Itt van:Start “Machine Vision Guide “Sablonillesztés
Bevezetés

A sablonillesztés egy magas szintű gépi látási technika, amely egy képen azonosítja azokat a részeket, amelyek egy előre meghatározott sablonra illeszkednek. A fejlett sablonillesztési algoritmusok lehetővé teszik a sablon előfordulásainak megtalálását, függetlenül azok tájolásától és helyi fényességétől.
A sablonillesztési technikák rugalmasak és viszonylag egyszerűen használhatók, ami az objektumlokalizáció egyik legnépszerűbb módszerévé teszi őket. Alkalmazhatóságukat leginkább a rendelkezésre álló számítási teljesítmény korlátozza, mivel a nagy és összetett sablonok azonosítása időigényes lehet.
Koncepció
A sablonillesztési technikák a következő igényt hivatottak kielégíteni: egy tárgyról készült referenciakép (a sablonkép) és egy vizsgálandó kép (a bemeneti kép) birtokában szeretnénk azonosítani az összes olyan bemeneti képi helyet, ahol a sablonképen szereplő tárgy jelen van. Az adott problémától függően a forgatott vagy méretezett előfordulásokat is azonosítani akarjuk (vagy nem).
Egy naiv sablonillesztési módszer bemutatásával kezdjük, amely a valós alkalmazásokhoz nem elegendő, de szemlélteti azt az alapkoncepciót, amelyből a tényleges sablonillesztési algoritmusok erednek. Ezután elmagyarázzuk, hogy ezt a módszert hogyan javítjuk és bővítjük a fejlett szürkeárnyalat-alapú illesztési és él-alapú illesztési rutinokban.
Naiv sablonillesztés
Tegyük fel, hogy egy dugó képét fogjuk megvizsgálni, és a célunk az, hogy megtaláljuk a csapjait. Kapunk egy sablonképet, amely a keresett referenciaobjektumot ábrázolja, és a vizsgálandó bemeneti képet.
 |
 |
|
Sablonkép |
Bemeneti kép |
A tényleges keresést meglehetősen egyszerű módon fogjuk elvégezni – a sablont minden lehetséges helyen a kép fölé helyezzük, és minden egyes alkalommal kiszámítjuk a sablon és az éppen átfedésben lévő képszegmens közötti hasonlóság valamilyen numerikus mértékét. Végül azonosítjuk azokat a pozíciókat, amelyek a legjobb hasonlósági mértéket adják, mint a sablon valószínű előfordulási helyeit.
Képi korreláció
A fenti specifikációban előforduló egyik részprobléma az igazított sablonkép és a bemeneti kép átfedésben lévő szegmensének hasonlósági mértékének kiszámítása, ami egyenértékű két azonos dimenziójú kép hasonlósági mértékének kiszámításával. Ez egy klasszikus feladat, és a kép hasonlóságának numerikus mértékét általában képi korrelációnak nevezik.
Keresztkorreláció
| Image1 | Image2 | Kereszt-Korreláció |
|---|---|---|
|
 |
19404780 |
|
 |
23316890 |
|
 |
24715810 |
A képi korreláció számításának alapvető módszere az ún. kereszt-korreláció.korreláció, amely lényegében a képek megfelelő pixelértékeinek páros szorzatainak egyszerű összege.
Noha észrevehetjük, hogy a korrelációs érték valóban tükrözni látszik az összehasonlított képek hasonlóságát, a keresztkorrelációs módszer korántsem robusztus. Fő hátránya, hogy a képek globális fényerősségének változása torzítja – egy kép fényesedése az egekbe emelheti a keresztkorrelációját egy másik képpel, még akkor is, ha a második kép egyáltalán nem hasonló.
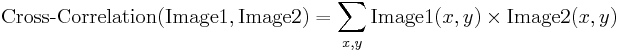
Normalizált keresztkorreláció
| Image1 | Image2 | NCC |
|---|---|---|
|
|
-0.417 |
|
|
0.553 |
|
|
0.844 |
A normált keresztkorreláció a klasszikus keresztkorrelációs módszer továbbfejlesztett változata, amely két fejlesztést vezet be az eredeti módszerhez képest:
- Az eredmények invariánsak a globális fényességváltozásra, ill.azaz egyik kép következetes világosodása vagy sötétedése sincs hatással az eredményre (ezt úgy érjük el, hogy az egyes pixelértékekből kivonjuk a kép átlagos fényességét).
