
Datatatransformation er et af de grundlæggende trin i databehandlingen. Da jeg først lærte teknikken til skalering af funktioner, blev udtrykkene skalere, standardisere og normalisere ofte brugt. Det var dog ret svært at finde oplysninger om, hvilke af dem jeg skulle bruge, og også hvornår de skulle bruges. Derfor vil jeg forklare følgende centrale aspekter i denne artikel:
- forskellen mellem standardisering og normalisering
- hvornår skal man bruge standardisering og hvornår skal man bruge normalisering
- hvordan man anvender feature scaling i Python
Hvad betyder feature scaling?
I praksis støder vi ofte på forskellige typer af variabler i det samme datasæt. Et væsentligt problem er, at variablernes rækkevidde kan være meget forskellig. Ved at bruge den oprindelige skala kan der lægges større vægt på variabler med et stort interval. For at løse dette problem er vi nødt til at anvende teknikken til omskalering af funktioner på uafhængige variabler eller funktioner i data i forbehandlingen af data. Begreberne normalisering og standardisering bruges nogle gange i flæng, men de refererer normalt til forskellige ting.
Målet med at anvende Feature Scaling er at sørge for, at funktionerne er på næsten samme skala, så hver funktion er lige vigtig og gør det lettere at behandle med de fleste ML-algoritmer.
Eksempel
Dette er et datasæt, der indeholder en uafhængig variabel (Købt) og 3 afhængige variabler (Land, Alder og Løn). Vi kan let konstatere, at variablerne ikke er på samme skala, fordi intervallet for alder er fra 27 til 50, mens intervallet for løn går fra 48 K til 83 K. Området for løn er meget bredere end intervallet for alder. Dette vil give nogle problemer i vores modeller, da mange maskinlæringsmodeller som f.eks. k-means clustering og klassificering af nærmeste nabo er baseret på den euklidiske afstand.
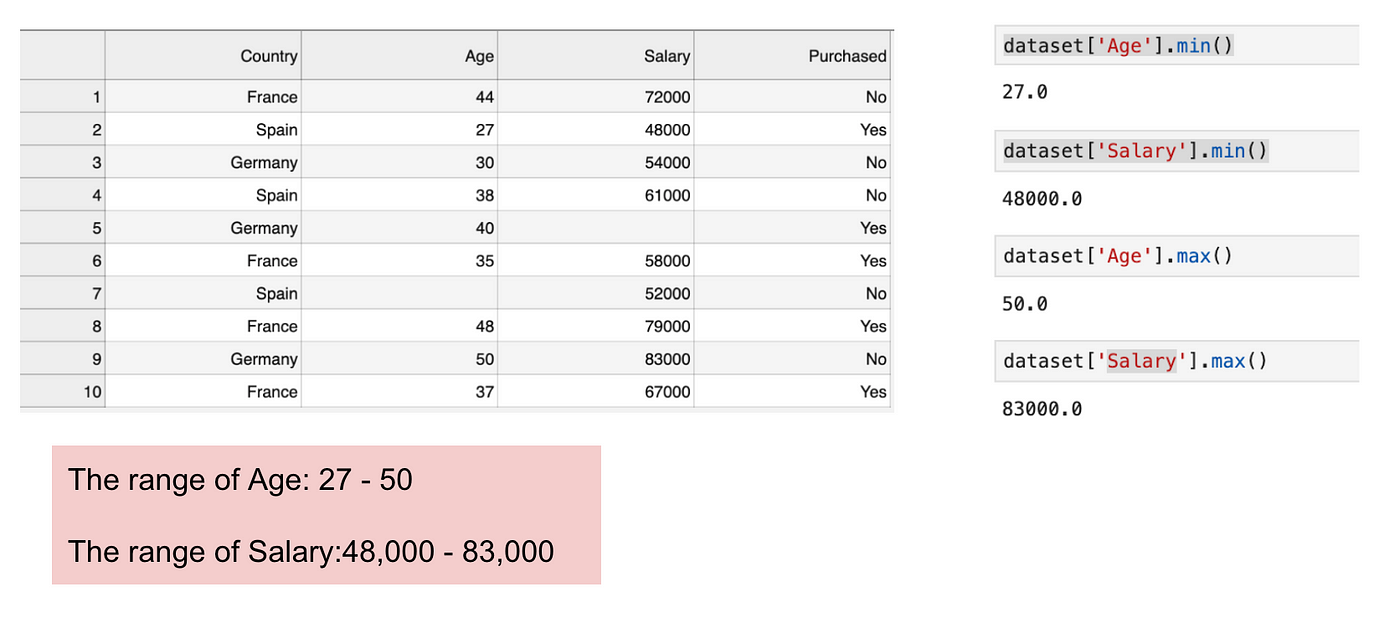
Fokus på alder og løn.
