
Transformarea datelor este unul dintre pașii fundamentali în partea de procesare a datelor. Când am învățat pentru prima dată tehnica de scalare a caracteristicilor, se folosesc adesea termenii scalare, standardizare și normalizare. Cu toate acestea, a fost destul de greu să găsesc informații despre care dintre ele ar trebui să le folosesc și, de asemenea, când să le folosesc. Prin urmare, voi explica următoarele aspecte cheie în acest articol:
- diferența dintre standardizare și normalizare
- când să folosim standardizarea și când să folosim normalizarea
- cum să aplicăm scalarea caracteristicilor în Python
Ce înseamnă scalarea caracteristicilor?
În practică, întâlnim adesea diferite tipuri de variabile în același set de date. O problemă semnificativă este că intervalul variabilelor poate diferi foarte mult. Utilizarea scalei originale poate pune mai multe ponderi pe variabilele cu un interval mare. Pentru a rezolva această problemă, trebuie să aplicăm tehnica de redimensionare a caracteristicilor variabilelor independente sau a caracteristicilor datelor în etapa de preprocesare a datelor. Termenii de normalizare și standardizare sunt uneori folosiți interschimbabil, dar de obicei se referă la lucruri diferite.
Obiectivul aplicării scalării caracteristicilor este de a ne asigura că caracteristicile se află aproape pe aceeași scară, astfel încât fiecare caracteristică să fie la fel de importantă și să fie mai ușor de procesat de majoritatea algoritmilor ML.
Exemplu
Acesta este un set de date care conține o variabilă independentă (Achiziționat) și 3 variabile dependente (Țara, Vârsta și Salariul). Putem observa cu ușurință că variabilele nu se află pe aceeași scară, deoarece intervalul Vârsta este cuprins între 27 și 50 de ani, în timp ce intervalul Salariul merge de la 48 K la 83 K. Intervalul Salariul este mult mai larg decât intervalul Vârsta. Acest lucru va cauza unele probleme în modelele noastre, deoarece o mulțime de modele de învățare automată, cum ar fi gruparea k-means și clasificarea celui mai apropiat vecin se bazează pe distanța euclidiană.
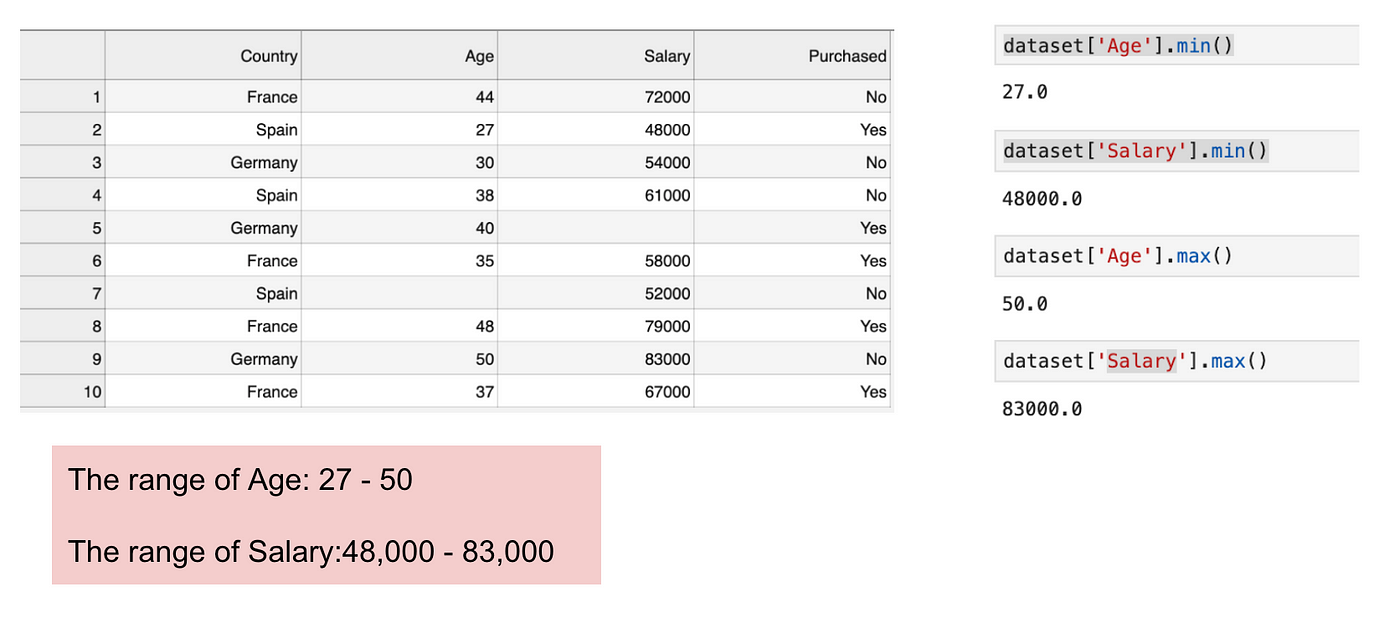
Concentrarea pe vârstă și salariu.