- A végső korrelációs értéket tartományra skálázzuk, így két azonos kép NCC-je 1,0, míg egy kép és annak negációja NCC-je -1,0.
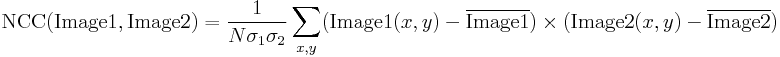
Minta korrelációs kép
Kanyarodjunk vissza az adott problémához. Miután bevezettük a normalizált keresztkorrelációt – a kép hasonlóságának robusztus mértékét -, most már meg tudjuk határozni, hogy a sablon mennyire illik az egyes lehetséges pozíciókba. Az eredményeket egy kép formájában ábrázolhatjuk, ahol az egyes pixelek fényessége az adott pixel fölé pozícionált sablon NCC-értékét jelenti (a fekete szín a -1,0 minimális korrelációt, a fehér szín az 1,0 maximális korrelációt jelenti).
|
|
 |
|
|
Sablonkép |
Bemeneti kép |
Sablon korrelációs kép |
Sablon korrelációs kép |
Egyezések azonosítása
Előre csak azt kell eldönteni, hogy a sablonkorrelációs kép mely pontjai elég jók ahhoz, hogy tényleges egyezéseknek tekinthetők. Általában azokat a pozíciókat azonosítjuk egyezésként, amelyek (egyidejűleg) a sablonkorrelációt:
- erősebbek, mint valamilyen előre meghatározott küszöbérték (azaz erősebbek, mint 0.5)
- lokálisan maximális (erősebb, mint a szomszédos pixelek sablonkorrelációja)
 |
 |
 |
|
A 0 feletti sablonkorrelációjú területek.75 |
A lokálisan maximális sablonkorreláció pontjai |
A 0,75 feletti lokálisan maximális sablonkorreláció pontjai |
Összefoglaló
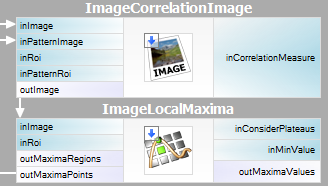
A leírt módszert az Adaptive Vision Studio-ban elég egyszerű kifejezni – mindössze két beépített szűrőre lesz szükségünk. Az ImageCorrelationImage szűrővel kiszámítjuk a sablon korrelációs képet, majd az ImageLocalMaxima szűrővel azonosítjuk az egyezéseket – csak az inMinValue paramétert kell beállítanunk, amely a gyenge lokális maximumokat vágja ki az eredményekből, ahogy azt az előző részben tárgyaltuk.
Noha a bemutatott technika elegendő volt a vizsgált probléma megoldására, észrevehetjük fontos hátrányait:
- A sablon előfordulásoknak meg kell őrizniük a referencia sablonkép orientációját.
- A módszer nem hatékony, mivel a sablonkorrelációs kép kiszámítása közepes vagy nagyméretű képek esetén időigényes.
A következő fejezetekben azt tárgyaljuk, hogyan kezelik ezeket a problémákat a fejlett sablonillesztési technikák: Grayscale-based Matching és Edge-based Matching.
Grayscale-based Matching, Edge-based Matching
A Grayscale-based Matching egy fejlett sablonillesztési algoritmus, amely kiterjeszti a korreláció-alapú sablonfelismerés eredeti ötletét, növelve annak hatékonyságát, és lehetővé teszi a sablon előfordulásának keresését annak orientációjától függetlenül. Az élalapú illesztés még továbbfejleszti ezt a módszert azáltal, hogy a számítást az objektum élterületeire korlátozza.
Ebben a szakaszban mindkét algoritmus belső részleteit ismertetjük. A következő részben (Szűrő eszköztár) elmagyarázzuk, hogyan használhatjuk ezeket a technikákat az Adaptive Vision Studio-ban.
