
Datentransformation ist einer der grundlegenden Schritte im Rahmen der Datenverarbeitung. Als ich die Technik der Merkmalsskalierung kennenlernte, wurden häufig die Begriffe Skalieren, Standardisieren und Normalisieren verwendet. Es war jedoch ziemlich schwierig, Informationen darüber zu finden, welche dieser Begriffe ich verwenden sollte und auch wann ich sie verwenden sollte. Deshalb erkläre ich in diesem Artikel die folgenden Hauptaspekte:
- Der Unterschied zwischen Standardisierung und Normalisierung
- Wann wird standardisiert und wann wird normalisiert
- Wie wendet man Feature-Skalierung in Python an
Was bedeutet Feature-Skalierung?
In der Praxis treffen wir oft auf verschiedene Arten von Variablen im selben Datensatz. Ein wesentliches Problem besteht darin, dass der Bereich der Variablen sehr unterschiedlich sein kann. Die Verwendung der ursprünglichen Skala kann dazu führen, dass die Variablen mit einem großen Bereich stärker gewichtet werden. Um dieses Problem zu lösen, müssen wir im Schritt der Datenvorverarbeitung die Technik der Neuskalierung der Merkmale auf unabhängige Variablen oder Merkmale der Daten anwenden. Die Begriffe Normalisierung und Standardisierung werden manchmal austauschbar verwendet, aber sie beziehen sich in der Regel auf unterschiedliche Dinge.
Das Ziel der Anwendung der Merkmalsskalierung ist es, sicherzustellen, dass die Merkmale auf fast der gleichen Skala liegen, so dass jedes Merkmal gleich wichtig ist und die Verarbeitung durch die meisten ML-Algorithmen erleichtert wird.
Beispiel
Dies ist ein Datensatz, der eine unabhängige Variable (Gekauft) und 3 abhängige Variablen (Land, Alter und Gehalt) enthält. Wir können leicht feststellen, dass die Variablen nicht auf der gleichen Skala liegen, da der Bereich des Alters von 27 bis 50 reicht, während der Bereich des Gehalts von 48 K bis 83 K reicht. Der Bereich des Gehalts ist viel größer als der Bereich des Alters. Dies führt zu einigen Problemen in unseren Modellen, da viele Modelle des maschinellen Lernens wie k-means clustering und nearest neighbour classification auf der euklidischen Distanz basieren.
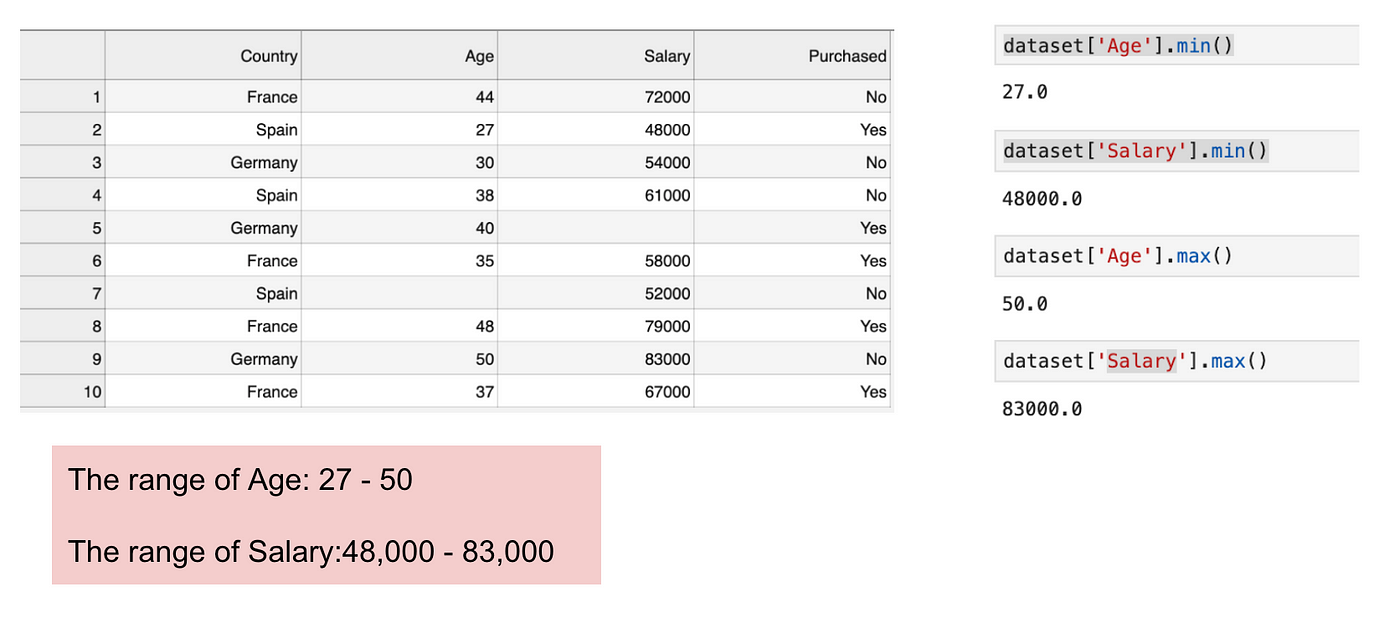
Fokussierung auf Alter und Gehalt.