Når vi beregner ligningen for euklidisk afstand, er antallet af (x2-x1)² meget større end antallet af (y2-y1)², hvilket betyder, at den euklidiske afstand vil blive domineret af lønnen, hvis vi ikke anvender feature scaling. Forskellen i alder bidrager mindre til den samlede forskel. Derfor bør vi anvende Feature Scaling for at bringe alle værdier til de samme størrelser og dermed løse dette problem. For at gøre dette er der primært to metoder kaldet standardisering og normalisering.

Euklidisk afstandsanvendelse.
Standardisering
Resultatet af standardisering (eller Z-score-normalisering) er, at funktionerne vil blive omskaleret for at sikre, at middelværdien og standardafvigelsen bliver henholdsvis 0 og 1. Ligningen er vist nedenfor:
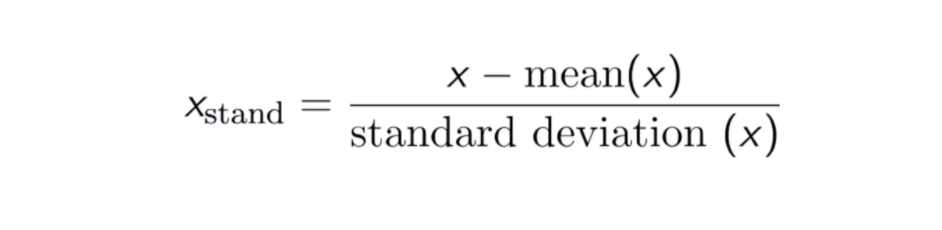
Denne teknik er at omskalere features værdi med fordelingsværdien mellem 0 og 1 er nyttig for de optimeringsalgoritmer, såsom gradientafstigning, der anvendes inden for maskinlæringsalgoritmer, der vægter input (f.eks. regression og neurale netværk). Omskalering bruges også til algoritmer, der anvender afstandsmålinger, f.eks. K-Nearest-Neighbours (KNN).
Kode
#Import libraryfrom sklearn.preprocessing import StandardScalersc_X = StandardScaler()sc_X = sc_X.fit_transform(df)#Convert to table format - StandardScaler sc_X = pd.DataFrame(data=sc_X, columns=)sc_X
Max-Min Normalisering
En anden almindelig fremgangsmåde er den såkaldte Max-Min Normalisering (Min-Max skalering). Denne teknik går ud på at omskalere funktioner med en fordelingsværdi mellem 0 og 1. For hver funktion bliver den mindste værdi af den pågældende funktion omdannet til 0, og den største værdi bliver omdannet til 1. Den generelle ligning er vist nedenfor:
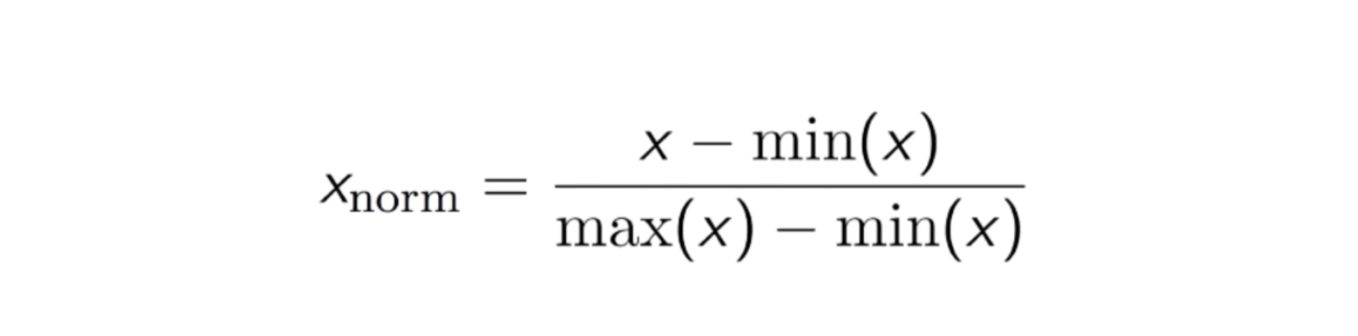
Ligningen for Max-Min Normalisering.