Képpiramis
A képpiramis egy képsorozat, amelynek minden egyes képe az előző elem lemintavételezésének (kicsinyítésének, ebben az esetben kétszeresére való méretezésnek) az eredménye.
|
 |
 |
|
Szint 0 (bemeneti kép) |
Szint 1 |
2. szint |
Piramisfeldolgozás
Képpiramisok alkalmazhatók a korreláció hatékonyságának növelésére-alapú sablonfelismerés hatékonyságát. Fontos megfigyelés, hogy a referenciaképen ábrázolt sablon általában a kép jelentős lemintavételezése után is felismerhető (bár természetesen a finom részletek elvesznek a folyamat során). Ezért a lemintavételezett (és ezért sokkal gyorsabban feldolgozható) képen a piramisunk legmagasabb szintjén azonosíthatjuk az egyezésjelölteket, majd megismételhetjük a keresést a piramis alacsonyabb szintjein, minden alkalommal csak az előző szinten magas pontszámot elért sablonhelyeket figyelembe véve.
A piramis minden szintjén szükségünk lesz a referencia-sablon megfelelően lemintavételezett képére, azaz a bemeneti képpiramist és a sablonkép-piramist is ki kell számítani.
 |
 |
 |
|
Szint 0 (sablon referenciakép) |
Szint 1 |
Szint 2 |
Grayscale-.based Matching
Bár az alkalmazások egy részében az objektumok orientációja egységes és rögzített (ahogy azt a dugós példában láttuk), gyakran előfordul, hogy az észlelendő objektumok elforgatva jelennek meg. A sablonillesztési algoritmusokban a klasszikus piramiskeresést úgy alakítják át, hogy lehetővé tegyék a többszögű illesztést, azaz a sablon elforgatott példányainak azonosítását.
Ezt úgy érik el, hogy nem csak egy sablonkép-piramist, hanem piramisok halmazát számítják ki – egyet a sablon minden lehetséges elforgatásához. A bemeneti képen végzett piramiskeresés során az algoritmus a sablonpárokat (sablonpozíció, sablonorientáció) azonosítja, nem pedig a kizárólagos sablonpozíciókat. Az eredeti sémához hasonlóan a keresés minden egyes szintjén az algoritmus csak azokat a (pozíció, orientáció) párokat ellenőrzi, amelyek az előző szinten jól szerepeltek (azaz úgy tűnt, hogy megfelelnek a sablonnak az alacsonyabb felbontású képen).
 |
 |
|
|
Sablonkép |
Bemeneti kép |
Eredmények a multi-szögillesztés eredményei |
A piramisillesztés technikája a többszögű kereséssel együtt alkotja a szürkeárnyalat-alapú sablonillesztési módszert.
Széleken alapuló illesztés
A széleken alapuló illesztés a korábban tárgyalt szürkeárnyalat-alapú illesztést egy lényeges megfigyeléssel bővíti, nevezetesen azzal, hogy bármely objektum alakját elsősorban az éleinek alakja határozza meg. Ezért a teljes sablon illesztése helyett kivehetjük az éleit, és csak a közeli pixeleket illeszthetjük össze, így elkerülhetünk néhány felesleges számítást. A gyakori alkalmazásokban az elért sebességnövekedés általában jelentős.
| Grayscale-based Matching: | |
 |
 |
|---|---|---|---|
| Edge-based Matching: |  |
 |
 |
|
A sablonillesztési algoritmusokban használt különböző típusú sablonpiramisok. |
|||
A tárgy éleinek illesztése a tárgy egésze helyett az eredeti piramisillesztési módszer kismértékű módosítását igényli: képzeljük el, hogy egy egységes színű, egységes háttéren elhelyezett tárgyat illesztünk össze. A tárgy összes szélének képpontja azonos intenzitású lenne, és az eredeti algoritmus bárhol megfeleltetné a tárgyat, ahol a megfelelő színű elég nagy folt van, és ez nyilvánvalóan nem az, amit el akarunk érni. E probléma megoldására az élalapú illesztésnél az élpixelek gradiens iránya (a szemléltetés kedvéért színként ábrázolva a HSV-térben), nem pedig intenzitásuk kerül illesztésre.