Când calculăm ecuația distanței euclidiene, numărul de (x2-x1)² este mult mai mare decât numărul de (y2-y1)², ceea ce înseamnă că distanța euclidiană va fi dominată de salariu dacă nu aplicăm scalarea caracteristicilor. Diferența de vârstă contribuie mai puțin la diferența totală. Prin urmare, ar trebui să folosim Feature Scaling pentru a aduce toate valorile la aceleași mărimi și, astfel, să rezolvăm această problemă. Pentru a face acest lucru, există în principal două metode numite Standardizare și Normalizare.

Aplicarea distanței euclidiene.
Standardizare
Rezultatul standardizării (sau al normalizării scorului Z) este că trăsăturile vor fi redimensionate pentru a se asigura că media și abaterea standard să fie 0 și, respectiv, 1. Ecuația este prezentată mai jos:
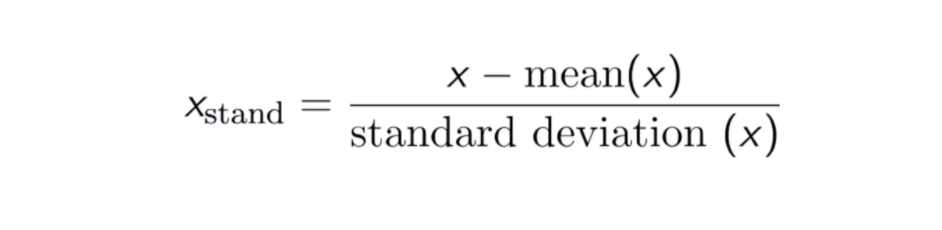
Această tehnică este de a redimensiona valoarea caracteristicilor cu valoarea de distribuție între 0 și 1 este utilă pentru algoritmii de optimizare, cum ar fi coborârea gradientului, care sunt utilizați în cadrul algoritmilor de învățare automată care ponderează intrările (de exemplu, regresia și rețelele neuronale). Redimensionarea este, de asemenea, utilizată în cazul algoritmilor care utilizează măsurători de distanță, de exemplu, K-Nearest-Neighbours (KNN).
Code
#Import libraryfrom sklearn.preprocessing import StandardScalersc_X = StandardScaler()sc_X = sc_X.fit_transform(df)#Convert to table format - StandardScaler sc_X = pd.DataFrame(data=sc_X, columns=)sc_X
Normalizare Max-Min
O altă abordare comună este așa-numita normalizare Max-Min (scalare Min-Max). Această tehnică constă în reeșalonarea caracteristicilor cu o valoare de distribuție între 0 și 1. Pentru fiecare caracteristică, valoarea minimă a acelei caracteristici se transformă în 0, iar valoarea maximă se transformă în 1. Ecuația generală este prezentată mai jos:
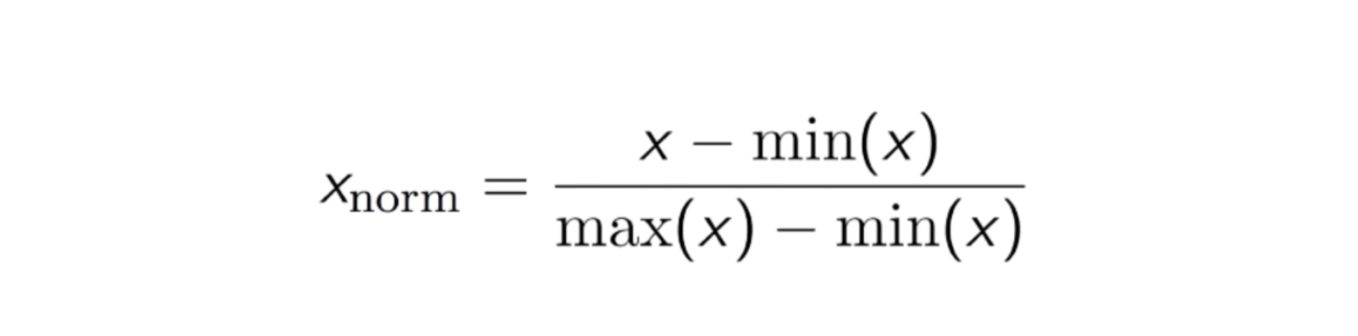
Ecuația normalizării Max-Min.