Kode
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()scaler.fit(df)scaled_features = scaler.transform(df)#Convert to table format - MinMaxScalerdf_MinMax = pd.DataFrame(data=scaled_features, columns=)
Standardisering vs. Max-Min Normalisering
I modsætning til standardisering vil vi opnå mindre standardafvigelser gennem processen med Max-Min Normalisering. Lad mig illustrere mere på dette område ved hjælp af ovenstående datasæt.
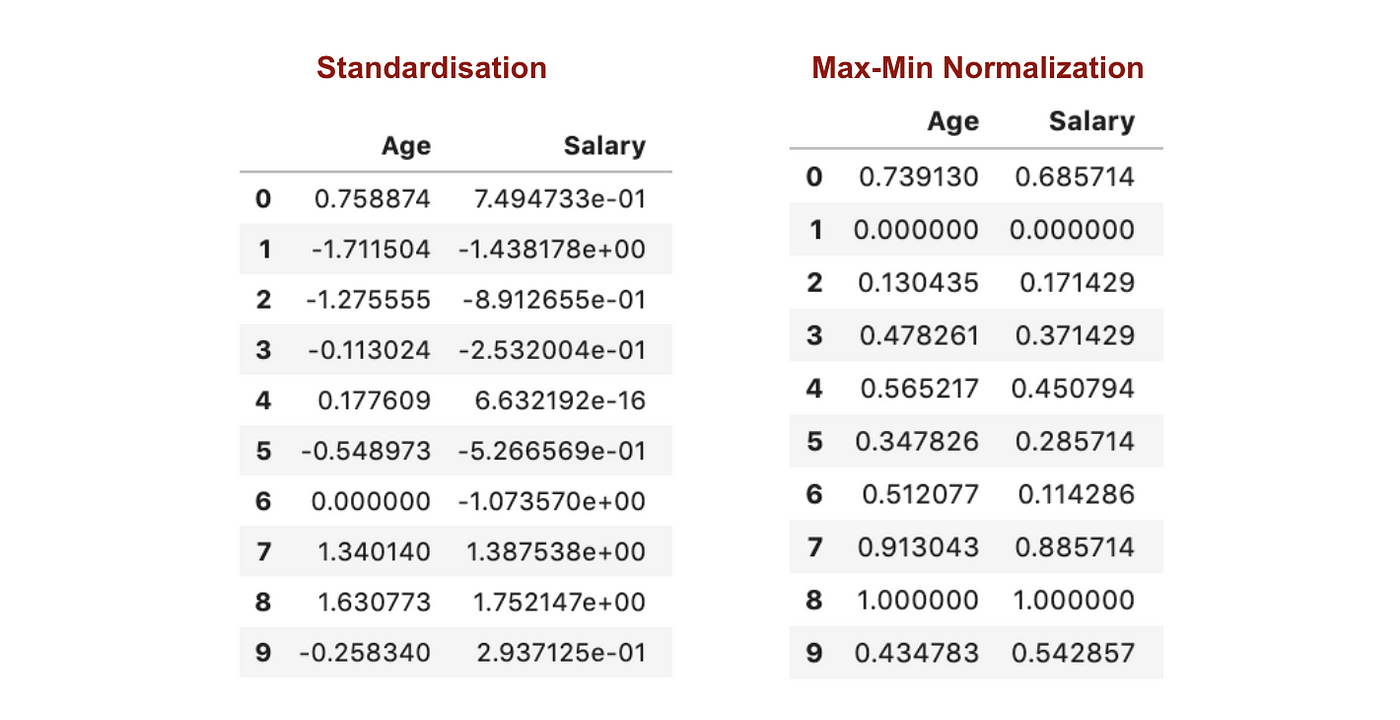
Efter Feature scaling.