Szűrőeszközkészlet
Az Adaptive Vision Studio egy sor szűrőt biztosít, amelyek mind a szürkeárnyalat-alapú illesztést, mind az élalapú illesztést megvalósítják. A szűrők listáját lásd: Template Matching filters.
Mivel a sablonképet a piramisillesztés előtt elő kell dolgozni (ki kell számítani a sablonkép piramisait az összes lehetséges forgatásra), az algoritmusok két részre oszlanak:
- Modell létrehozása – ebben a lépésben a sablonkép piramisait kiszámítjuk, és az eredményeket egy modellben tároljuk – atomi objektum, amely a piramisillesztés futtatásához szükséges összes adatot reprezentálja.
- Párosítás – ebben a lépésben a sablonmodell felhasználásra kerül a bemeneti kép sablonjának megfeleltetésére.
A feldolgozás ilyen megszervezése lehetővé teszi a modell egyszeri kiszámítását és többszöri újrafelhasználását.
A rendelkezésre álló szűrők
Mindkét Template Matching módszerhez két szűrő áll rendelkezésre, egy-egy az algoritmus minden egyes lépéséhez.
| Grayscale-based Matching | Edge-based Matching | |
|---|---|---|
| Modell létrehozása: | 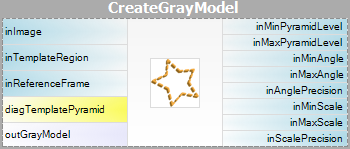 |
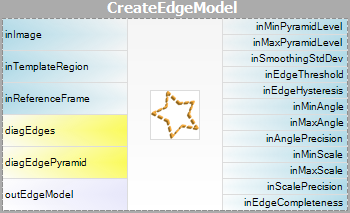 |
| Matching: | 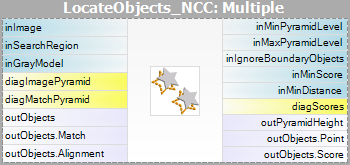 |
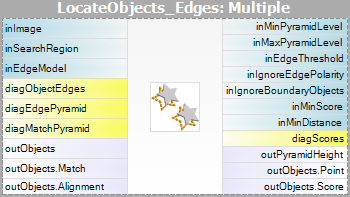 |
Figyelem, hogy a CreateGrayModel és CreateEdgeModel szűrők használatára csak a fejlettebb alkalmazásokban lesz szükség. Egyébként elegendő a Matching lépés egyetlen szűrőjét használni, és a modellt a szűrő inGrayModel vagy inEdgeModel paraméterének beállításával létrehozni. További információért lásd: Modellek létrehozása sablonillesztéshez.
A sablonillesztési technika alkalmazásának fő kihívása a szűrőparaméterek gondos beállításában rejlik, nem pedig a programszerkezet megtervezésében.
Továbbfejlesztett alkalmazásséma
Van többféle továbbfejlesztett alkalmazás, amelyekhez a Sablonillesztés interaktív grafikus felülete nem elegendő, és a felhasználónak közvetlenül a CreateGrayModel vagy CreateEdgeModel szűrőt kell használnia. Például:
- Amikor a modell létrehozása nem triviális képelőfeldolgozást igényel.
- Amikor a képekből automatikusan létrehozott modellek egész sorára van szükségünk.
- Amikor a végfelhasználónak képesnek kell lennie saját sablonjainak meghatározására a futásidejű alkalmazásban (pl. egy bemeneti képen történő kiválasztással).
