
Dataomvandling är ett av de grundläggande stegen i databehandlingen. När jag för första gången lärde mig tekniken för skalning av funktioner användes ofta termerna skala, standardisera och normalisera. Det var dock ganska svårt att hitta information om vilka av dem jag ska använda och även när de ska användas. Därför kommer jag att förklara följande viktiga aspekter i den här artikeln:
- skillnaden mellan standardisering och normalisering
- när man ska använda standardisering och när man ska använda normalisering
- hur man tillämpar feature scaling i Python
Vad innebär feature scaling?
I praktiken stöter vi ofta på olika typer av variabler i samma dataset. Ett viktigt problem är att intervallet för variablerna kan skilja sig mycket åt. Om man använder den ursprungliga skalan kan man lägga större vikt vid variabler med ett stort intervall. För att hantera detta problem måste vi tillämpa tekniken för omskalning av funktioner på oberoende variabler eller funktioner i data i steget förbehandling av data. Termerna normalisering och standardisering används ibland synonymt, men de hänvisar vanligtvis till olika saker.
Målet med att tillämpa Feature Scaling är att se till att funktionerna ligger på nästan samma skala så att varje funktion är lika viktig och gör det lättare att bearbeta med de flesta ML-algoritmer.
Exempel
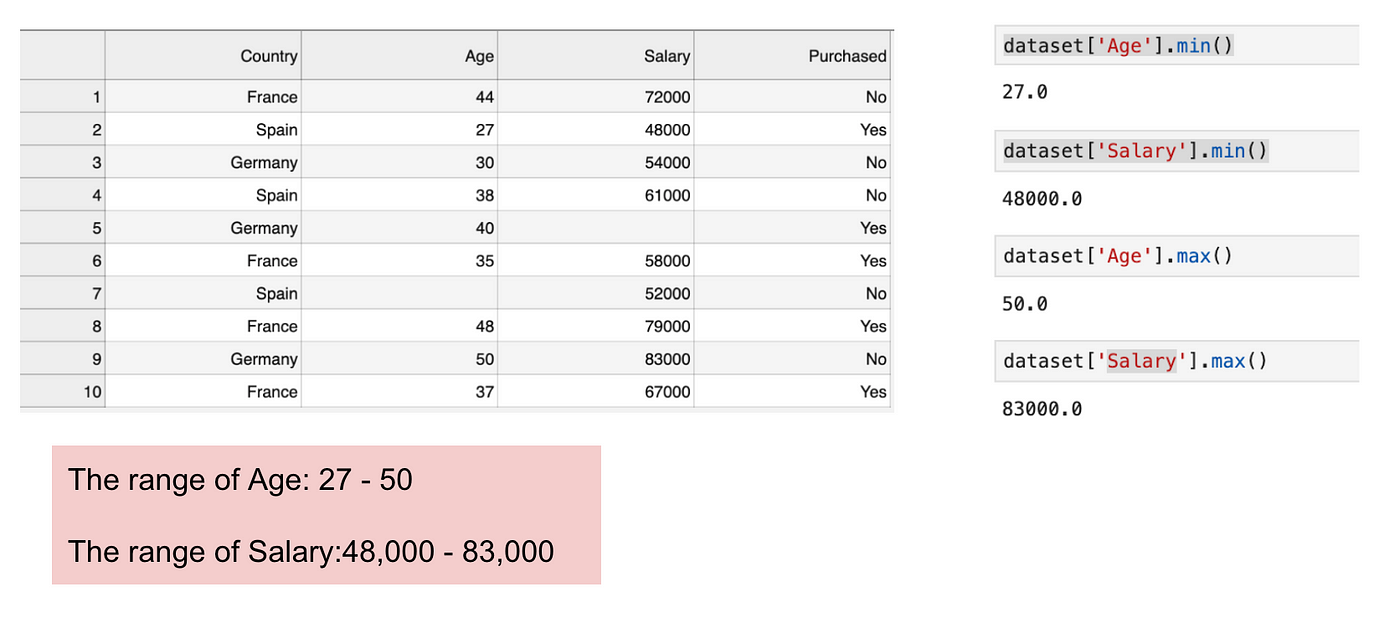
Det här är en datamängd som innehåller en oberoende variabel (Inköpt) och 3 beroende variabler (Land, Ålder och Lön). Vi kan lätt märka att variablerna inte är på samma skala eftersom åldersintervallet ligger mellan 27 och 50 år, medan löneintervallet ligger mellan 48 000 och 83 000. Löneintervallet är mycket större än åldersintervallet. Detta kommer att orsaka vissa problem i våra modeller eftersom många modeller för maskininlärning, t.ex. k-means-klustring och klassificering av närmaste granne, bygger på det euklidiska avståndet.
