Sei qui:Inizio “Guida alla visione artificiale “Template Matching
Introduzione

Template Matching è una tecnica di visione artificiale di alto livello che identifica le parti di un’immagine che corrispondono a un modello predefinito. Algoritmi avanzati di template matching permettono di trovare le occorrenze del template indipendentemente dal loro orientamento e dalla luminosità locale.
Le tecniche di template matching sono flessibili e relativamente semplici da usare, il che le rende uno dei metodi più popolari di localizzazione degli oggetti. La loro applicabilità è limitata principalmente dalla potenza di calcolo disponibile, poiché l’identificazione di modelli grandi e complessi può richiedere molto tempo.
Concetto
Le tecniche di corrispondenza dei modelli dovrebbero affrontare la seguente necessità: fornita un’immagine di riferimento di un oggetto (l’immagine modello) e un’immagine da ispezionare (l’immagine di ingresso) vogliamo identificare tutte le posizioni dell’immagine di ingresso in cui l’oggetto dell’immagine modello è presente. A seconda del problema specifico in questione, possiamo (o non possiamo) voler identificare le occorrenze ruotate o scalate.
Inizieremo con una dimostrazione di un metodo ingenuo di Template Matching, che è insufficiente per le applicazioni della vita reale, ma illustra il concetto di base da cui derivano gli algoritmi di Template Matching attuali. Dopodiché spiegheremo come questo metodo viene migliorato ed esteso in routine avanzate di Grayscale-based Matching e Edge-based Matching.
Naive Template Matching
Immaginate che stiamo per ispezionare l’immagine di una spina e il nostro obiettivo è trovare i suoi pin. Ci viene fornita un’immagine modello che rappresenta l’oggetto di riferimento che stiamo cercando e l’immagine di ingresso da ispezionare.
 |
 |
|
Immagine modello |
Immagine di ingresso |
Eseguiremo la ricerca effettiva in modo piuttosto semplice – posizioneremo il modello sull’immagine in ogni possibile posizione, e ogni volta calcoleremo una qualche misura numerica di somiglianza tra il modello e il segmento dell’immagine con cui si sovrappone attualmente. Infine identificheremo le posizioni che producono le migliori misure di somiglianza come probabili occorrenze del modello.
Correlazione di immagini
Uno dei sottoproblemi che si verificano nella specifica di cui sopra è il calcolo della misura di somiglianza dell’immagine modello allineata e il segmento sovrapposto dell’immagine di ingresso, che è equivalente al calcolo di una misura di somiglianza di due immagini di dimensioni uguali. Questo è un compito classico, e una misura numerica di somiglianza dell’immagine è solitamente chiamata correlazione dell’immagine.
Correlazione incrociata
| Immagine1 | Immagine2 | Cross-Correlazione |
|---|---|---|
|
 |
19404780 |
|
 |
23316890 |
|
 |
24715810 |
Il metodo fondamentale per calcolare la correlazione delle immagini è la cosiddetta cross-correlazione incrociata, che essenzialmente è una semplice somma di moltiplicazioni a coppie di valori di pixel corrispondenti delle immagini.
Anche se possiamo notare che il valore di correlazione sembra effettivamente riflettere la somiglianza delle immagini confrontate, il metodo della correlazione incrociata è lontano dall’essere robusto. Il suo principale svantaggio è che è influenzato dai cambiamenti nella luminosità globale delle immagini – la luminosità di un’immagine può far salire alle stelle la sua correlazione incrociata con un’altra immagine, anche se la seconda immagine non è affatto simile.
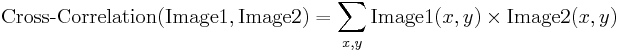
Correlazione incrociata normalizzata
| Immagine1 | Immagine2 | NCC |
|---|---|---|
|
|
-0.417 |
|
|
0.553 |
|
|
0.844 |
La correlazione incrociata normalizzata è una versione migliorata del classico metodo di correlazione incrociata che introduce due miglioramenti rispetto a quello originale:
- I risultati sono invarianti alle variazioni di luminosità globale, cioè.Cioè l’illuminazione o l’oscuramento consistente di entrambe le immagini non ha alcun effetto sul risultato (questo si ottiene sottraendo la luminosità media dell’immagine da ogni valore di pixel).
