Voi sunteți aici:Acasă:Start „Ghid de mașini de vizionare „Potrivirea șablonului
Introducere

Încadrarea șablonului este o tehnică de vizionare automată de nivel înalt care identifică părțile dintr-o imagine care se potrivesc cu un șablon predefinit. Algoritmii avansați de potrivire a șabloanelor permit găsirea aparițiilor șablonului indiferent de orientarea și luminozitatea locală a acestora.
Tehnicile de potrivire a șabloanelor sunt flexibile și relativ simplu de utilizat, ceea ce le face una dintre cele mai populare metode de localizare a obiectelor. Aplicabilitatea lor este limitată în principal de puterea de calcul disponibilă, deoarece identificarea șabloanelor mari și complexe poate consuma mult timp.
Concept
Se așteaptă ca tehnicile de potrivire a șabloanelor să răspundă următoarei nevoi: având la dispoziție o imagine de referință a unui obiect (imaginea șablon) și o imagine care urmează să fie inspectată (imaginea de intrare), dorim să identificăm toate locațiile imaginii de intrare în care este prezent obiectul din imaginea șablon. În funcție de problema specifică pe care o avem la îndemână, putem dori (sau nu) să identificăm prezențele rotite sau scalate.
Vom începe cu o demonstrație a unei metode naive de potrivire a șabloanelor, care este insuficientă pentru aplicațiile din viața reală, dar care ilustrează conceptul de bază din care derivă algoritmii actuali de potrivire a șabloanelor. După aceea vom explica modul în care această metodă este îmbunătățită și extinsă în cadrul rutinelor avansate Grayscale-based Matching și Edge-based Matching.
Naive Template Matching
Imaginați-vă că vom inspecta imaginea unei prize și că scopul nostru este de a găsi pinii acesteia. Ni se pune la dispoziție o imagine șablon care reprezintă obiectul de referință pe care îl căutăm și imaginea de intrare care urmează să fie inspectată.
 |
 |
|
Imaginea șablon |
Imaginea de intrare |
Vom efectua căutarea propriu-zisă într-un mod destul de simplu – vom poziționa șablonul peste imagine în fiecare locație posibilă, și de fiecare dată vom calcula o măsură numerică de similaritate între șablon și segmentul de imagine cu care se suprapune în prezent. În cele din urmă, vom identifica pozițiile care produc cele mai bune măsuri de similaritate ca fiind aparițiile probabile ale șablonului.
Corelația imaginilor
Una dintre subproblemele care apar în specificația de mai sus este calcularea măsurii de similaritate a imaginii șablon aliniate și a segmentului suprapus al imaginii de intrare, care este echivalentă cu calcularea unei măsuri de similaritate a două imagini de dimensiuni egale. Aceasta este o sarcină clasică, iar măsura numerică a similitudinii imaginilor se numește de obicei corelație de imagine.
Corelație încrucișată
| Imagine1 | Imagine2 | Corelație încrucișată-.Corelație |
|---|---|---|
|
 |
19404780 |
|
 |
23316890 |
|
 |
24715810 |
Metoda fundamentală de calcul a corelației imaginii este așa-numita corelație încrucișată.corelație, care, în esență, este o simplă sumă de înmulțiri pe perechi a valorilor pixelilor corespunzători din imagini.
Deși putem observa că valoarea corelației pare într-adevăr să reflecte similaritatea imaginilor comparate, metoda corelației încrucișate este departe de a fi robustă. Principalul său dezavantaj este că este influențată de schimbările de luminozitate globală a imaginilor – luminozitatea unei imagini poate crește vertiginos corelația încrucișată cu o altă imagine, chiar dacă cea de-a doua imagine nu este deloc similară.