Wenn wir die Gleichung des euklidischen Abstands berechnen, ist die Anzahl von (x2-x1)² viel größer als die Anzahl von (y2-y1)², was bedeutet, dass der euklidische Abstand durch das Gehalt dominiert wird, wenn wir keine Merkmalsskalierung anwenden. Der Unterschied im Alter trägt weniger zum Gesamtunterschied bei. Daher sollten wir die Merkmalsskalierung verwenden, um alle Werte auf die gleiche Größe zu bringen und so dieses Problem zu lösen. Dazu gibt es in erster Linie zwei Methoden, die Standardisierung und Normalisierung genannt werden.

Euklidische Distanzanwendung.
Standardisierung
Das Ergebnis der Standardisierung (oder Z-Score-Normalisierung) ist, dass die Merkmale neu skaliert werden, um sicherzustellen, dass der Mittelwert und die Standardabweichung 0 bzw. 1 sind. Die Gleichung ist unten dargestellt:
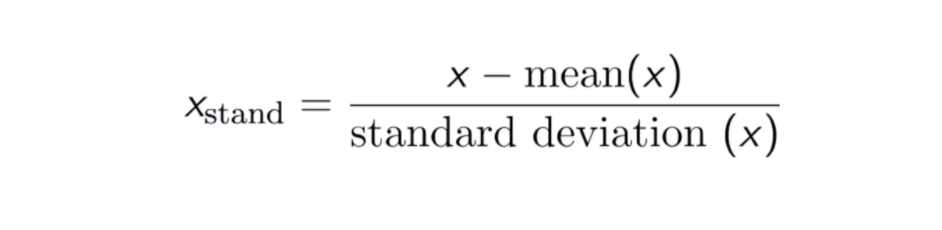
Diese Technik zur Neuskalierung der Merkmalswerte mit einem Verteilungswert zwischen 0 und 1 ist nützlich für Optimierungsalgorithmen wie den Gradientenabstieg, die in Algorithmen für maschinelles Lernen verwendet werden, die Eingaben gewichten (z. B. Regression und neuronale Netze). Die Neuskalierung wird auch für Algorithmen verwendet, die Abstandsmessungen verwenden, z. B. K-Nearest-Neighbours (KNN).
Code
#Import libraryfrom sklearn.preprocessing import StandardScalersc_X = StandardScaler()sc_X = sc_X.fit_transform(df)#Convert to table format - StandardScaler sc_X = pd.DataFrame(data=sc_X, columns=)sc_X
Max-Min-Normalisierung
Ein weiterer gängiger Ansatz ist die sogenannte Max-Min-Normalisierung (Min-Max-Skalierung). Bei dieser Technik werden Merkmale mit einem Verteilungswert zwischen 0 und 1 neu skaliert. Für jedes Merkmal wird der Minimalwert dieses Merkmals in 0 und der Maximalwert in 1 umgewandelt. Die allgemeine Gleichung ist unten dargestellt:
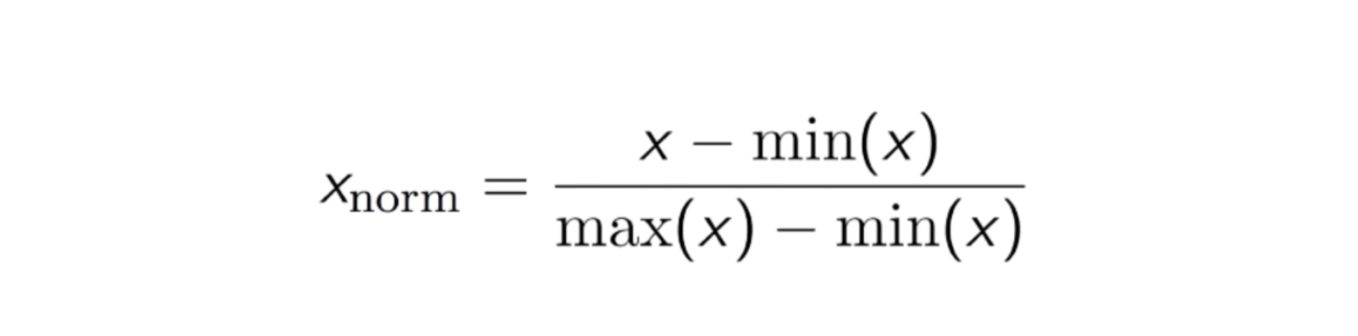
Die Gleichung der Max-Min-Normalisierung.