Cod
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()scaler.fit(df)scaled_features = scaler.transform(df)#Convert to table format - MinMaxScalerdf_MinMax = pd.DataFrame(data=scaled_features, columns=)
Standardizare vs. Normalizare Max-Min
În contrast cu standardizarea, vom obține deviații standard mai mici prin procesul de Normalizare Max-Min. Permiteți-mi să ilustrez mai multe în acest domeniu folosind setul de date de mai sus.
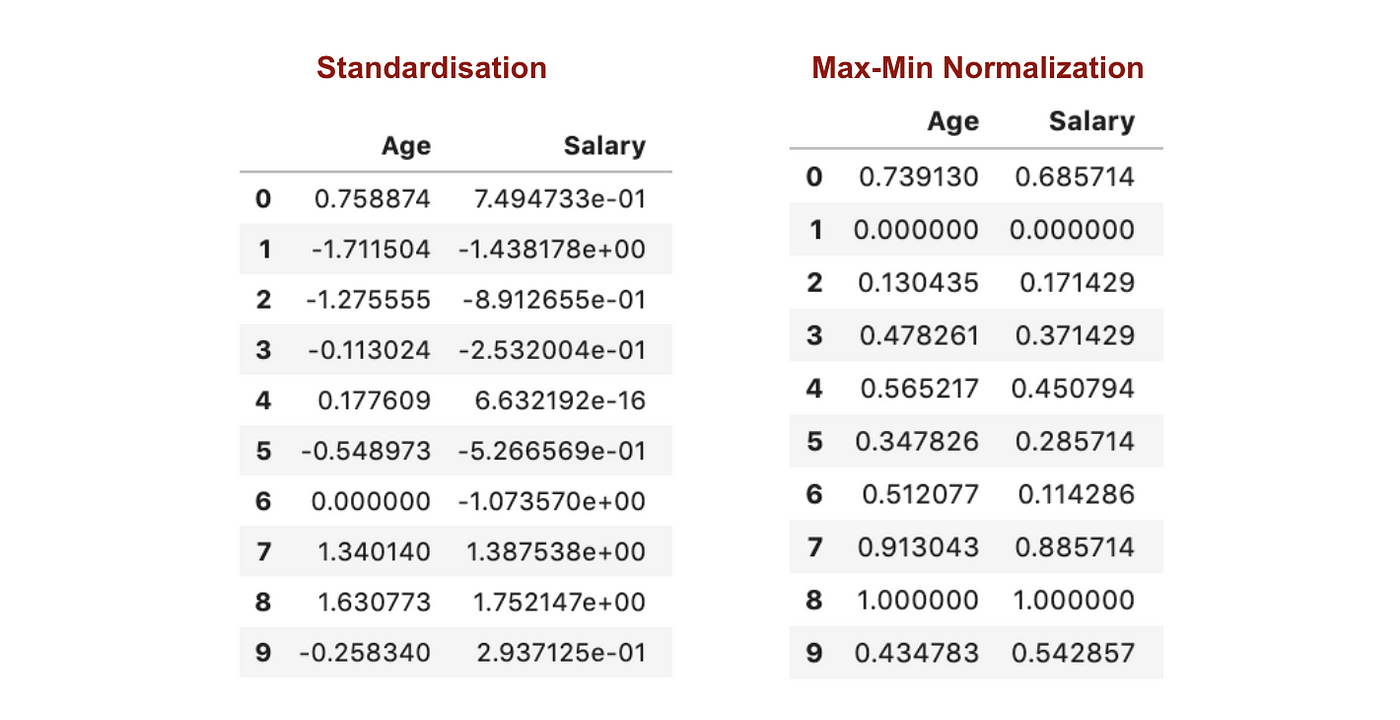
După scalarea caracteristicilor.