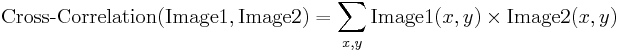
Corelația încrucișată normalizată
| Imaginea1 | Imaginea2 | NCC |
|---|---|---|
|
|
-0.417 |
|
|
0.553 |
|
|
0,844 |
Corelația încrucișată normalizată este o versiune îmbunătățită a metodei clasice de corelație încrucișată care introduce două îmbunătățiri față de cea originală:
- Rezultatele sunt invariante la schimbările globale de luminozitate, i.e.adică luminarea sau întunecarea consecventă a oricăreia dintre imagini nu are niciun efect asupra rezultatului (acest lucru se realizează prin scăderea luminozității medii a imaginii din valoarea fiecărui pixel).
- Valoarea finală a corelației este scalată în funcție de interval, astfel încât NCC a două imagini identice este egală cu 1,0, în timp ce NCC a unei imagini și a negației sale este egală cu -1,0.
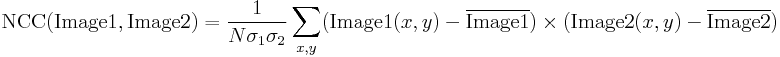
Template Imagine de corelație
Să ne întoarcem la problema de față. După ce am introdus corelația încrucișată normalizată – măsură robustă de similaritate a imaginii – suntem acum capabili să determinăm cât de bine se potrivește șablonul în fiecare dintre pozițiile posibile. Putem reprezenta rezultatele sub forma unei imagini, în care luminozitatea fiecărui pixel reprezintă valoarea NCC a șablonului poziționat pe acest pixel (culoarea neagră reprezintă corelația minimă de -1,0, iar culoarea albă reprezintă corelația maximă de 1,0).
|
|
 |
|
|
Imaginea șablonului |
Imaginea de intrare |
Imaginea de corelație a șablonului |
Imaginea de corelație a șablonului |
Identificarea corespondențelor
Tot ce trebuie făcut în acest moment este să se decidă ce puncte din imaginea de corelare a șablonului sunt suficient de bune pentru a fi considerate corespondențe reale. De obicei, identificăm ca fiind potriviri pozițiile care reprezintă (simultan) corelația șablon:
- mai puternică decât o anumită valoare de prag predefinită (adică mai puternică decât 0.5)
- maximă la nivel local (mai puternică decât corelația șablonului în pixelii vecini)
 |
 |
 |
|
Zone de corelație a șablonului peste 0.75 |
Puncte de corelație maximă locală a șabloanelor |
Puncte de corelație maximă locală a șabloanelor peste 0,75 |
Rezumat
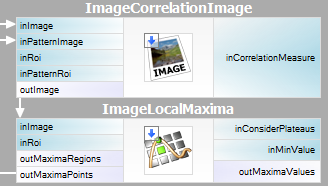
Este destul de ușor de exprimat metoda descrisă în Adaptive Vision Studio – vom avea nevoie doar de două filtre încorporate. Vom calcula imaginea de corelație a șablonului folosind filtrul ImageCorrelationImage, iar apoi vom identifica potrivirile folosind ImageLocalMaxima – trebuie doar să setăm parametrul inMinValue care va tăia maximele locale slabe din rezultate, așa cum am discutat în secțiunea anterioară.
Chiar dacă tehnica introdusă a fost suficientă pentru a rezolva problema avută în vedere, putem remarca dezavantajele sale importante:
- Oparițiile șablonului trebuie să păstreze orientarea imaginii șablon de referință.
- Metoda este ineficientă, deoarece calcularea imaginii de corelație a șablonului pentru imagini de dimensiuni medii și mari consumă mult timp.
În secțiunile următoare vom discuta modul în care aceste probleme sunt abordate în tehnicile avansate de potrivire a șabloanelor: Grayscale-based Matching și Edge-based Matching.
Grayscale-based Matching, Edge-based Matching
Grayscale-based Matching este un algoritm avansat de potrivire a șabloanelor care extinde ideea originală de detectare a șabloanelor pe bază de corelație, sporindu-i eficiența și permițând căutarea aparițiilor șabloanelor indiferent de orientarea lor. Edge-based Matching îmbunătățește și mai mult această metodă prin limitarea calculului la zonele de margine ale obiectului.
În această secțiune vom descrie detaliile intrinseci ale ambilor algoritmi. În secțiunea următoare (Filter toolset) vom explica cum să folosim aceste tehnici în Adaptive Vision Studio.
