
Datatatransformatie is een van de fundamentele stappen in het onderdeel van dataverwerking. Toen ik voor het eerst de techniek van feature scaling leerde, werden de termen scale, standardise, en normalise vaak gebruikt. Het was echter vrij moeilijk om informatie te vinden over welke van hen ik moet gebruiken en ook wanneer te gebruiken. Daarom ga ik in dit artikel de volgende belangrijke aspecten uitleggen:
- het verschil tussen Standardization en Normalisation
- wanneer gebruik je Standardisation en wanneer gebruik je Normalisation
- hoe pas je feature scaling toe in Python
Wat betekent Feature Scaling?
In de praktijk komen we vaak verschillende soorten variabelen tegen in dezelfde dataset. Een belangrijk probleem is dat het bereik van de variabelen sterk kan verschillen. Bij gebruik van de oorspronkelijke schaal kan het gewicht van variabelen met een groot bereik groter zijn. Om dit probleem op te lossen, moeten we de techniek van het herschalen van kenmerken toepassen op onafhankelijke variabelen of kenmerken van gegevens in de fase van de gegevensvoorverwerking. De termen normalisatie en standaardisatie worden soms door elkaar gebruikt, maar gewoonlijk verwijzen ze naar verschillende dingen.
Het doel van het toepassen van Feature Scaling is ervoor te zorgen dat kenmerken op bijna dezelfde schaal liggen, zodat elk kenmerk even belangrijk is en het gemakkelijker te verwerken is door de meeste ML-algoritmen.
Voorbeeld
Dit is een dataset die een onafhankelijke variabele (Gekocht) en 3 afhankelijke variabelen (Land, Leeftijd, en Salaris) bevat. We kunnen gemakkelijk opmerken dat de variabelen niet op dezelfde schaal liggen omdat het bereik van Leeftijd van 27 tot 50 loopt, terwijl het bereik van Salaris van 48 K tot 83 K gaat. Het bereik van Salaris is veel groter dan het bereik van Leeftijd. Dit leidt tot problemen in onze modellen, omdat veel modellen voor machinaal leren, zoals k-means-clustering en nearest neighbour-classificatie, zijn gebaseerd op de Euclidische afstand.
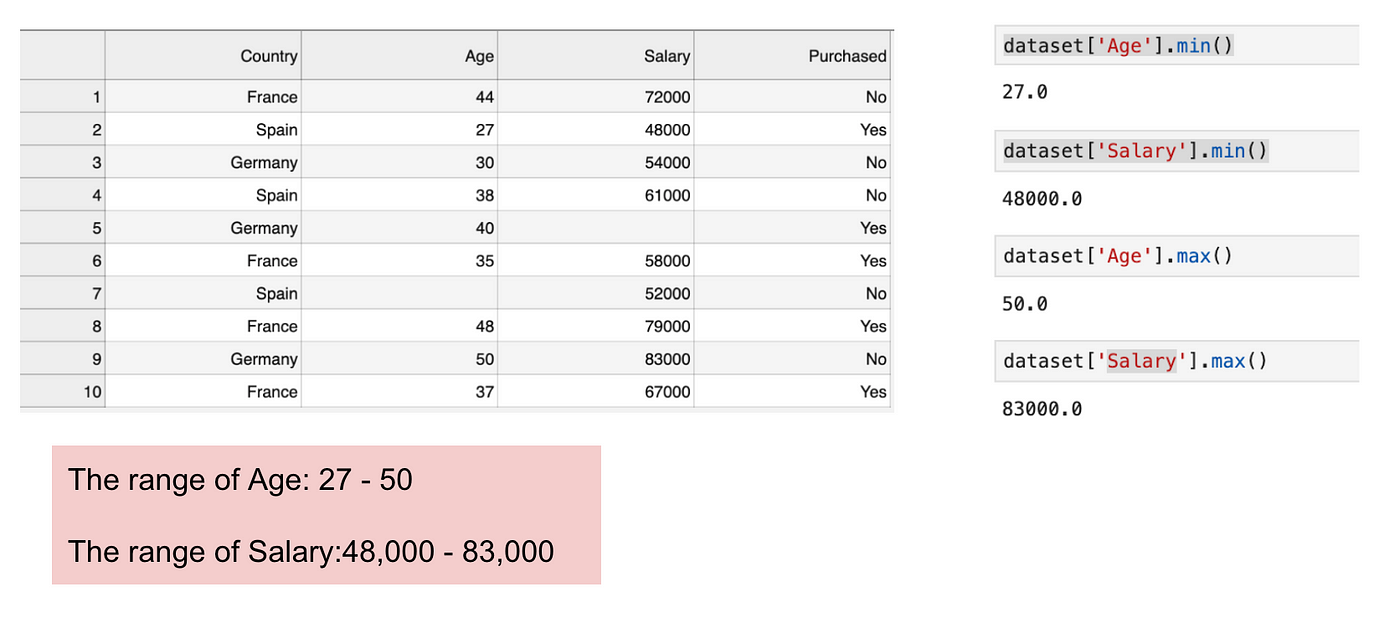
Focussen op leeftijd en salaris.