- Il valore di correlazione finale è scalato in base all’intervallo, in modo che l’NCC di due immagini identiche è uguale a 1.0, mentre l’NCC di un’immagine e la sua negazione è uguale a -1.0.
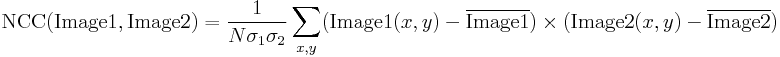
Template Correlation Image
Torniamo al problema in questione. Avendo introdotto la Normalized Cross-Correlation – robusta misura di somiglianza dell’immagine – siamo ora in grado di determinare quanto bene il template si adatti a ciascuna delle possibili posizioni. Possiamo rappresentare i risultati sotto forma di un’immagine, dove la luminosità di ogni pixel rappresenta il valore NCC del modello posizionato sopra questo pixel (il colore nero rappresenta la correlazione minima di -1,0, il colore bianco rappresenta la correlazione massima di 1,0).
|
|
 |
|
Immagine modello |
Immagine di ingresso |
Immagine di correlazione modello |
Identificazione delle corrispondenze
Tutto ciò che deve essere fatto a questo punto è decidere quali punti dell’immagine di correlazione del modello sono abbastanza buoni da essere considerati corrispondenze reali. Di solito si identificano come corrispondenze le posizioni che (simultaneamente) rappresentano la correlazione del modello:
- più forte di qualche valore di soglia predefinito (cioè più forte di 0.5)
- localmente massima (più forte della correlazione del template nei pixel vicini)
 |
 |
 |
|
Aree di correlazione del template sopra 0.75 |
Punti di correlazione template localmente massima |
Punti di correlazione template localmente massima superiore a 0,75 |
Sommario
È abbastanza facile esprimere il metodo descritto in Adaptive Vision Studio – abbiamo bisogno solo di due filtri integrati. Calcoleremo l’immagine di correlazione del modello usando il filtro ImageCorrelationImage, e poi identificheremo le corrispondenze usando ImageLocalMaxima – dobbiamo solo impostare il parametro inMinValue che taglierà i massimi locali deboli dai risultati, come discusso nella sezione precedente.
Anche se la tecnica introdotta è stata sufficiente a risolvere il problema considerato, possiamo notare i suoi importanti svantaggi:
- Le occorrenze del template devono preservare l’orientamento dell’immagine template di riferimento.
- Il metodo è inefficiente, poiché il calcolo dell’immagine di correlazione del template per immagini medio-grandi richiede tempo.
Nelle prossime sezioni discuteremo come questi problemi sono stati affrontati nelle tecniche avanzate di corrispondenza dei template: Grayscale-based Matching e Edge-based Matching.
Grayscale-based Matching, Edge-based Matching
Grayscale-based Matching è un algoritmo avanzato di Template Matching che estende l’idea originale del rilevamento di template basato sulla correlazione migliorandone l’efficienza e permettendo di cercare le occorrenze del template indipendentemente dal suo orientamento. Edge-based Matching migliora ulteriormente questo metodo limitando il calcolo alle aree del bordo dell’oggetto.
In questa sezione descriveremo i dettagli intrinseci di entrambi gli algoritmi. Nella prossima sezione (Filter toolset) spiegheremo come usare queste tecniche in Adaptive Vision Studio.