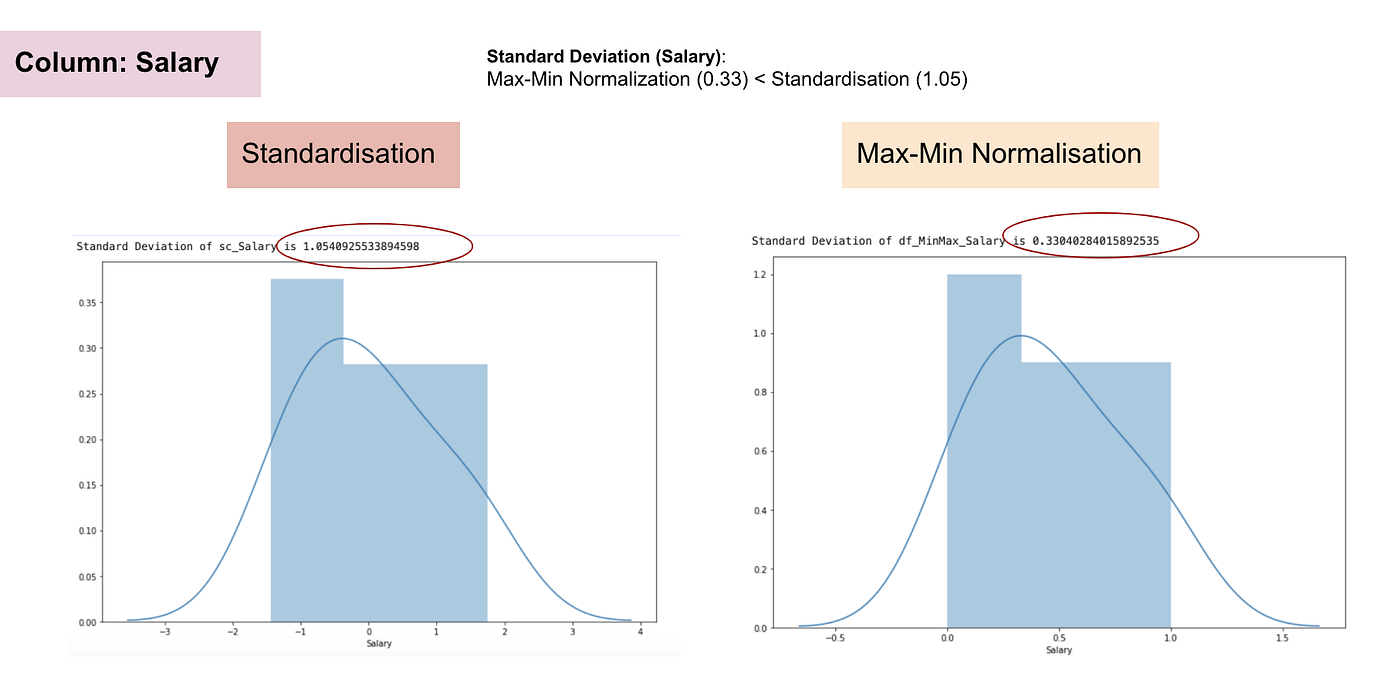
Distribuția normală și abaterea standard a salariului.