Image Pyramid
Image Pyramid este o serie de imagini, fiecare imagine fiind rezultatul unei eșantionări (micșorări, cu un factor de doi în acest caz) a elementului anterior.
|
 |
 |
|
Nivelul 0 (imagine de intrare) |
Nivelul 1 |
Nivelul 2 |
Prelucrarea piramidală
Piramidele de imagine pot fi aplicate pentru a spori eficiența corelației-.detecției șablonului bazată pe corelație. Observația importantă este că șablonul descris în imaginea de referință este, de obicei, încă perceptibil după o reducere semnificativă a eșantionării imaginii (deși, în mod natural, detaliile fine se pierd în acest proces). Prin urmare, putem identifica candidații de potrivire în imaginea cu eșantionare redusă (și, prin urmare, mult mai rapid de procesat) la cel mai înalt nivel al piramidei noastre și apoi să repetăm căutarea la nivelurile inferioare ale piramidei, de fiecare dată luând în considerare doar pozițiile șablonului care au obținut scoruri ridicate la nivelul anterior.
La fiecare nivel al piramidei vom avea nevoie de o imagine cu eșantionare redusă corespunzătoare a șablonului de referință, adică trebuie calculate atât piramida imaginii de intrare, cât și piramida imaginii șablon.
 |
 |
 |
|
Nivelul 0 (imaginea de referință a șablonului) |
Nivelul 1 |
Nivelul 2 |
Grayscale-based Matching
Deși în unele dintre aplicații orientarea obiectelor este uniformă și fixă (așa cum am văzut în exemplul cu fișa), se întâmplă adesea ca obiectele care trebuie detectate să apară rotite. În algoritmii de potrivire a șabloanelor, căutarea clasică a piramidei este adaptată pentru a permite potrivirea multiunghiulară, adică identificarea instanțelor rotite ale șablonului.
Acest lucru se realizează prin calcularea nu doar a unei piramide a imaginii șablonului, ci a unui set de piramide – una pentru fiecare rotație posibilă a șablonului. În timpul căutării piramidei pe imaginea de intrare, algoritmul identifică perechile (poziția șablonului, orientarea șablonului) mai degrabă decât pozițiile unice ale șablonului. În mod similar schemei originale, la fiecare nivel de căutare, algoritmul verifică numai acele perechi (poziție, orientare) care au obținut rezultate bune la nivelul anterior (adică păreau să se potrivească cu șablonul din imaginea cu rezoluție mai mică).
 |
 |
|
|
Imaginea șablon |
Imaginea de intrare |
Rezultate ale multi-unghiuri de potrivire |
Tehnica de potrivire piramidală împreună cu căutarea multi-unghiulară constituie metoda de potrivire a șabloanelor bazată pe scala de griuri.
Edge-based Matching
Edge-based Matching îmbunătățește metoda Grayscale-based Matching discutată anterior folosind o observație crucială – aceea că forma oricărui obiect este definită în principal de forma marginilor sale. Prin urmare, în loc să potrivim întregul șablon, am putea extrage marginile acestuia și să potrivim doar pixelii din apropiere, evitând astfel unele calcule inutile. În aplicațiile obișnuite, creșterea de viteză obținută este, de obicei, semnificativă.
| Potrivire bazată pe scala de gri: | |
 |
 |
|---|---|---|---|
| Potrivire bazată pe margini: |  |
 |
 |
|
Diferite tipuri de piramide de șabloane utilizate în algoritmii de potrivire a șabloanelor. |
|||
Încadrarea marginilor obiectului în loc de un obiect ca întreg necesită o ușoară modificare a metodei originale de potrivire a piramidelor: imaginați-vă că potrivim un obiect de culoare uniformă poziționat pe un fundal uniform. Toți pixelii marginilor obiectului ar avea aceeași intensitate, iar algoritmul original ar potrivi obiectul oriunde ar exista o pată suficient de mare de culoarea corespunzătoare, ceea ce, în mod clar, nu este ceea ce dorim să obținem. Pentru a rezolva această problemă, în Edge-based Matching se potrivește direcția de gradient (reprezentată ca o culoare în spațiul HSV în scop ilustrativ) a pixelilor de margine, nu intensitatea lor.