Fokusering på ålder och lön.
När vi beräknar ekvationen för det euklidiska avståndet är antalet (x2-x1)² mycket större än antalet (y2-y1)² vilket innebär att det euklidiska avståndet kommer att domineras av lönen om vi inte tillämpar funktionsskalning. Skillnaden i ålder bidrar mindre till den totala skillnaden. Därför bör vi använda Feature Scaling för att få alla värden att bli lika stora och på så sätt lösa detta problem. För att göra detta finns det främst två metoder som kallas standardisering och normalisering.

Euklidisk distanstillämpning.
Standardisering
Resultatet av standardisering (eller Z-score-normalisering) är att funktionerna skalas om för att säkerställa att medelvärdet och standardavvikelsen blir 0 respektive 1. Ekvationen visas nedan:
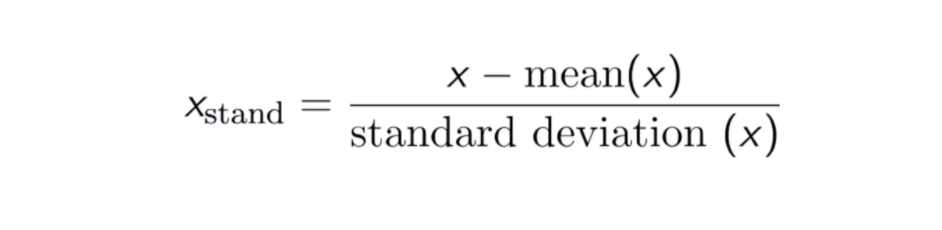
Denna teknik är att omskalera features värde med fördelningsvärdet mellan 0 och 1 är användbar för de optimeringsalgoritmer, såsom gradient descent, som används inom maskininlärningsalgoritmer som viktar indata (t.ex. regression och neurala nätverk). Omskalering används också för algoritmer som använder avståndsmått, till exempel K-Nearest-Neighbours (KNN).
Kod
#Import libraryfrom sklearn.preprocessing import StandardScalersc_X = StandardScaler()sc_X = sc_X.fit_transform(df)#Convert to table format - StandardScaler sc_X = pd.DataFrame(data=sc_X, columns=)sc_X
Max-Min Normalisering
En annan vanlig metod är den så kallade Max-Min Normaliseringen (Min-Max skalning). Denna teknik går ut på att omskalera funktioner med ett fördelningsvärde mellan 0 och 1. För varje funktion omvandlas minimivärdet för den funktionen till 0 och maximivärdet till 1. Den allmänna ekvationen visas nedan:
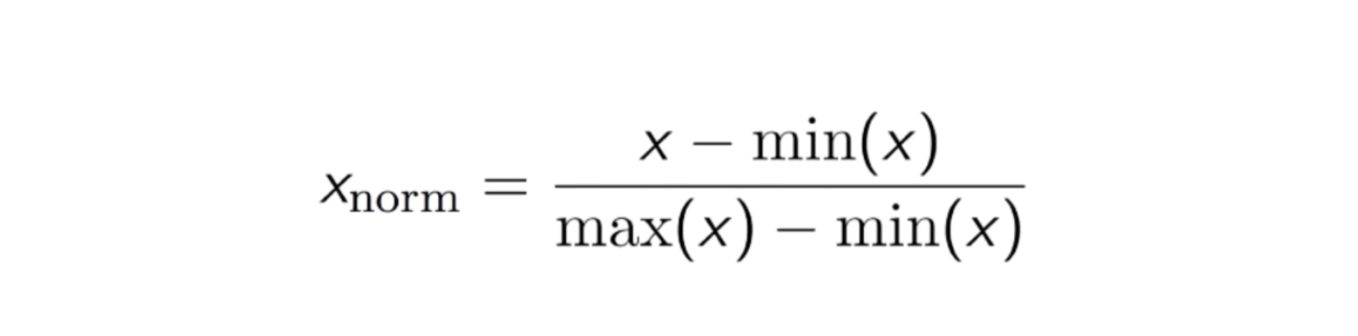
Ekvationen för Max-Min-normalisering.