Wanneer we de vergelijking van de Euclidische afstand berekenen, is het aantal (x2-x1)² veel groter dan het aantal (y2-y1)², wat betekent dat de Euclidische afstand zal worden gedomineerd door het salaris als we geen feature scaling toepassen. Het verschil in leeftijd draagt minder bij tot het totale verschil. Daarom moeten we Feature Scaling gebruiken om alle waarden op dezelfde grootte te brengen en zo dit probleem op te lossen. Om dit te doen zijn er in hoofdzaak twee methoden, Standardisation en Normalisation.

Euclidische afstandstoepassing.
Standardisation
Het resultaat van standaardisatie (of Z-score normalisatie) is dat de kenmerken zodanig worden herschaald dat het gemiddelde en de standaardafwijking respectievelijk 0 en 1 zijn. De vergelijking staat hieronder:
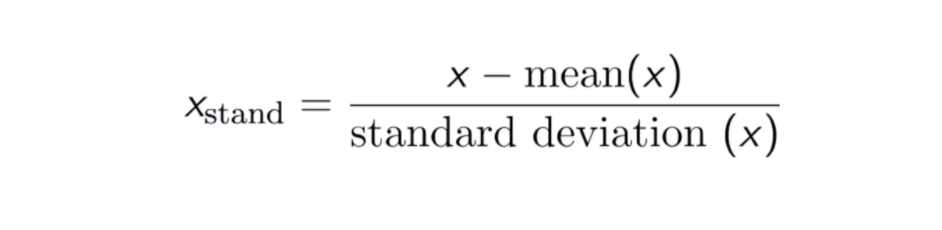
Deze techniek om de waarde van kenmerken te herschalen met de verdelingswaarde tussen 0 en 1 is nuttig voor de optimaliseringsalgoritmen, zoals gradiëntafdaling, die worden gebruikt binnen machine-learningalgoritmen die de invoer wegen (bv. regressie en neurale netwerken). Herschaling wordt ook gebruikt voor algoritmen die afstandsmetingen gebruiken, bijvoorbeeld K-Nearest-Neighbours (KNN).
Code
#Import libraryfrom sklearn.preprocessing import StandardScalersc_X = StandardScaler()sc_X = sc_X.fit_transform(df)#Convert to table format - StandardScaler sc_X = pd.DataFrame(data=sc_X, columns=)sc_X
Max-Min Normalization
Een andere veelgebruikte aanpak is de zogenaamde Max-Min Normalization (Min-Max-schaling). Met deze techniek worden kenmerken geschaald met een distributiewaarde tussen 0 en 1. Voor elk kenmerk wordt de minimumwaarde van dat kenmerk getransformeerd in 0, en de maximumwaarde wordt getransformeerd in 1. De algemene vergelijking staat hieronder:
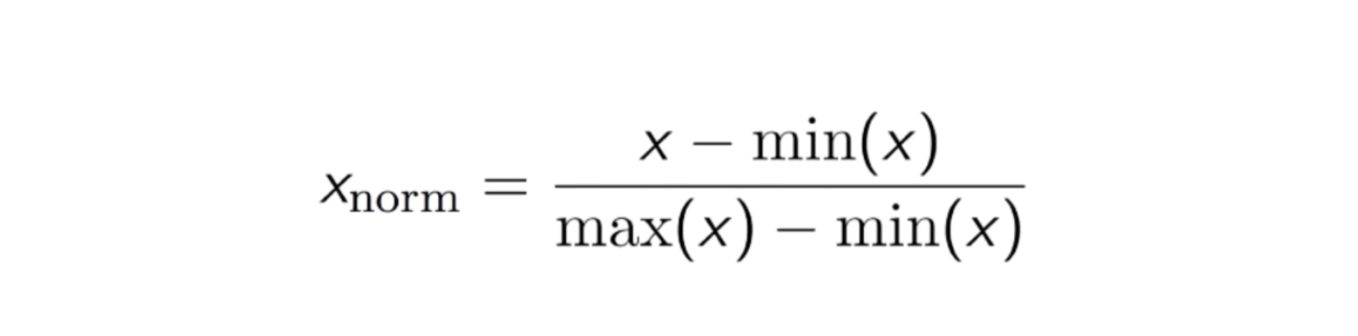
De vergelijking van Max-Min Normalization.