Filter Toolset
Adaptive Vision Studio oferă un set de filtre care implementează atât Grayscale-based Matching cât și Edge-based Matching. Pentru lista filtrelor, consultați Template Matching filters.
Pentru că imaginea șablon trebuie preprocesată înainte de potrivirea piramidală (trebuie să calculăm piramidele imaginii șablon pentru toate rotațiile posibile), algoritmii sunt împărțiți în două părți:
- Model Creation – în această etapă se calculează piramidele imaginii șablon și rezultatele sunt stocate într-un model – obiect atomic care reprezintă toate datele necesare pentru a executa potrivirea piramidală.
- Potrivire – în această etapă, modelul de șablon este utilizat pentru a potrivi șablonul din imaginea de intrare.
O astfel de organizare a prelucrării face posibilă calcularea modelului o singură dată și refolosirea lui de mai multe ori.
Filtre disponibile
Pentru ambele metode de potrivire a șabloanelor sunt prevăzute două filtre, câte unul pentru fiecare etapă a algoritmului.
| Grayscale-based Matching | Edge-based Matching | |
|---|---|---|
| Crearea modelului: |  |
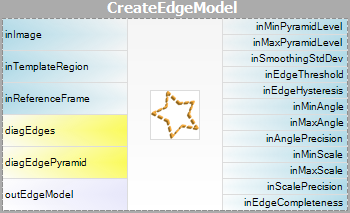 |
| Matching: | 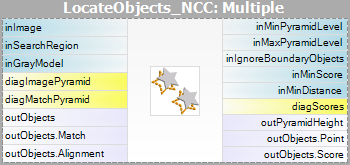 |
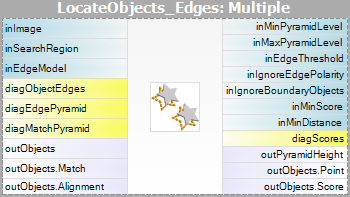 |
Rețineți că utilizarea filtrelor CreateGrayModel și CreateEdgeModel va fi necesară numai în aplicații mai avansate. În caz contrar, este suficient să se utilizeze un singur filtru al etapei de potrivire și să se creeze modelul prin setarea parametrului inGrayModel sau inEdgeModel al filtrului. Pentru mai multe informații, a se vedea Crearea de modele pentru Template Matching.
Principala provocare a aplicării tehnicii Template Matching constă în ajustarea atentă a parametrilor filtrelor, mai degrabă decât în proiectarea structurii programului.
Schema aplicațiilor avansate
Există mai multe tipuri de aplicații avansate, pentru care interfața grafică interactivă pentru Template Matching nu este suficientăși utilizatorul trebuie să utilizeze direct filtrul CreateGrayModel sau CreateEdgeModel. De exemplu:
- Când crearea modelului necesită o preprocesare netrivială a imaginii.
- Când avem nevoie de o întreagă serie de modele create automat dintr-un set de imagini.
- Când utilizatorul final ar trebui să aibă posibilitatea de a-și defini propriile șabloane în aplicația de execuție (de exemplu, prin efectuarea unei selecții pe o imagine de intrare).