Kod
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()scaler.fit(df)scaled_features = scaler.transform(df)#Convert to table format - MinMaxScalerdf_MinMax = pd.DataFrame(data=scaled_features, columns=)
Standardisering vs Max-Min Normalisering
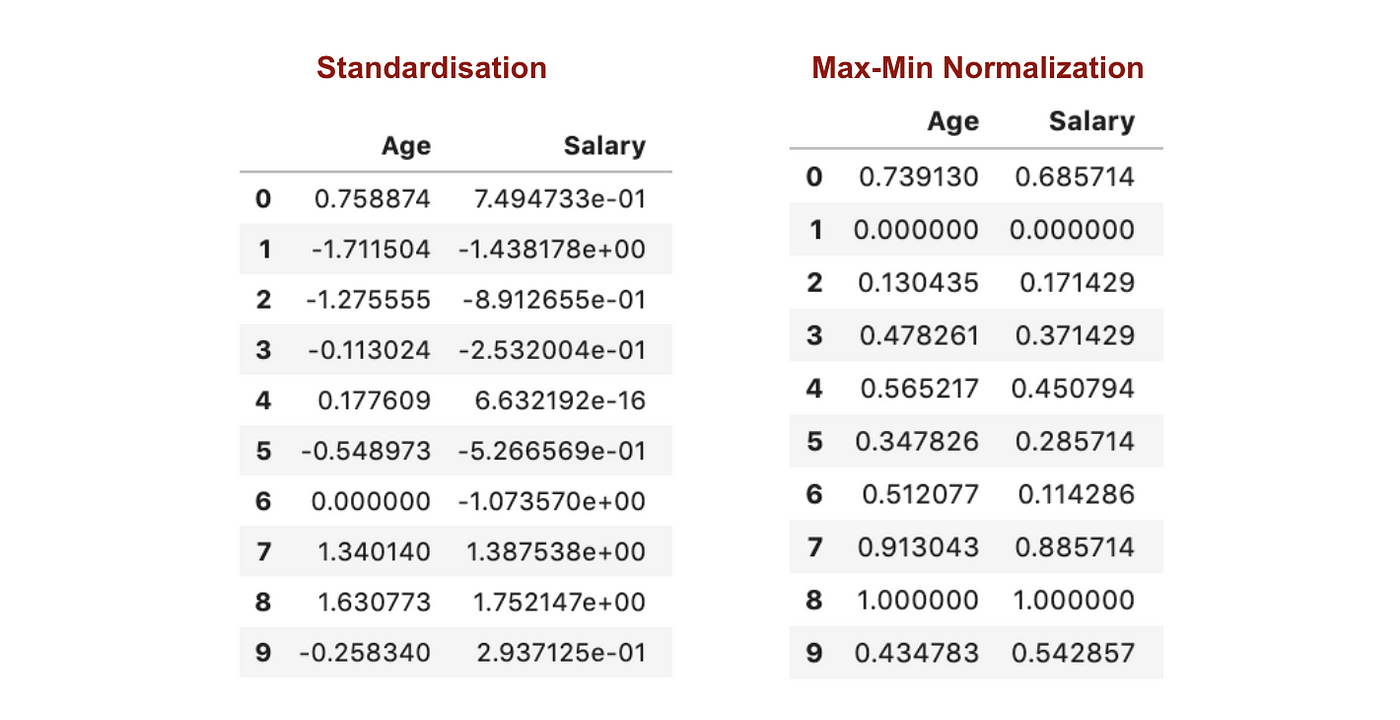
I motsats till standardisering kommer vi att få mindre standardavvikelser genom processen Max-Min Normalisering. Låt mig illustrera mer på detta område med hjälp av ovanstående dataset.