Image Pyramid
Image Pyramid è una serie di immagini, ogni immagine è il risultato del downsampling (ridimensionamento, in questo caso del fattore due) dell’elemento precedente.
|
 |
 |
|
Livello 0 (immagine di ingresso) |
Livello 1 |
Livello 2 |
Elaborazione piramidale
Le piramidi d’immagine possono essere applicate per migliorare l’efficienza del rilevamento basato sulla correlazione.basata sulla correlazione. L’osservazione importante è che il modello raffigurato nell’immagine di riferimento di solito è ancora distinguibile dopo un significativo downsampling dell’immagine (anche se, naturalmente, i dettagli fini vengono persi nel processo). Perciò possiamo identificare i candidati alla corrispondenza nell’immagine sottocampionata (e quindi molto più veloce da elaborare) al livello più alto della nostra piramide, e poi ripetere la ricerca sui livelli più bassi della piramide, ogni volta considerando solo le posizioni del template che hanno ottenuto un punteggio alto al livello precedente.
Ad ogni livello della piramide avremo bisogno di un’immagine adeguatamente sottocampionata del template di riferimento, cioè dovranno essere calcolate sia la piramide dell’immagine di input che quella dell’immagine del template.
 |
 |
 |
|
Livello 0 (immagine di riferimento del modello) |
Livello 1 |
Livello 2 |
Grayscale-based Matching
Anche se in alcune applicazioni l’orientamento degli oggetti è uniforme e fisso (come abbiamo visto nell’esempio della spina), è spesso il caso che gli oggetti che devono essere rilevati appaiano ruotati. Negli algoritmi di Template Matching la classica ricerca piramidale viene adattata per permettere la corrispondenza multiangolare, cioè l’identificazione di istanze ruotate del modello.
Questo si ottiene calcolando non solo una piramide dell’immagine del modello, ma un insieme di piramidi – una per ogni possibile rotazione del modello. Durante la ricerca della piramide sull’immagine di ingresso, l’algoritmo identifica le coppie (posizione del modello, orientamento del modello) piuttosto che le sole posizioni del modello. In modo simile allo schema originale, ad ogni livello della ricerca l’algoritmo verifica solo le coppie (posizione, orientamento) che hanno ottenuto un buon punteggio nel livello precedente (cioè sembravano corrispondere al modello nell’immagine di risoluzione inferiore).
 |
 |
|
|
Immagine modello |
Immagine di ingresso |
Risultati della corrispondenza multiangolo di corrispondenza |
La tecnica di corrispondenza piramidale insieme alla ricerca multi-angolo costituiscono il metodo di corrispondenza dei modelli basato sulla scala di grigi.
Matching basato sui bordi
Il Matching basato sui bordi migliora il Matching basato sulla scala di grigi precedentemente discusso usando un’osservazione cruciale – che la forma di qualsiasi oggetto è definita principalmente dalla forma dei suoi bordi. Pertanto, invece di far corrispondere l’intero modello, potremmo estrarre i suoi bordi e far corrispondere solo i pixel vicini, evitando così alcuni calcoli non necessari. Nelle applicazioni comuni l’aumento di velocità ottenuto è solitamente significativo.
| Matching basato sulla scala di grigi: | |
 |
 |
|---|---|---|---|
| Edge-based Matching: |  |
 |
 |
|
Diversi tipi di piramidi di template usate negli algoritmi di Template Matching. |
|||
Rispondere ai bordi dell’oggetto invece che all’oggetto nel suo insieme richiede una leggera modifica del metodo originale di corrispondenza piramidale: immaginiamo di abbinare un oggetto di colore uniforme posizionato su uno sfondo uniforme. Tutti i pixel del bordo dell’oggetto avrebbero la stessa intensità e l’algoritmo originale farebbe corrispondere l’oggetto ovunque ci sia un blob abbastanza grande del colore appropriato, e questo non è chiaramente ciò che vogliamo ottenere. Per risolvere questo problema, in Edge-based Matching è la direzione del gradiente (rappresentata come un colore nello spazio HSV per scopi illustrativi) dei pixel del bordo, non la loro intensità, che viene abbinata.