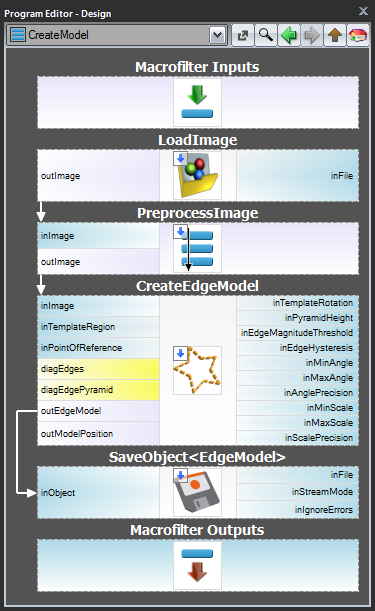
Schema 1: Crearea modelului într-un program separat
Pentru cazurile 1 și 2 este recomandabil să se implementeze crearea modelului într-un macrofiltru Task separat,să se salveze modelul într-un fișier AVDATA și apoi să se lege acest fișier la intrarea filtrului de potrivire în programul principal:
| Crearea modelului: | Programul principal: |
|---|---|
 |
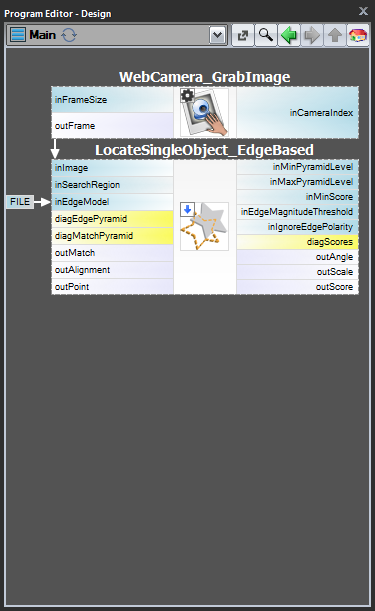 |
Când acest program este gata, puteți rula sarcina „CreateModel” ca program în orice moment în care doriți să creați modelul. Legătura cu fișierul de date de la intrarea filtrului de potrivire nu are nevoie atunci de modificări, deoarece este doar o legătură și ceea ce se modifică este doar fișierul de pe disc.
Schema 2: Crearea dinamică a modelului
Pentru cazul 3, când modelul trebuie creat în mod dinamic, atât filtrul de creare a modelului, cât și filtrul de potrivire trebuie să fie în aceeași sarcină. Cu toate acestea, primul ar trebui să fie executat condiționat, atunci când se declanșează un eveniment HMI respectiv (de exemplu, utilizatorul face clic pe un ImpulseButton sau efectuează o acțiune cu mouse-ul într-un VideoBox). Pentru reprezentarea modelului, trebuie utilizat un registru de tip „registerof EdgeModel?”, care va stoca cel mai recent model (o altă opțiune este utilizarea filtrului LastNotNil).Iată un exemplu de realizare în care modelul este creat dintr-o casetă predefinită pe o imagine de intrare atunci când se face clic pe un buton în HMI:
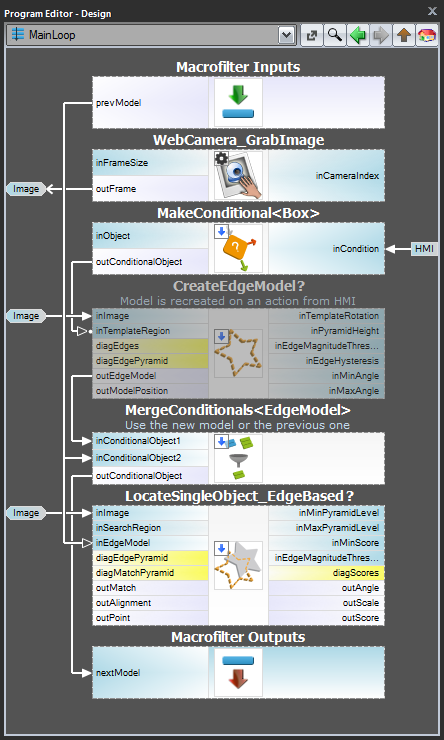
Model Creation
Height of the Pyramid
Parametrul inPyramidHeight determină numărul de niveluri de potrivire a piramidei și trebuie setat la cel mai mare număr pentru care șablonul este încă recognoscibil pe cel mai înalt nivel al piramidei. Această valoare ar trebui să fie selectată prin experimentare interactivă cu ajutorul ieșirii de diagnosticare diagPatternPyramid (Grayscale-based Matching) sau diagEdgePyramid (Edge-based Matching).