Efter Feature scaling.
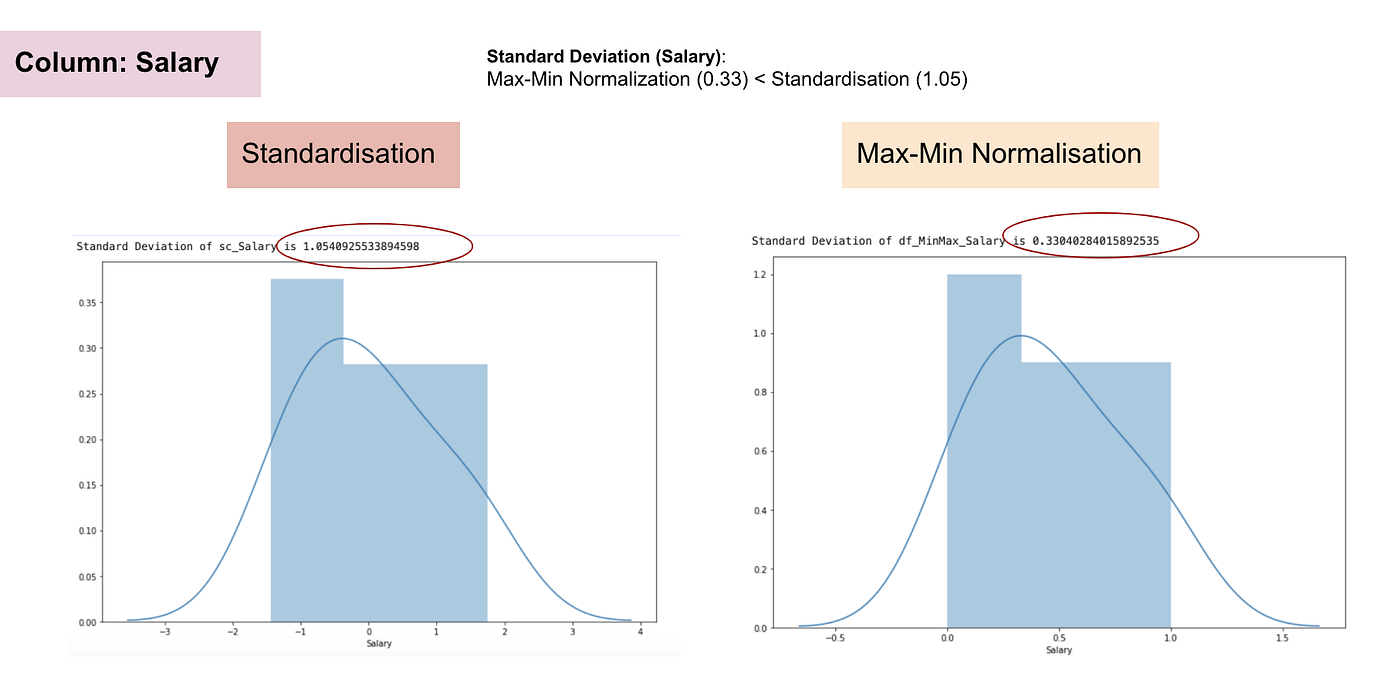
Normalfördelning och standardavvikelse för lön.