Code
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()scaler.fit(df)scaled_features = scaler.transform(df)#Convert to table format - MinMaxScalerdf_MinMax = pd.DataFrame(data=scaled_features, columns=)
Standardisierung vs. Max-Min-Normalisierung
Im Gegensatz zur Standardisierung erhalten wir durch den Prozess der Max-Min-Normalisierung kleinere Standardabweichungen. Lassen Sie mich diesen Bereich anhand des obigen Datensatzes näher erläutern.
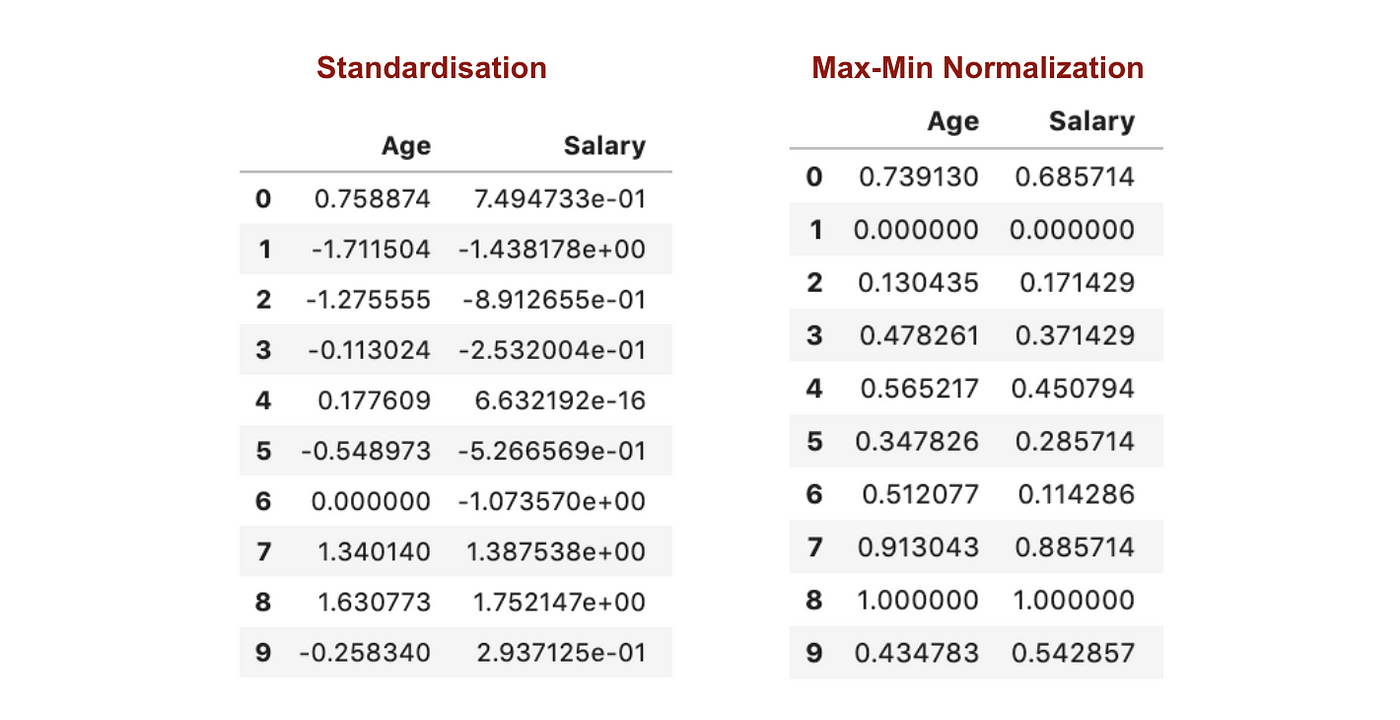
Nach der Merkmalsskalierung.
