloon oriëntatie (in elke richting)
- (0.0, 0., 0.0): de template voorkomens mogen maximaal 15.0 graden afwijken van de referentie sjabloon oriëntatie (in elke richting).0): er wordt verwacht dat de sjabloonvoorkomens de oriëntatie van het referentiesjabloon behouden
Een groot bereik van mogelijke oriëntaties introduceert een aanzienlijke hoeveelheid overhead (zowel in geheugengebruik als in rekentijd), dus het is raadzaam om het bereik waar mogelijk te beperken.
Edge Detection Settings (alleen Edge-based Matching)
De parameters inEdgeMagnitudeThreshold en inEdgeHysteresis van het filter CreateEdgeModel bepalen de instellingen van de hysteresis-drempel die wordt gebruikt voor het detecteren van randen in het sjabloonbeeld. Hoe lager de waarde inEdgeMagnitudeThreshold, hoe meer randen zullen worden gedetecteerd in het sjabloonbeeld. Deze parameters moeten zo worden ingesteld dat alle significante randen van het sjabloon worden gedetecteerd en dat de hoeveelheid overbodige randen (ruis) in het resultaat zo beperkt mogelijk is. Net als bij de piramidehoogte moeten de drempels voor randdetectie worden geselecteerd door middel van interactieve experimenten met behulp van de diagnostische uitvoer diagEdgePyramid – deze keer moeten we alleen kijken naar het beeld op het laagste niveau.
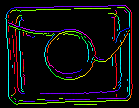 |
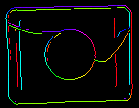 |
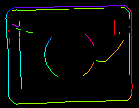 |
|
(15.0, 30.0) – overmatige hoeveelheid ruis |
(40.0, 60.0) – OK |
(60.0, 70.0) – significante randen verloren |
De filter CreateEdgeModel staat niet toe dat een model wordt gemaakt waarin geen randen zijn gedetecteerd aan de top van de piramide (wat betekent dat niet alleen enkele significante randen verloren zijn gegaan, maar alle), wat in zo’n geval een fout oplevert. Wanneer dat gebeurt, moet de hoogte van de piramide, of de randdrempels, of beide, worden verlaagd.
Matching
De parameter inMinScore bepaalt hoe toegeeflijk het algoritme zal zijn bij de verificatie van de match-kandidaten – hoe hoger de waarde, hoe minder resultaten zullen worden teruggegeven. Deze parameter moet door interactieve experimenten op een waarde worden ingesteld die laag genoeg is om er zeker van te zijn dat alle juiste matches worden geretourneerd, maar niet veel lager, omdat een te lage waarde het algoritme vertraagt en kan leiden tot valse matches in de resultaten.
Tips en beste praktijken
Hoe selecteer ik een methode?
Voor verreweg de meeste toepassingen zal de Edge-based Matching-methode zowel robuuster als efficiënter zijn dan de Grayscale-gebaseerde Matching. De laatste methode moet alleen worden overwogen als het sjabloon vloeiende kleurovergangen heeft die niet door waarneembare randen worden gedefinieerd, maar toch moeten worden gematcht.
| Vorige: Vormaanpassing | Volgende: Lokale coördinatenstelsels |