Filter Toolset
Adaptive Vision Studio fornisce un set di filtri che implementano sia Grayscale-based Matching che Edge-based Matching. Per l’elenco dei filtri si veda Template Matching filters.
Poiché l’immagine modello deve essere pre-elaborata prima della corrispondenza piramidale (abbiamo bisogno di calcolare le piramidi dell’immagine modello per tutte le rotazioni possibili), gli algoritmi sono divisi in due parti:
- Creazione del modello – in questo passo le piramidi dell’immagine modello sono calcolate e i risultati sono memorizzati in un modello – oggetto atomico che rappresenta tutti i dati necessari per eseguire la corrispondenza piramidale.
- Corrispondenza – in questo passo il modello viene usato per far corrispondere il modello all’immagine in ingresso.
Questa organizzazione dell’elaborazione rende possibile calcolare il modello una volta e riutilizzarlo più volte.
Filtri disponibili
Per entrambi i metodi Template Matching sono forniti due filtri, uno per ogni passo dell’algoritmo.
| Matching basato sulla scala di grigi | Matching basato sul bordo | |
|---|---|---|
| Creazione del modello: | 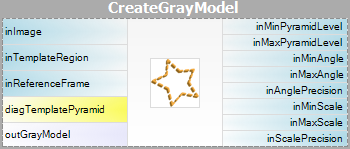 |
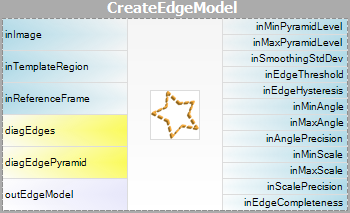 |
| Matching: | 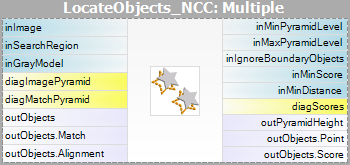 |
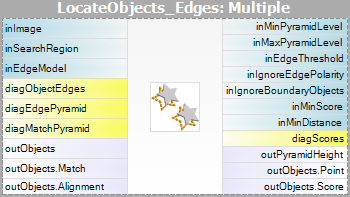 |
Si noti che l’uso dei filtri CreateGrayModel e CreateEdgeModel sarà necessario solo nelle applicazioni più avanzate. Altrimenti è sufficiente usare un solo filtro del passo Matching e creare il modello impostando il parametro inGrayModel o inEdgeModel del filtro. Per maggiori informazioni vedi Creazione di modelli per Template Matching.
La sfida principale nell’applicazione della tecnica Template Matching sta nell’attenta regolazione dei parametri del filtro, piuttosto che nella progettazione della struttura del programma.
Schema di applicazioni avanzate
Ci sono diversi tipi di applicazioni avanzate, per le quali la GUI interattiva per Template Matching non è sufficiente e l’utente deve usare direttamente il filtro CreateGrayModel o CreateEdgeModel. Per esempio:
- Quando la creazione del modello richiede una pre-elaborazione dell’immagine non banale.
- Quando abbiamo bisogno di un’intera serie di modelli creati automaticamente da un insieme di immagini.
- Quando l’utente finale dovrebbe essere in grado di definire i propri modelli nell’applicazione runtime (per esempio facendo una selezione su un’immagine di input).