Code
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()scaler.fit(df)scaled_features = scaler.transform(df)#Convert to table format - MinMaxScalerdf_MinMax = pd.DataFrame(data=scaled_features, columns=)
Standaardisatie vs Max-Min Normalisatie
In tegenstelling tot standaardisatie krijgen we kleinere standaardafwijkingen door het proces van Max-Min Normalisatie. Ik zal dit nader toelichten aan de hand van de bovenstaande dataset.
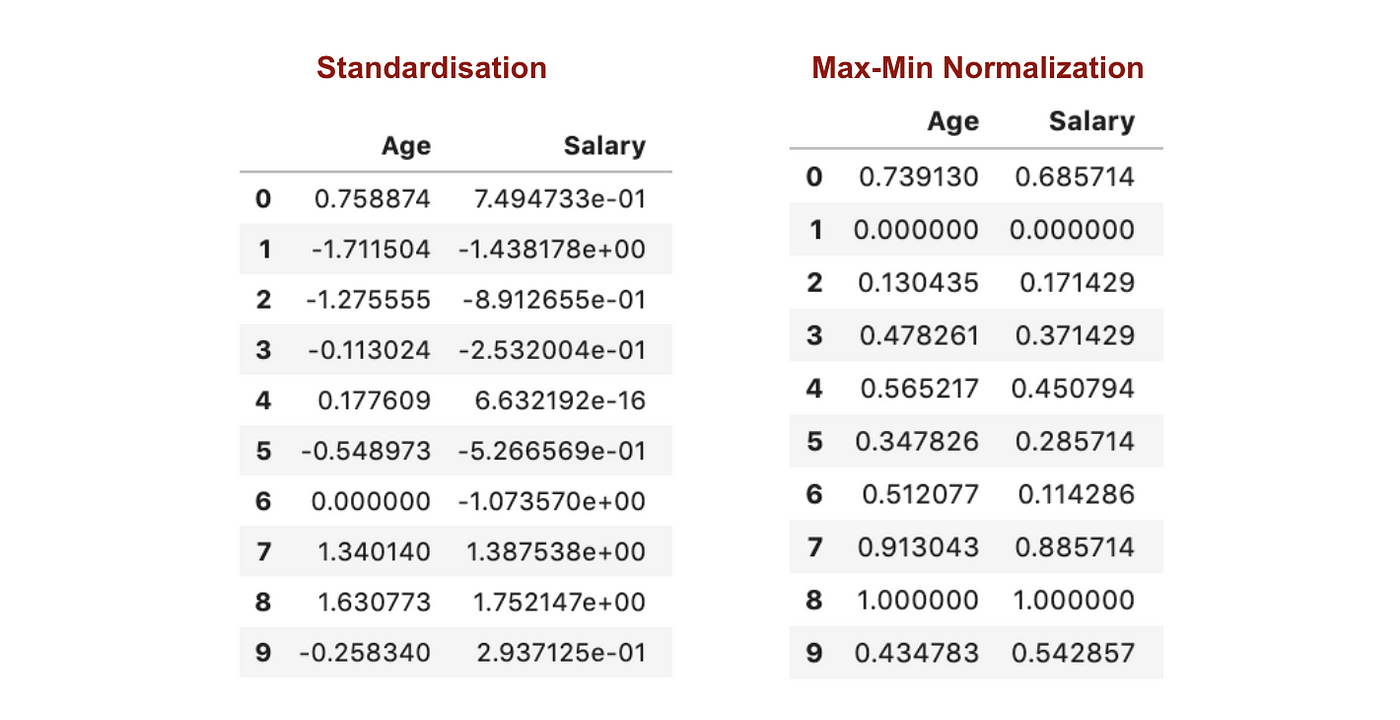
Na Feature scaling.