În exemplul următor, valoarea inPyramidHeight de 4 ar fi prea mare (pentru ambele metode), deoarece structura șablonului este complet pierdută la acest nivel al piramidei. De asemenea, valoarea de 3 pare un pic excesivă (mai ales în cazul potrivirii bazate pe muchii), în timp ce valoarea de 2 ar fi cu siguranță o alegere sigură.
| Nivelul 0 | Nivelul 1 | Nivelul 2 | Nivelul 3 | Nivelul 4 | |
|---|---|---|---|---|---|
| Grayscale-based Matching (diagPatternPyramid): |
 |
 |
 |
 |
 |
| Edge-based Matching (diagEdgePyramid): |
 |
 |
 |
 |
 |
Angle Range
Parametrii inMinAngle, inMaxAngle determină intervalul de orientări ale șablonului care vor fi luate în considerare în procesul de potrivire. De exemplu (valorile între paranteze reprezintă perechile de valori inMinAngle, inMaxAngle):
- (0.0, 360.0): se iau în considerare toate rotațiile (valoare implicită)
- (-15.0, 15.0): se permite ca aparițiile șablonului să devieze de la orientarea șablonului de referință cu cel mult 15.0 grade (în fiecare direcție)
- (0.0, 0.0): se așteaptă ca aparițiile șablonului să păstreze orientarea șablonului de referință
O gamă largă de orientări posibile introduce o cantitate semnificativă de costuri suplimentare (atât în ceea ce privește utilizarea memoriei, cât și timpul de calcul), astfel încât este recomandabil să se limiteze gama ori de câte ori este posibil.
Edge Detection Settings (only Edge-based Matching)
Parametrii inEdgeMagnitudeThreshold, inEdgeHysteresis ai filtrului CreateEdgeModel determină setările pragului de histerezis utilizat pentru detectarea marginilor în imaginea șablon. Cu cât valoarea inEdgeMagnitudeThreshold este mai mică, cu atât mai multe muchii vor fi detectate în imaginea șablon. Acești parametri trebuie setați astfel încât toate marginile semnificative ale șablonului să fie detectate, iar cantitatea de margini redundante (zgomot) din rezultat să fie cât mai limitată posibil. În mod similar înălțimii piramidei, pragurile de detectare a marginilor ar trebui selectate prin experimentare interactivă cu ajutorul ieșirii de diagnosticare diagEdgePyramid – de data aceasta trebuie să ne uităm doar la imaginea de la cel mai mic nivel.
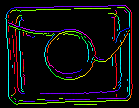 |
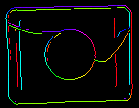 |
 |
|
|
(15.0, 30.0) – cantitate excesivă de zgomot |
(40.0, 60.0) – OK |
(60.0, 70.0) – muchii semnificative pierdute |
Filtrul CreateEdgeModel nu va permite crearea unui model în care nu au fost detectate muchii în vârful piramidei (ceea ce înseamnă că nu doar unele muchii semnificative au fost pierdute, ci toate), producând o eroare în acest caz. Ori de câte ori se întâmplă acest lucru, trebuie redusă înălțimea piramidei, pragurile marginilor sau ambele.
Matching
Parametrul inMinScore determină cât de permisiv va fi algoritmul în verificarea candidaților de potrivire – cu cât valoarea este mai mare, cu atât mai puține rezultate vor fi returnate. Acest parametru ar trebui să fie setat, prin experimentare interactivă, la o valoare suficient de mică pentru a se asigura că toate corespondențele corecte vor fi returnate, dar nu mult mai mică, deoarece o valoare prea mică încetinește algoritmul și poate cauza apariția unor corespondențe false în rezultate.
Tips and Best Practices
Cum se selectează o metodă?
Pentru marea majoritate a aplicațiilor, metoda Edge-based Matching va fi atât mai robustă, cât și mai eficientă decât Grayscale-based Matching. Aceasta din urmă ar trebui luată în considerare numai dacă șablonul luat în considerare are zone de tranziție lină a culorilor care nu sunt definite de muchii perceptibile, dar care totuși trebuie să fie potrivite.
| Anterior: Shape Fitting | Succesor: Shape Fitting | Next: Sisteme de coordonate locale |
.