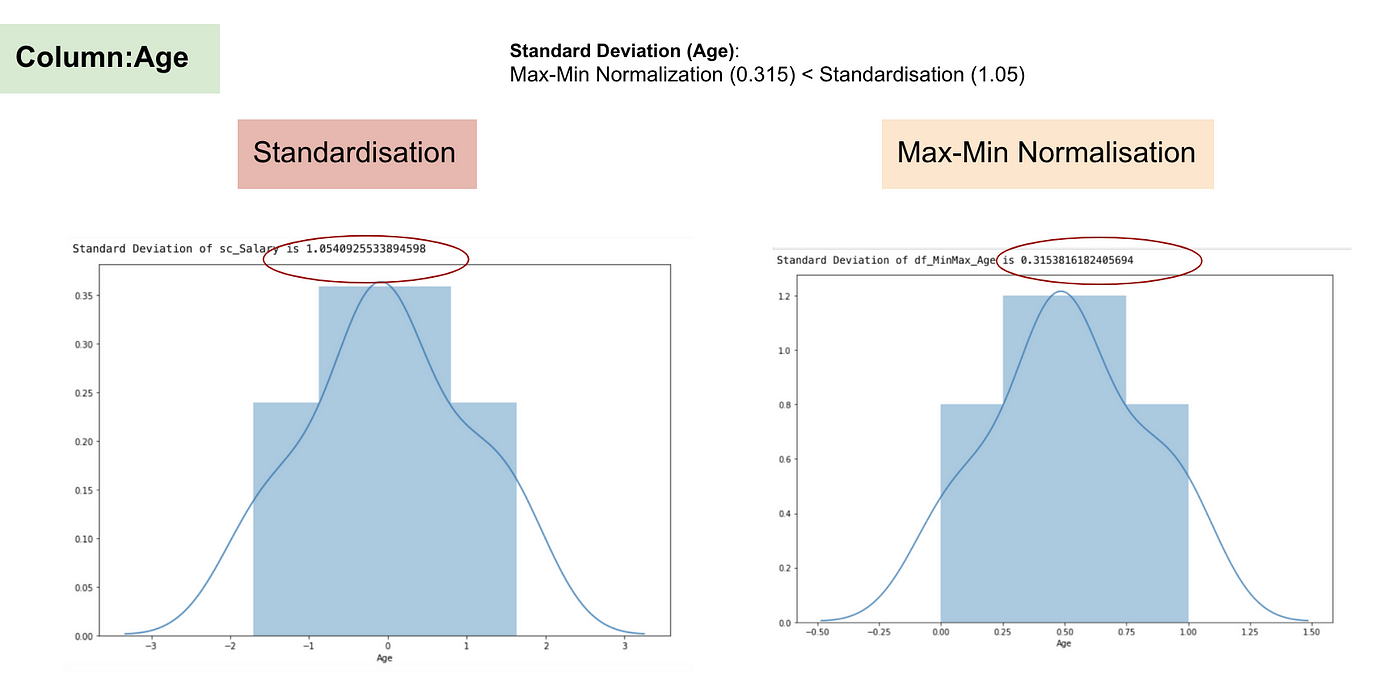
Distribuția normală și abaterea standard a vârstei.
Din graficele de mai sus, putem observa în mod clar că aplicarea Nomaralizării Max-Min în setul nostru de date a generat abateri standard mai mici (salariu și vârstă) decât utilizarea metodei de standardizare. Aceasta implică faptul că datele sunt mai concentrate în jurul mediei dacă scalăm datele utilizând Nomaralizarea Max-Min.
Ca urmare, dacă aveți valori aberante în caracteristica (coloana) dvs., normalizarea datelor va scala majoritatea datelor la un interval mic, ceea ce înseamnă că toate caracteristicile vor avea aceeași scară, dar nu gestionează bine valorile aberante. Normalizarea este mai robustă la valorile aberante și, în multe cazuri, este preferabilă față de normalizarea Max-Min.
Când contează scalarea caracteristicilor

Câteva modele de învățare automată se bazează în mod fundamental pe matricea de distanțe, cunoscută și sub numele de clasificator bazat pe distanțe, de exemplu, K-Nearest-Neighbours, SVM și rețeaua neuronală. Scalarea caracteristicilor este extrem de esențială pentru aceste modele, în special atunci când intervalul caracteristicilor este foarte diferit. În caz contrar, caracteristicile cu o gamă mare vor avea o mare influență în calcularea distanței.