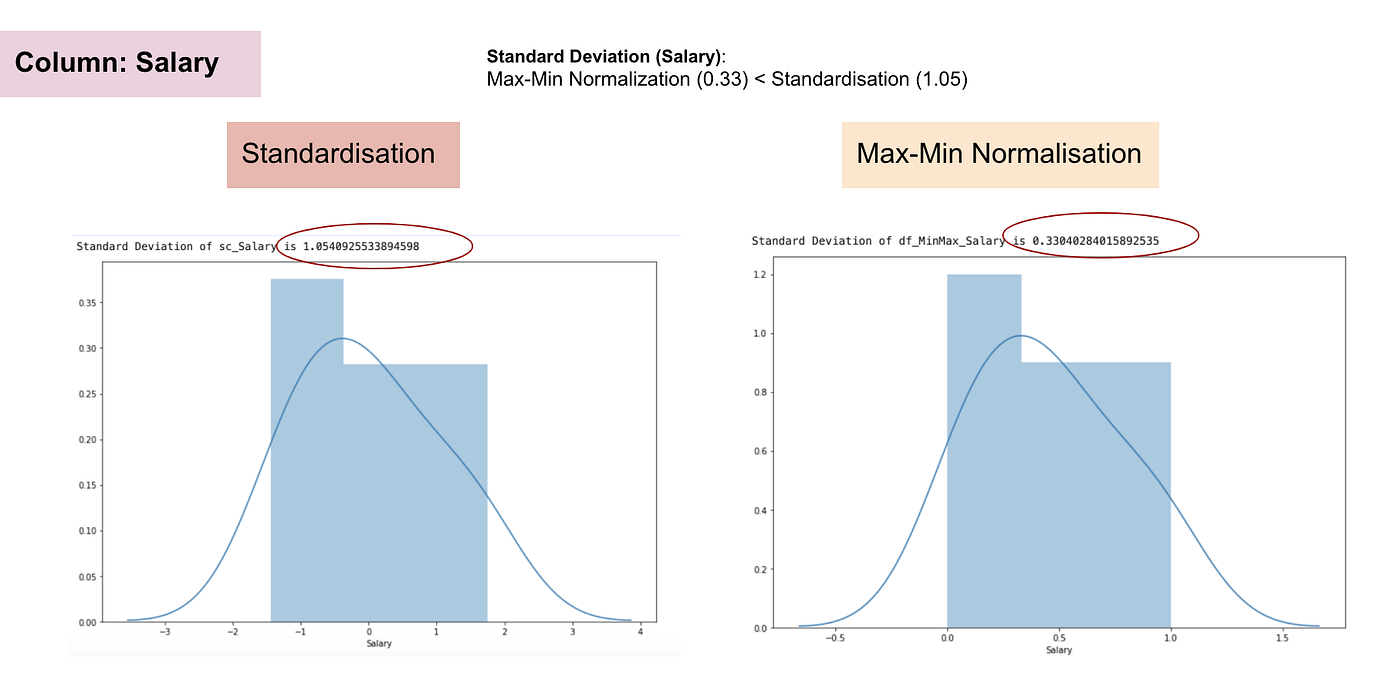
Normale verdeling en Standaardafwijking van Salaris.