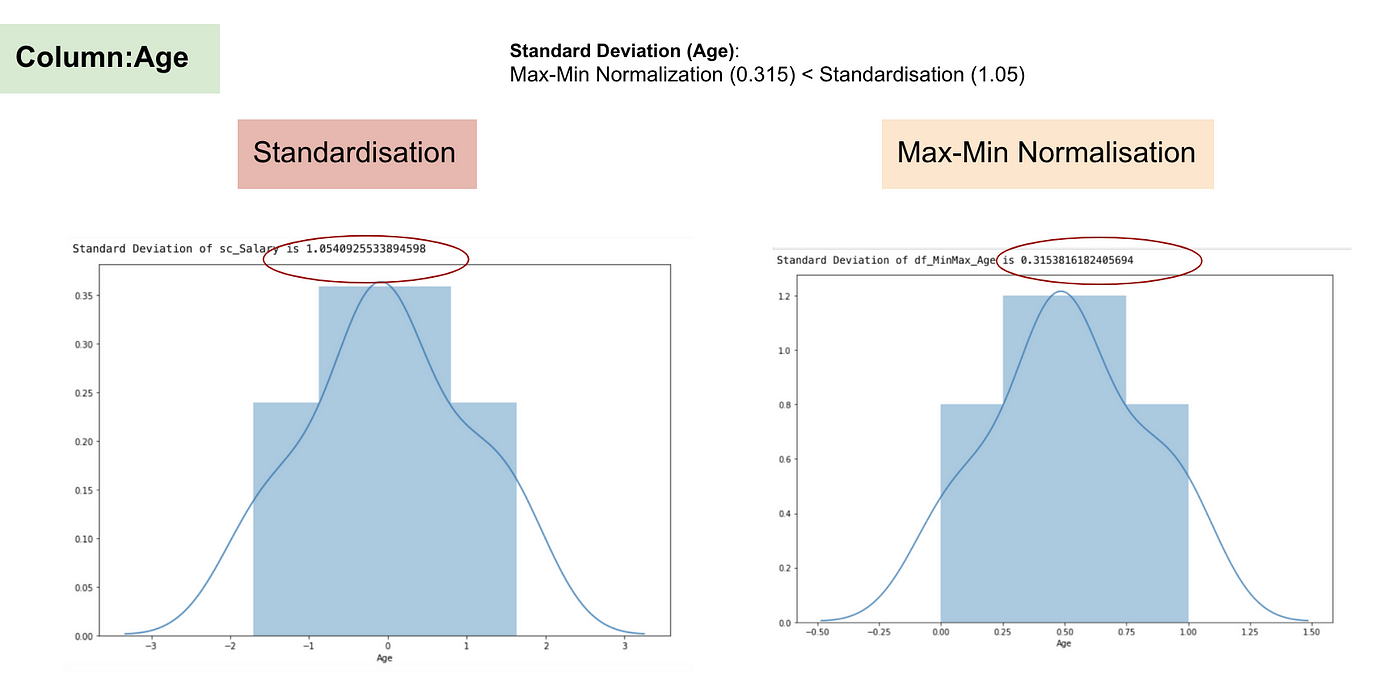
Normalfördelning och standardavvikelse för ålder.
Från ovanstående grafer kan vi tydligt se att tillämpningen av Max-Min Nomaralisation i vårt dataset har genererat mindre standardavvikelser (Lön och Ålder) än om vi använder Standardiseringsmetoden. Det innebär att data är mer koncentrerade kring medelvärdet om vi skalar data med Max-Min Nomaralisation.
Som ett resultat, om du har outliers i din funktion (kolumn), kommer normalisering av dina data att skala de flesta data till ett litet intervall, vilket innebär att alla funktioner kommer att ha samma skala, men hanterar inte outliers på ett bra sätt. Normalisering är mer robust mot outliers och är i många fall att föredra framför Max-Min-normalisering.
När skalning av funktioner spelar roll

Vissa modeller för maskininlärning är i grunden baserade på avståndsmatris, även känd som avståndsbaserad klassificerare, t.ex. K-Nearest-Neighbours, SVM och neurala nätverk. Skalning av funktioner är ytterst viktigt för dessa modeller, särskilt när funktionernas räckvidd är mycket olika. Annars kommer funktioner med ett stort intervall att ha ett stort inflytande vid beräkningen av avståndet.