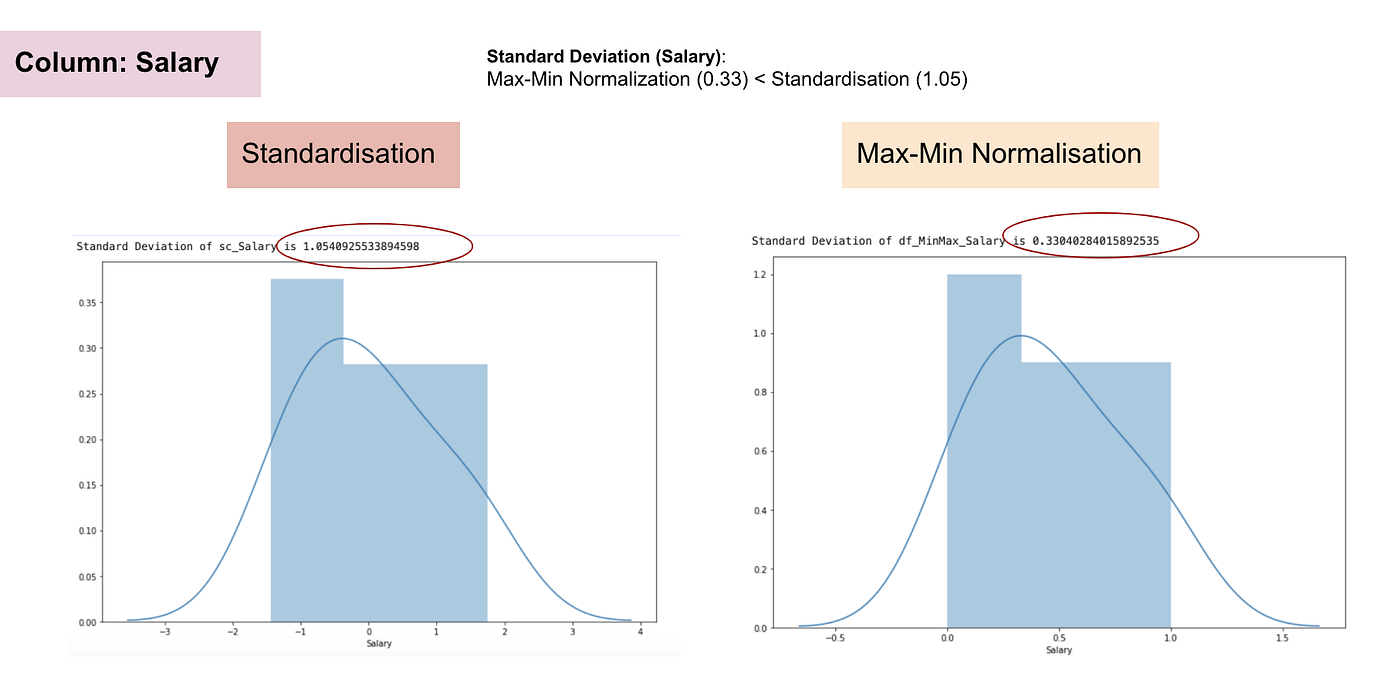
Normalfordeling og standardafvigelse for Løn.