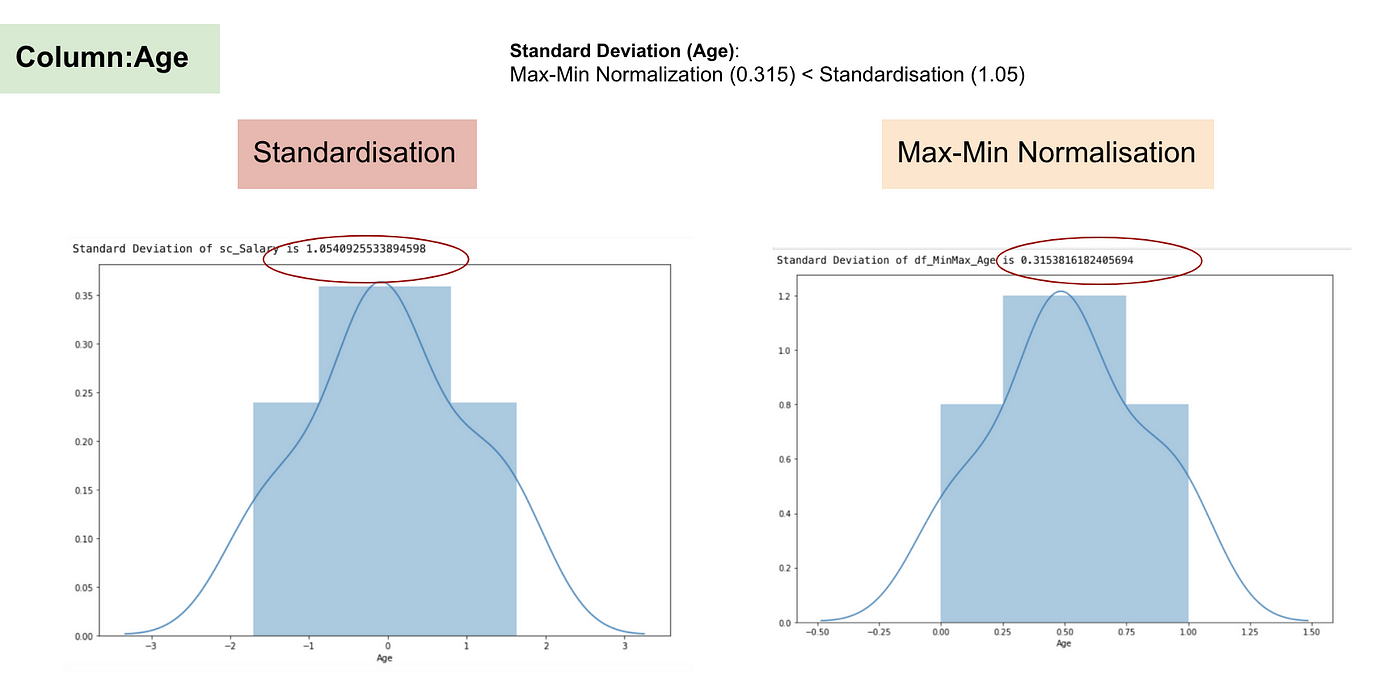
Normale verdeling en Standaardafwijking van Leeftijd.
Normale verdeling en Standaardafwijking van Leeftijd.
Normale verdeling en Standaardafwijking van Leeftijd.
Uit de bovenstaande grafieken kunnen we duidelijk opmaken dat de toepassing van Max-Min Nomaralisatie in onze dataset kleinere standaardafwijkingen (salaris en leeftijd) heeft opgeleverd dan de toepassing van de Standaardisatiemethode. Dit impliceert dat de gegevens meer geconcentreerd zijn rond het gemiddelde als we de gegevens schalen met behulp van Max-Min Nomaralisatie.
Als gevolg hiervan, als u uitschieters in uw kenmerk (kolom) hebt, zal het normaliseren van uw gegevens de meeste gegevens schalen naar een klein interval, wat betekent dat alle kenmerken dezelfde schaal zullen hebben, maar niet goed omgaat met uitschieters. Normalisatie is robuuster tegen uitschieters en verdient in veel gevallen de voorkeur boven Max-Min Normalisatie.
Wanneer Feature Scaling van belang is

Sommige machine learning-modellen zijn fundamenteel gebaseerd op afstandsmatrices, ook bekend als de op afstand gebaseerde classifier, bijvoorbeeld K-Nearest-Neighbours, SVM en Neural Network. Feature scaling is zeer essentieel voor deze modellen, vooral wanneer het bereik van de features zeer verschillend is. Anders zullen kenmerken met een groot bereik een grote invloed hebben op de berekening van de afstand.