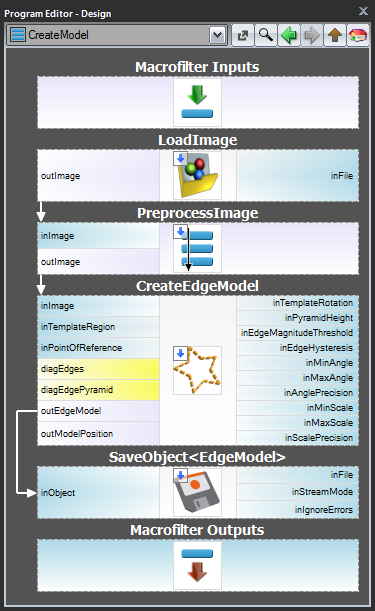
Séma 1: Modellkészítés külön programban
Az 1. és 2. esetben célszerű a modellkészítést külön Task makroszűrőben megvalósítani,a modellt egy AVDATA fájlba menteni, majd ezt a fájlt a főprogramban a megfelelő szűrő bemenetéhez kapcsolni:
| Modellkészítés: | Főprogram: |
|---|---|
 |
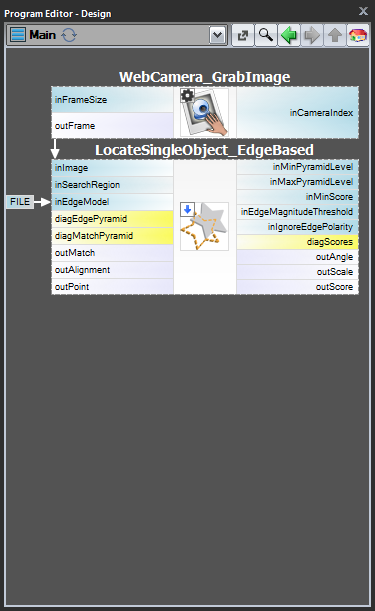 |
Ha ez a program elkészült, a “CreateModel” feladatot programként bármikor futtathatja, amikor a modellt létre kívánja hozni. Az illesztési szűrő bemenetén lévő adatfájlra mutató linket ekkor nem kell módosítani, mert ez csak egy link, és csak a lemezen lévő fájl változik.
Séma 2: Dinamikus modellkészítés
A 3. esetben, amikor a modellt dinamikusan kell létrehozni, a modellkészítő szűrőnek és az illesztési szűrőnek is ugyanabban a feladatban kell lennie. Az előbbit azonban feltételesen kell végrehajtani, amikor egy megfelelő HMI esemény bekövetkezik (pl. a felhasználó rákattint egy ImpulseButton-ra vagy végez valamilyen egérakciót egy VideoBox-on). A modell reprezentálására egy registerof EdgeModel? típust kell használni, amely a legutolsó modellt tárolja (egy másik lehetőség a LastNotNil szűrő használata).Íme egy megvalósítási példa, ahol a modell egy előre definiált dobozból jön létre egy bemeneti képen, amikora gombra kattintunk a HMI-ben:
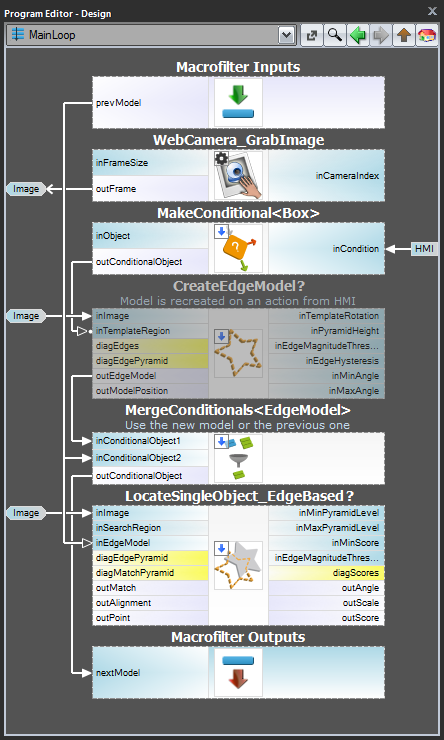
Modell létrehozása
Piramismagasság
Az inPyramidHeight paraméter határozza meg a piramis megfeleltetési szintjeinek számát, és a legnagyobb számra kell beállítani, amelynél a sablon még felismerhető a legmagasabb piramisszinten. Ezt az értéket interaktív kísérletezéssel kell kiválasztani a diagPatternPyramid (szürkeárnyalat-alapú illesztés) vagy a diagEdgePyramid (él-alapú illesztés) diagnosztikai kimenet segítségével.