Normalizarea Max-Min ne permite, de obicei, să transformăm datele cu scări diferite, astfel încât nicio dimensiune specifică să nu domine statisticile și nu necesită formularea unei ipoteze foarte puternice cu privire la distribuția datelor, cum ar fi K-nearest neighbours și rețelele neuronale artificiale. Cu toate acestea, normalizarea nu tratează foarte bine elementele de contur. Dimpotrivă, normalizarea permite utilizatorilor să trateze mai bine valorile aberante și să faciliteze convergența pentru unii algoritmi de calcul, cum ar fi coborârea gradientului. Prin urmare, de obicei, preferăm standardizarea în locul Normalizării Min-Max.
Exemplu: Ce algoritmi au nevoie de scalarea caracteristicilor
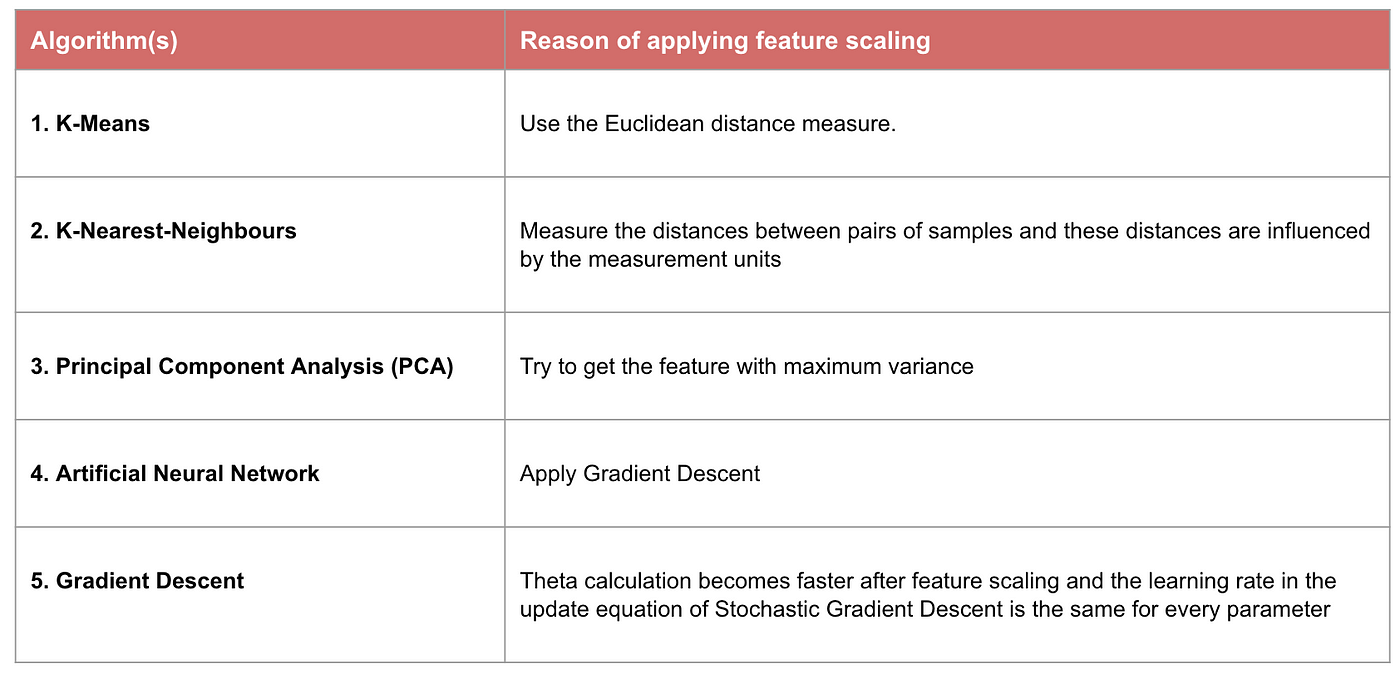
Nota: Dacă un algoritm nu se bazează pe distanțe, scalarea caracteristicilor nu este importantă, inclusiv Naive Bayes, analiza discriminantă liniară și modelele bazate pe arbori (gradient boosting, random forest etc.).
Rezumat: Acum ar trebui să știți
- obiectivul utilizării scalării caracteristicilor
- diferența dintre Standardizare și Normalizare
- algoritmii care trebuie să aplice Standardizarea sau Normalizarea
- aplicarea scalării caracteristicilor în Python
Vă rugăm să găsiți codul și setul de date aici.