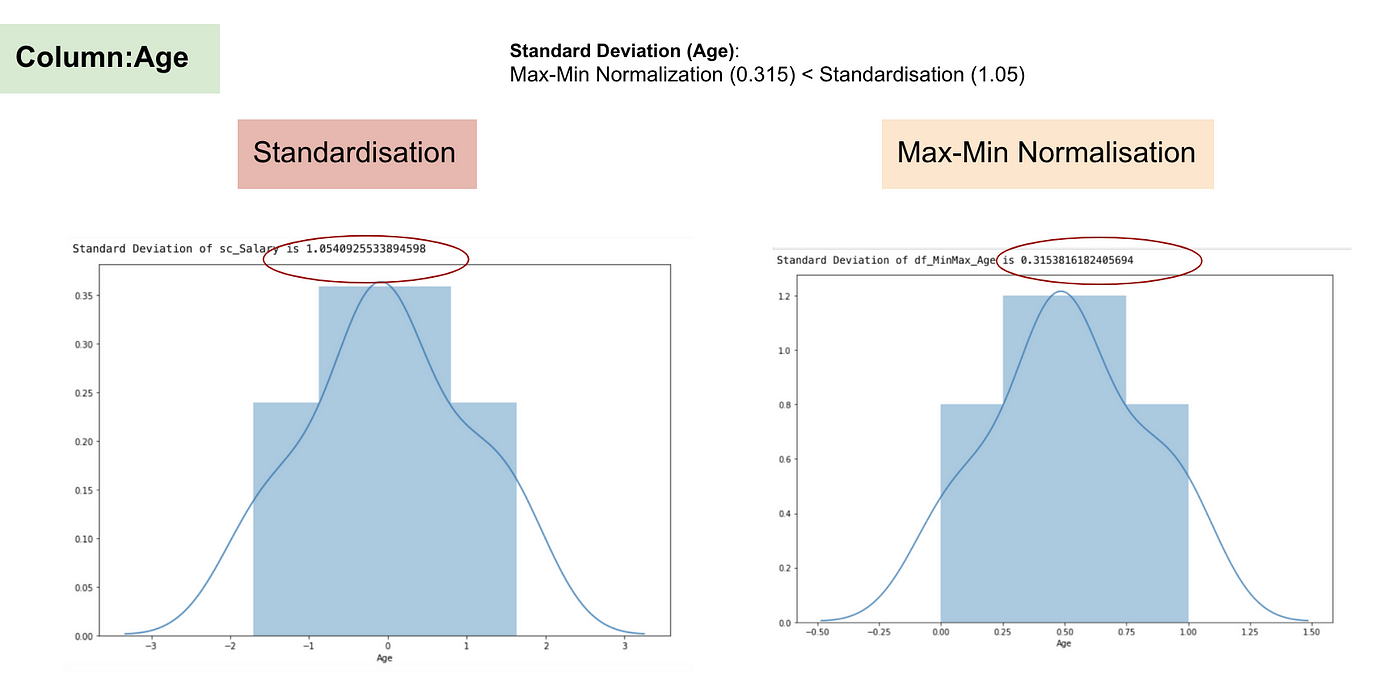
Normalfordeling og standardafvigelse for Alder.
Fra ovenstående grafer kan vi tydeligt se, at anvendelsen af Max-Min-nomaralisering i vores datasæt har genereret mindre standardafvigelser (Løn og Alder) end ved anvendelse af standardiseringsmetoden. Det indebærer, at dataene er mere koncentreret omkring middelværdien, hvis vi skalerer data ved hjælp af Max-Min Nomaralisation.
Som følge heraf vil normalisering af dine data, hvis du har outliers i din feature (kolonne), skalere de fleste af dataene til et lille interval, hvilket betyder, at alle features vil have den samme skala, men ikke håndterer outliers godt. Normalisering er mere robust over for outliers, og i mange tilfælde er den at foretrække frem for Max-Min-normalisering.
Når funktionsskalering har betydning

Somme maskinlæringsmodeller er grundlæggende baseret på afstandsmatrix, også kendt som den afstandsbaserede klassifikator, f.eks. K-Nærmeste Naboer, SVM og neurale netværk. Funktionskalering er ekstremt vigtig for disse modeller, især når funktionernes rækkevidde er meget forskellig. Ellers vil funktioner med et stort interval have stor indflydelse på beregningen af afstanden.