Max-Min Normalisatie stelt ons gewoonlijk in staat de gegevens met verschillende schalen te transformeren, zodat geen enkele specifieke dimensie de statistiek zal domineren, en het vereist geen zeer sterke veronderstelling over de verdeling van de gegevens, zoals bij k-nearest neighbours en kunstmatige neurale netwerken. Normalisatie gaat echter niet erg goed om met outliners. Normalisatie daarentegen stelt gebruikers in staat beter om te gaan met uitbijters en vergemakkelijkt de convergentie voor sommige computeralgoritmen zoals gradiëntafdaling. Daarom geven wij gewoonlijk de voorkeur aan standaardisatie boven Min-Max-normalisatie.
Voorbeeld: Welke algoritmen hebben feature scaling nodig
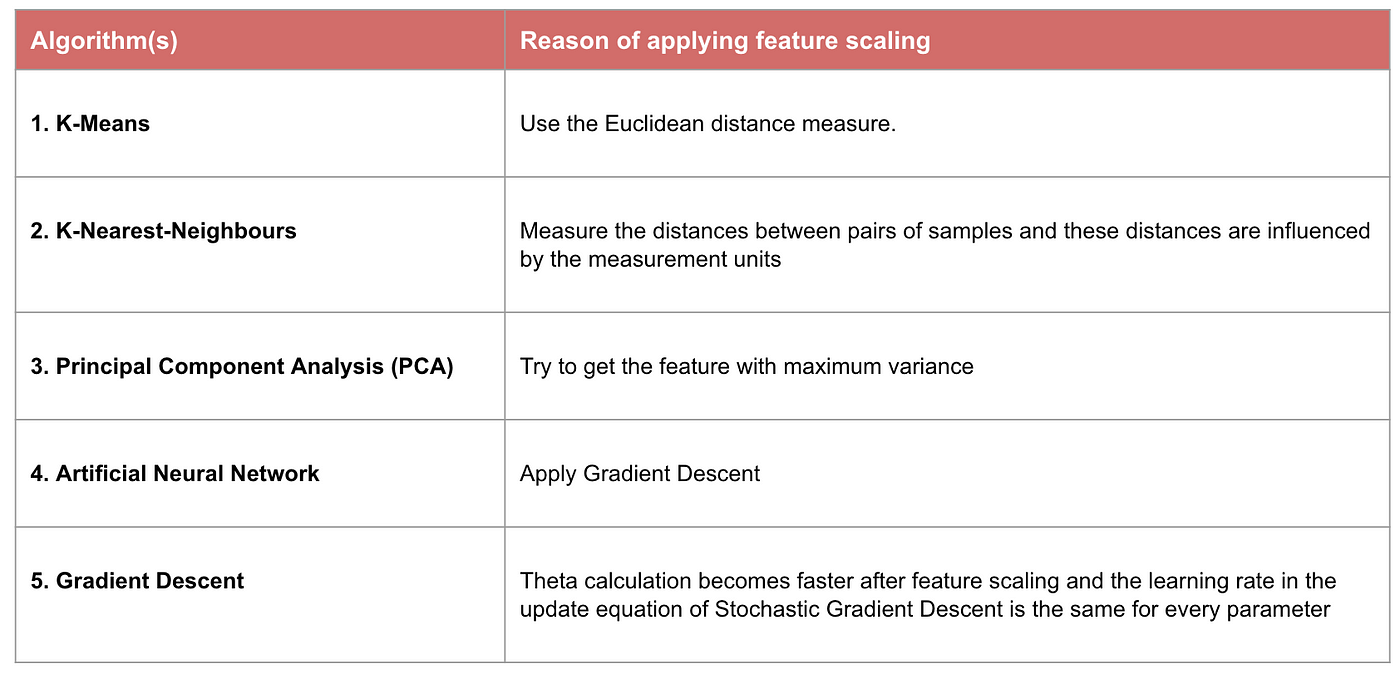
Noot: Als een algoritme niet op afstand is gebaseerd, is feature scaling onbelangrijk, met inbegrip van Naive Bayes, Lineaire Discriminantanalyse en Tree-Based modellen (gradient boosting, random forest, enz.).
Samenvatting: Nu zou u moeten weten
- het doel van het gebruik van Feature Scaling
- het verschil tussen Standaardisatie en Normalisatie
- de algoritmen die Standaardisatie of Normalisatie moeten toepassen
- het toepassen van feature scaling in Python
De code en dataset vindt u hier.