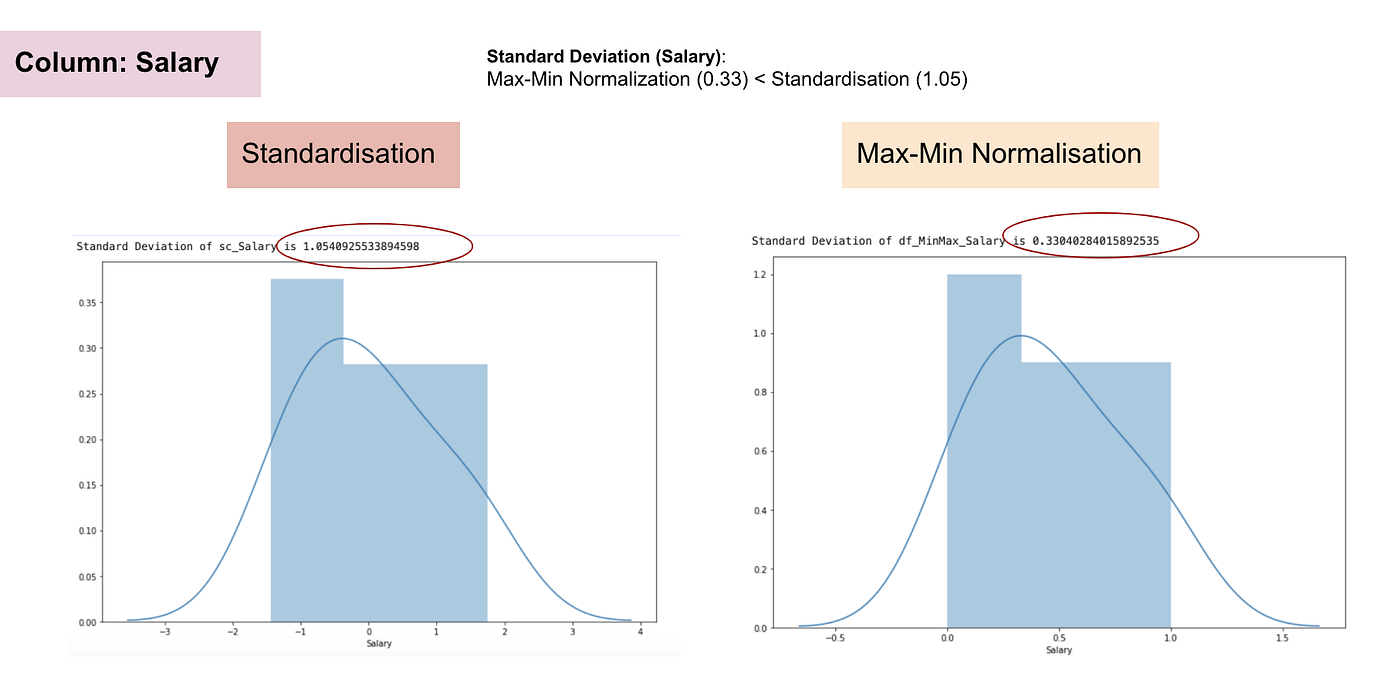
Normalverteilung und Standardabweichung des Gehalts.