Max-Min-normalisering giver os typisk mulighed for at transformere data med varierende skalaer, så ingen specifik dimension vil dominere statistikken, og det kræver ikke, at man foretager en meget stærk antagelse om fordelingen af dataene, som f.eks. k-nearest neighbours og kunstige neurale netværk. Normalisering behandler dog ikke outliners særlig godt. Tværtimod giver normalisering brugerne mulighed for bedre at håndtere outliers og lette konvergensen for visse beregningsalgoritmer som f.eks. gradientafstigning. Derfor foretrækker vi normalt standardisering frem for Min-Max-normalisering.
Eksempel: Hvilke algoritmer har brug for funktionsskalering
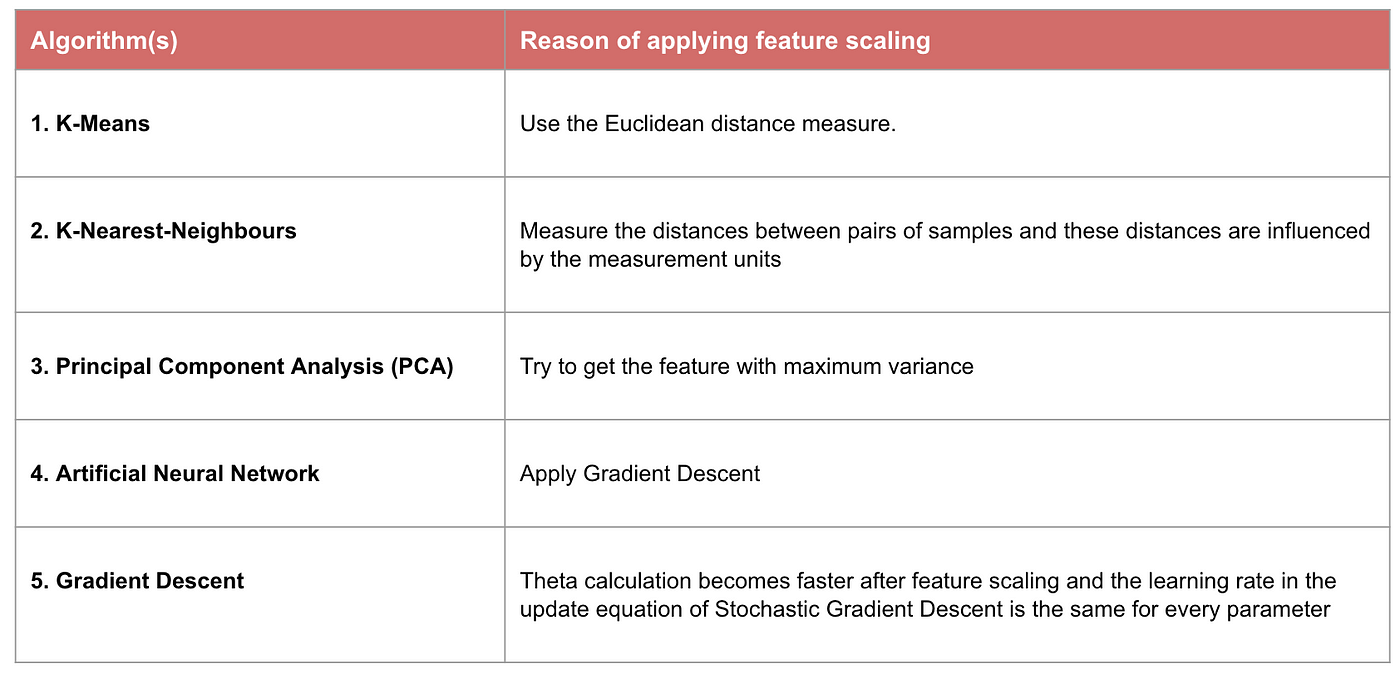
Bemærk: Hvis en algoritme ikke er afstandsbaseret, er funktionsskalering uvæsentlig, herunder Naive Bayes, lineær diskriminantanalyse og træbaserede modeller (gradient boosting, random forest osv.).
Summarum: Nu bør du vide
- det formål med at bruge Feature Scaling
- forskellen mellem standardisering og normalisering
- de algoritmer, der skal anvende standardisering eller normalisering
- anvendelse af feature scaling i Python
Vil du finde koden og datasættet her.