Schema 1: Creazione del modello in un programma separato
Per i casi 1 e 2 è consigliabile implementare la creazione del modello in un macrofiltro Task separato, salvare il modello in un file AVDATA e poi collegare quel file all’input del filtro corrispondente nel programma principale:
| Creazione del modello: | Programma principale: |
|---|---|
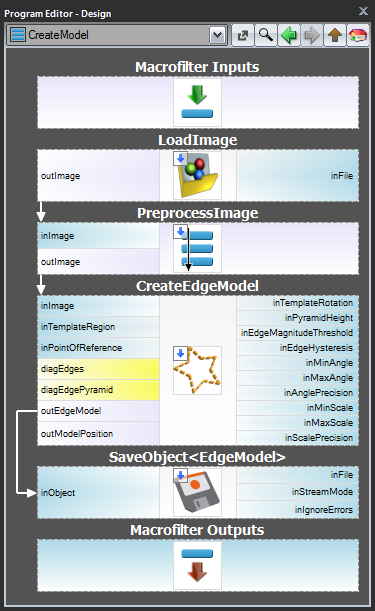 |
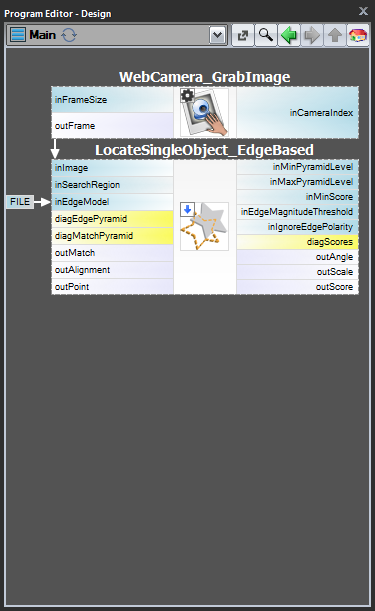 |
Quando questo programma è pronto, puoi eseguire il task “CreateModel” come programma in qualsiasi momento tu voglia creare il modello. Il collegamento al file di dati nell’input del filtro di corrispondenza non ha bisogno di modifiche, perché questo è solo un collegamento e ciò che viene cambiato è solo il file sul disco.
Schema 2: Creazione dinamica del modello
Per il caso 3, quando il modello deve essere creato dinamicamente, sia il filtro di creazione del modello che il filtro di corrispondenza devono essere nello stesso task. Il primo, tuttavia, dovrebbe essere eseguito in modo condizionale, quando un rispettivo evento HMI viene sollevato (ad esempio, l’utente clicca su un ImpulseButton o fa qualche azione del mouse in un VideoBox). Per rappresentare il modello, dovrebbe essere usato un registro di tipo EdgeModel? che memorizzerà l’ultimo modello (un’altra opzione è usare il filtro LastNotNil).Ecco un esempio di realizzazione con il modello che viene creato da un box predefinito su un’immagine di input quando viene cliccato un pulsante nell’HMI:
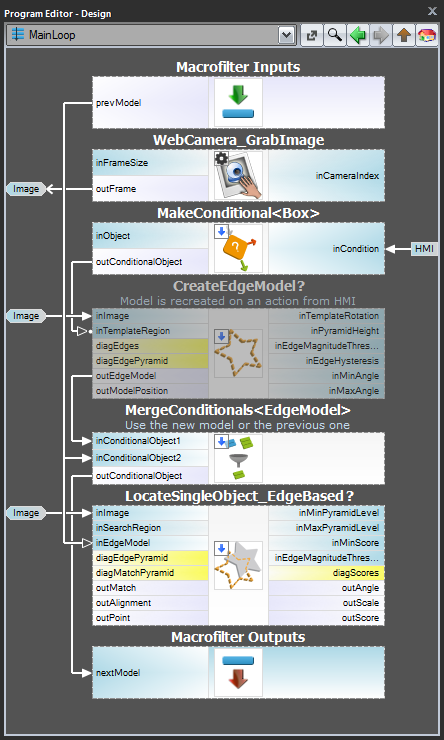
Creazione del modello
Altezza della piramide
Il parametro inPyramidHeight determina il numero di livelli di corrispondenza della piramide e dovrebbe essere impostato al numero maggiore per cui il modello è ancora riconoscibile sul livello più alto della piramide. Questo valore dovrebbe essere selezionato attraverso la sperimentazione interattiva utilizzando l’output diagnostico diagPatternPyramid (Grayscale-based Matching) o diagEdgePyramid (Edge-based Matching).