A következő példában a 4-es inPyramidHeight érték túl magas lenne (mindkét módszer esetében), mivel a sablon szerkezete a piramis ezen szintjén teljesen elveszik. A 3-as érték is kissé túlzónak tűnik (különösen az Edge-based Matching esetében), míg a 2-es érték mindenképpen biztonságos választás lenne.
| Level 0 | Level 1 | Level 2 | Level 3 | Level 4 | |
|---|---|---|---|---|---|
| Grayscale-based Matching (diagPatternPyramid): |
 |
 |
 |
 |
 |
| Edge-alapú illesztés (diagEdgePyramid): |
 |
 |
 |
 |
 |
Angle Range
Az inMinAngle, inMaxAngle paraméterek meghatározzák az illesztés során figyelembe veendő sablonorientációk tartományát. Például (a zárójelben lévő értékek az inMinAngle, inMaxAngle értékpárokat jelentik):
- (0.0, 360.0): minden elforgatást figyelembe veszünk (alapértelmezett érték)
- (-15.0, 15.0): a sablon előfordulása legfeljebb 15.0 fokkal térhet el a referencia sablon orientációjától (minden irányban)
- (0.0, 0.0): A sablon előfordulásoknak meg kell őrizniük a referencia sablon orientációját
A lehetséges orientációk széles tartománya jelentős többletköltséget jelent (mind memóriahasználatban, mind számítási időben), ezért célszerű a tartományt lehetőség szerint korlátozni.
Edge Detection Settings (only Edge-based Matching)
A CreateEdgeModel szűrő inEdgeMagnitudeThreshold, inEdgeHysteresis paraméterei határozzák meg a sablonképben lévő élek felismeréséhez használt hiszterézis küszöbérték beállításait. Minél alacsonyabb az inEdgeMagnitudeThreshold értéke, annál több él kerül felismerésre a sablonképen. Ezeket a paramétereket úgy kell beállítani, hogy a sablon összes jelentős éle felismerésre kerüljön, és a redundáns élek (zaj) mennyisége az eredményben a lehető legkevesebb legyen. A piramis magasságához hasonlóan az élfelismerési küszöbértékeket is interaktív kísérletezéssel kell kiválasztani a diagEdgePyramid diagnosztikai kimenet segítségével – ezúttal csak a kép legalsó szintjét kell megvizsgálnunk.
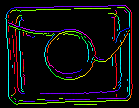 |
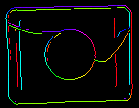 |
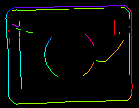 |
|
(15.0, 30.0) – túlzott mértékű zaj |
(40.0, 60.0) – OK |
(60.0, 70.0) – jelentős élek elvesztek |
A CreateEdgeModel szűrő nem engedi olyan modell létrehozását, amelyben a piramis tetején nem észleltek éleket (ami azt jelenti, hogy nem csak néhány jelentős él veszett el, hanem az összes), ilyen esetben hibát eredményez. Ilyenkor a piramis magasságát, vagy az élküszöbértékeket, vagy mindkettőt csökkenteni kell.
Matching
Az inMinScore paraméter határozza meg, hogy az algoritmus mennyire legyen megengedő az egyezésjelöltek ellenőrzésében – minél magasabb az érték, annál kevesebb eredményt ad vissza. Ezt a paramétert interaktív kísérletezéssel olyan alacsony értékre kell beállítani, amely biztosítja, hogy minden helyes találat visszakerüljön, de nem sokkal alacsonyabbra, mivel a túl alacsony érték lelassítja az algoritmust, és hamis találatok jelenhetnek meg az eredményekben.
Tippek és legjobb gyakorlatok
Hogyan válasszunk módszert?
Az alkalmazások túlnyomó többségénél az élalapú párosítási módszer robusztusabb és hatékonyabb lesz, mint a szürkeárnyalat-alapú párosítás. Ez utóbbit csak akkor érdemes megfontolni, ha a vizsgált sablon sima színátmenetű területeket tartalmaz, amelyeket nem határoznak meg jól kivehető élek, de mégis illeszteni kell.
| Előző: Alakillesztés | Következő: Helyi koordinátarendszerek |