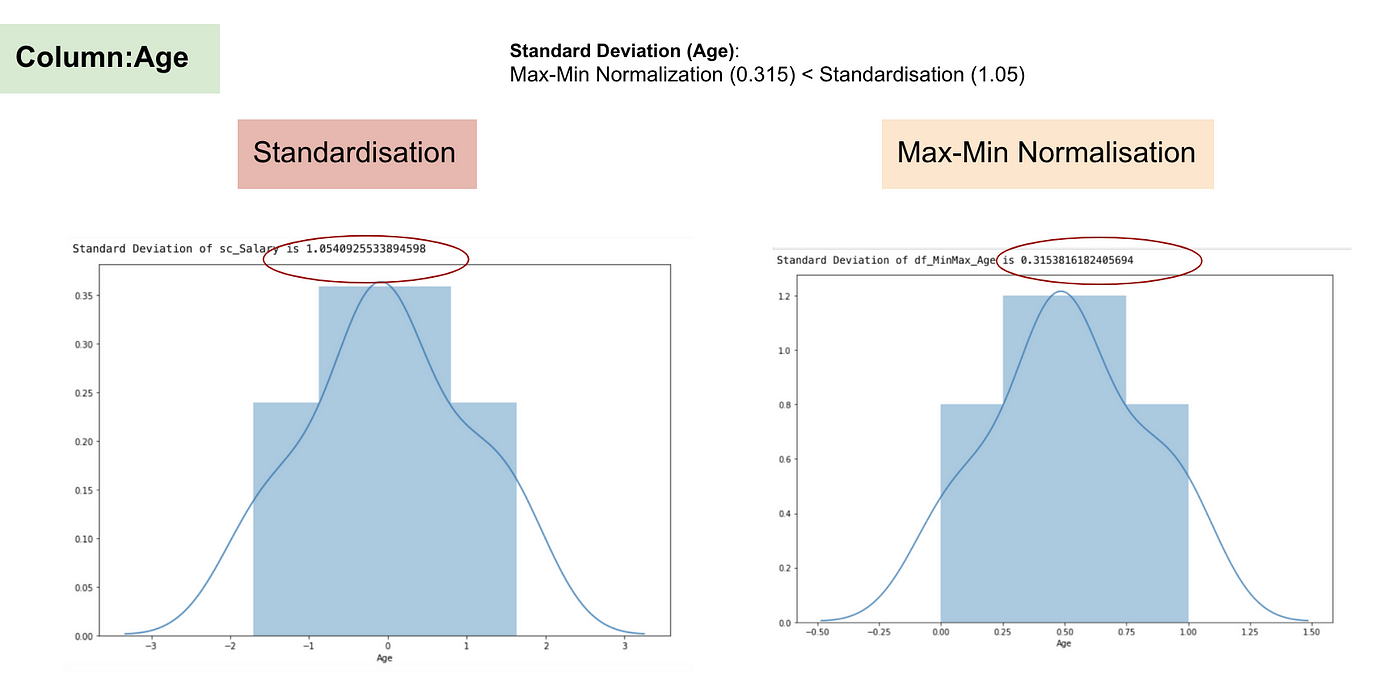
Normalverteilung und Standardabweichung des Alters.
Aus den obigen Diagrammen können wir deutlich erkennen, dass die Anwendung der Max-Min-Normalisierung in unserem Datensatz zu kleineren Standardabweichungen (Gehalt und Alter) geführt hat als die Anwendung der Standardisierungsmethode. Das bedeutet, dass die Daten stärker um den Mittelwert konzentriert sind, wenn wir die Daten mit der Max-Min-Nomaralisierung skalieren.
Wenn Sie Ausreißer in Ihren Merkmalen (Spalten) haben, wird die Normalisierung Ihrer Daten die meisten Daten auf ein kleines Intervall skalieren, was bedeutet, dass alle Merkmale die gleiche Skala haben, aber Ausreißer nicht gut behandelt werden. Die Normalisierung ist robuster gegenüber Ausreißern und in vielen Fällen der Max-Min-Normalisierung vorzuziehen.
Wenn Feature-Skalierung wichtig ist

Einige Modelle des maschinellen Lernens basieren grundsätzlich auf einer Abstandsmatrix, die auch als abstandsbasierter Klassifikator bekannt ist, z. B. K-Nearest-Neighbours, SVM und Neuronales Netz. Die Skalierung von Merkmalen ist für diese Modelle äußerst wichtig, vor allem wenn der Bereich der Merkmale sehr unterschiedlich ist. Andernfalls haben Merkmale mit einem großen Bereich einen großen Einfluss auf die Berechnung des Abstands.