Nel seguente esempio il valore inPyramidHeight di 4 sarebbe troppo alto (per entrambi i metodi), poiché la struttura del template è completamente persa su questo livello della piramide. Anche il valore di 3 sembra un po’ eccessivo (soprattutto nel caso di Edge-based Matching) mentre il valore di 2 sarebbe sicuramente una scelta sicura.
| Livello 0 | Livello 1 | Livello 2 | Livello 3 | Livello 4 | |
|---|---|---|---|---|---|
| Matching basato sulla scala di grigi (diagPatternPyramid): |
 |
 |
 |
 |
 |
| Corrispondenza basata sul bordo (diagEdgePyramid): |
 |
 |
 |
 |
 |
Angle Range
I parametri inMinAngle, inMaxAngle determinano la gamma di orientamenti del modello che saranno considerati nel processo di corrispondenza. Per esempio (i valori tra parentesi rappresentano le coppie di valori inMinAngle, inMaxAngle):
- (0.0, 360.0): tutte le rotazioni sono considerate (valore predefinito)
- (-15.0, 15.0): le occorrenze del modello possono deviare dall’orientamento del modello di riferimento al massimo di 15.0 gradi (in ogni direzione)
- (0.0, 0.0): ci si aspetta che le occorrenze del modello conservino l’orientamento del modello di riferimento
Un’ampia gamma di possibili orientamenti introduce una quantità significativa di overhead (sia nell’uso della memoria che nel tempo di calcolo), quindi è consigliabile limitare la gamma quando possibile.
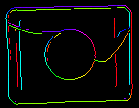
Impostazioni per il rilevamento dei bordi (solo corrispondenza basata sui bordi)
I parametri inEdgeMagnitudeThreshold, inEdgeHysteresis del filtro CreateEdgeModel determinano le impostazioni della soglia di isteresi usata per rilevare i bordi nell’immagine modello. Più basso è il valore di inEdgeMagnitudeThreshold, più bordi saranno rilevati nell’immagine modello. Questi parametri dovrebbero essere impostati in modo che tutti i bordi significativi del modello siano rilevati e la quantità di bordi ridondanti (rumore) nel risultato sia il più limitata possibile. Similmente all’altezza della piramide, le soglie di rilevamento dei bordi dovrebbero essere selezionate attraverso una sperimentazione interattiva usando l’output diagnostico diagEdgePyramid – questa volta dobbiamo guardare solo l’immagine al livello più basso.
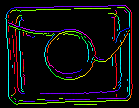 |
 |
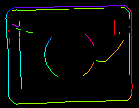 |
|
(15.0, 30.0) – quantità eccessiva di rumore |
(40.0, 60.0) – OK |
(60.0, 70.0) – bordi significativi persi |
Il filtro CreateEdgeModel non permetterà di creare un modello in cui non sono stati rilevati bordi in cima alla piramide (il che significa che non solo alcuni bordi significativi sono stati persi, ma tutti), dando in tal caso un errore. Ogni volta che ciò accade, l’altezza della piramide, o le soglie dei bordi, o entrambe, dovrebbero essere ridotte.
Matching
Il parametro inMinScore determina quanto permissivo sarà l’algoritmo nella verifica dei candidati alla corrispondenza – più alto è il valore, meno risultati saranno restituiti. Questo parametro dovrebbe essere impostato attraverso la sperimentazione interattiva su un valore abbastanza basso da assicurare che tutte le corrispondenze corrette vengano restituite, ma non molto più basso, poiché un valore troppo basso rallenta l’algoritmo e può causare la comparsa di false corrispondenze nei risultati.
Suggerimenti e migliori pratiche
Come selezionare un metodo?
Per la maggior parte delle applicazioni il metodo Edge-based Matching sarà sia più robusto che più efficiente del Grayscale-based Matching. Quest’ultimo dovrebbe essere considerato solo se il modello considerato ha aree di transizione di colore lisce che non sono definite da bordi distinguibili, ma che devono comunque essere abbinate.
| Precedente: Shape Fitting | Prossimo: Sistemi di Coordinate Locali |