Max-Min-normalisering gör det vanligtvis möjligt för oss att omvandla data med varierande skalor så att ingen specifik dimension kommer att dominera statistiken, och det kräver inte att man gör ett mycket starkt antagande om datafördelningen, till exempel k-nästa grannar och artificiella neurala nätverk. Normalisering behandlar dock inte outliners särskilt bra. Tvärtom gör normalisering det möjligt för användare att bättre hantera outliers och underlätta konvergensen för vissa beräkningsalgoritmer som gradient descent. Därför föredrar vi vanligtvis standardisering framför Min-Max-normalisering.
Exempel: Vilka algoritmer behöver funktionsskalering
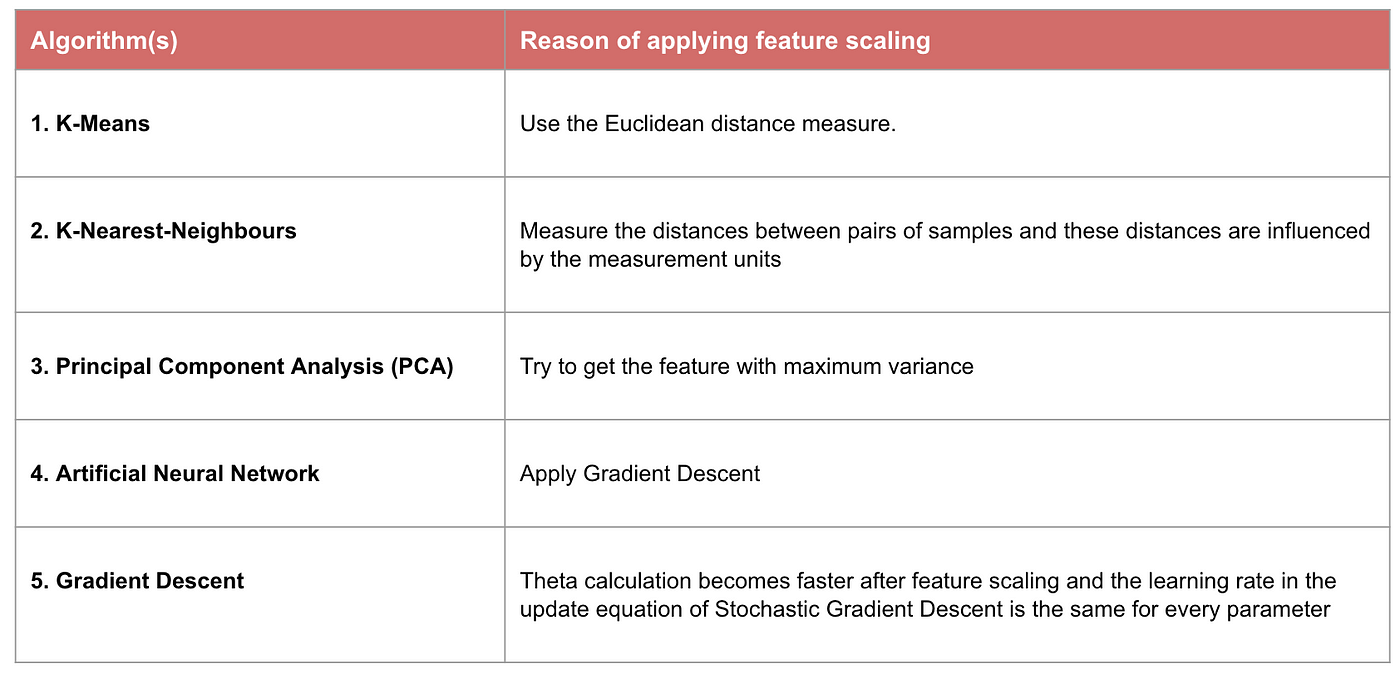
Notera: Om en algoritm inte är avståndsbaserad är funktionsskalering oviktigt, inklusive Naive Bayes, linjär diskriminantanalys och trädbaserade modeller (gradient boosting, random forest etc.).
Sammanfattning: Nu bör du känna till
- syftet med att använda Feature Scaling
- skillnaden mellan standardisering och normalisering
- algoritmerna som behöver tillämpa standardisering eller normalisering
- tillämpa Feature Scaling i Python
Här hittar du koden och datamaterialet.