Die Max-Min-Normalisierung ermöglicht es uns in der Regel, die Daten mit unterschiedlichen Skalen zu transformieren, so dass keine bestimmte Dimension die Statistik dominiert, und sie erfordert keine sehr starken Annahmen über die Verteilung der Daten, wie z. B. bei K-Nearest-Neighbours und künstlichen neuronalen Netzen. Allerdings werden bei der Normalisierung Outliner nicht sehr gut behandelt. Im Gegensatz dazu ermöglicht die Standardisierung einen besseren Umgang mit Ausreißern und erleichtert die Konvergenz bei einigen Berechnungsalgorithmen wie dem Gradientenabstieg. Daher ziehen wir in der Regel die Standardisierung der Min-Max-Normalisierung vor.
Beispiel: Welche Algorithmen benötigen eine Merkmalsskalierung
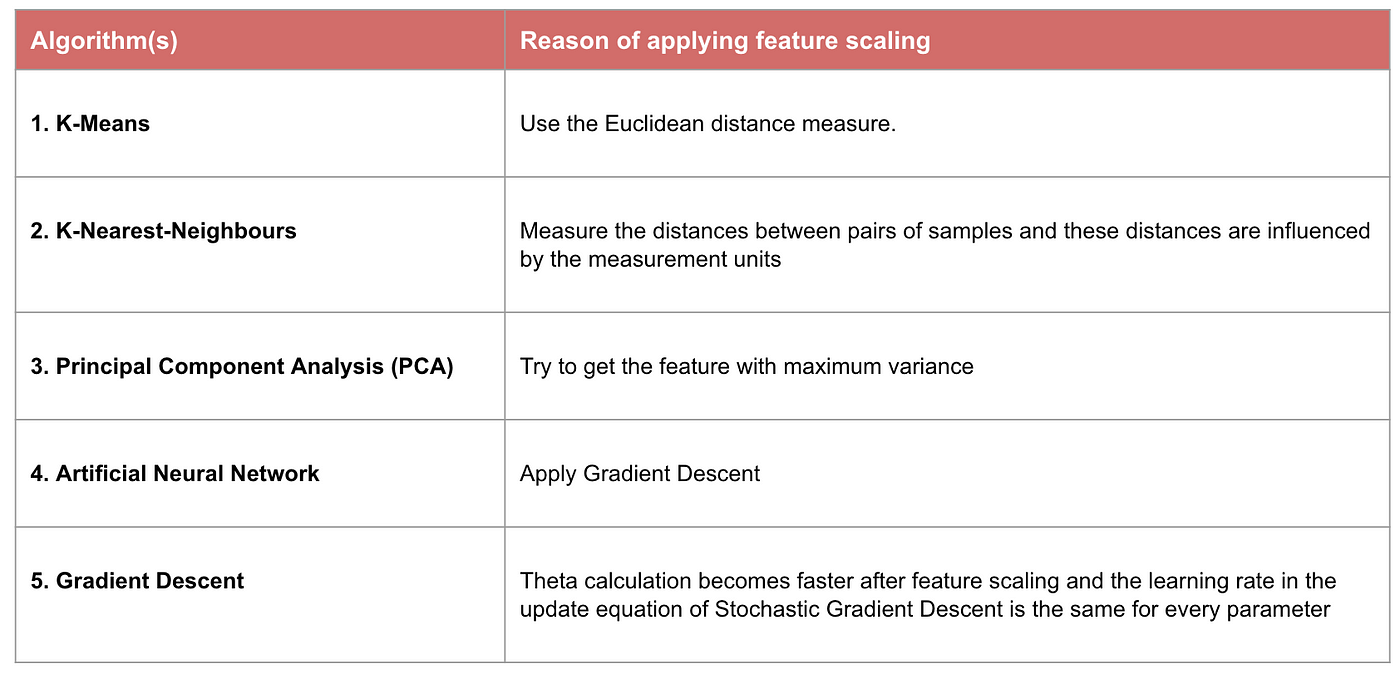
Anmerkung: Wenn ein Algorithmus nicht distanzbasiert ist, ist die Merkmalsskalierung unwichtig, einschließlich Naive Bayes, Lineare Diskriminanzanalyse und baumbasierte Modelle (Gradient Boosting, Random Forest usw.).
Zusammenfassung: Jetzt sollten Sie wissen
- was das Ziel der Anwendung von Feature Scaling ist
- den Unterschied zwischen Standardisierung und Normalisierung
- die Algorithmen, die Standardisierung oder Normalisierung anwenden müssen
- Anwendung von Feature Scaling in Python
Bitte finden Sie den Code und den Datensatz hier.