
La trasformazione dei dati è uno dei passi fondamentali nella parte di elaborazione dei dati. Quando ho imparato per la prima volta la tecnica del feature scaling, i termini scale, standardise e normalise sono spesso usati. Tuttavia, era piuttosto difficile trovare informazioni su quale di essi dovessi usare e anche quando usarli. Pertanto, spiegherò i seguenti aspetti chiave in questo articolo:
- la differenza tra Standardizzazione e Normalizzazione
- quando usare la Standardizzazione e quando usare la Normalizzazione
- come applicare il feature scaling in Python
Cosa significa Feature Scaling?
In pratica, spesso incontriamo diversi tipi di variabili nello stesso set di dati. Un problema significativo è che la gamma delle variabili può essere molto diversa. Usare la scala originale può mettere più pesi sulle variabili con un ampio intervallo. Per affrontare questo problema, dobbiamo applicare la tecnica di ridimensionamento delle caratteristiche alle variabili indipendenti o alle caratteristiche dei dati nella fase di pre-elaborazione dei dati. I termini normalizzazione e standardizzazione sono a volte usati in modo intercambiabile, ma di solito si riferiscono a cose diverse.
L’obiettivo dell’applicazione del Feature Scaling è quello di assicurarsi che le caratteristiche siano quasi sulla stessa scala in modo che ogni caratteristica sia ugualmente importante e rendere più facile l’elaborazione da parte della maggior parte degli algoritmi di ML.
Esempio
Questo è un dataset che contiene una variabile indipendente (Purchased) e 3 variabili dipendenti (Country, Age, and Salary). Possiamo facilmente notare che le variabili non sono sulla stessa scala perché il range dell’Età va da 27 a 50, mentre il range dello Stipendio va da 48 K a 83 K. Il range dello Stipendio è molto più ampio del range dell’Età. Questo causerà alcuni problemi nei nostri modelli poiché molti modelli di apprendimento automatico come il clustering k-means e la classificazione dei vicini più vicini sono basati sulla distanza euclidea.
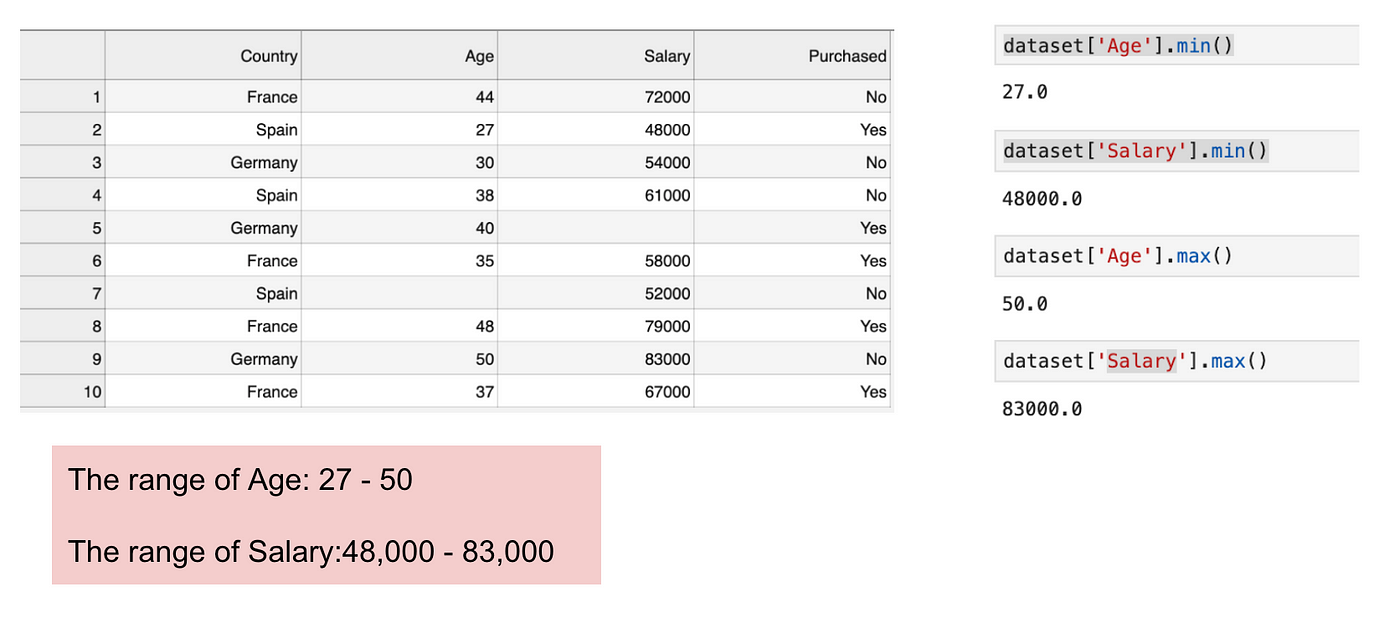
Focalizzandosi su età e stipendio.
Quando calcoliamo l’equazione della distanza euclidea, il numero di (x2-x1)² è molto più grande del numero di (y2-y1)² che significa che la distanza euclidea sarà dominata dallo stipendio se non applichiamo il feature scaling. La differenza di età contribuisce meno alla differenza complessiva. Pertanto, dovremmo usare il Feature Scaling per portare tutti i valori alle stesse grandezze e, quindi, risolvere questo problema. Per fare questo, ci sono principalmente due metodi chiamati Standardizzazione e Normalizzazione.

Applicazione della distanza euclidea.
Standardizzazione
Il risultato della standardizzazione (o normalizzazione Z-score) è che le caratteristiche saranno riscalate per garantire che la media e la deviazione standard siano rispettivamente 0 e 1. L’equazione è mostrata qui sotto:
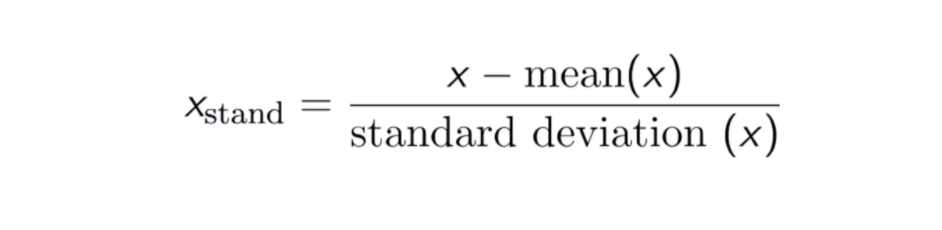
Questa tecnica è quella di ridimensionare il valore delle caratteristiche con il valore della distribuzione tra 0 e 1 è utile per gli algoritmi di ottimizzazione, come la discesa del gradiente, che sono utilizzati all’interno degli algoritmi di apprendimento automatico che pesano gli input (ad esempio, regressione e reti neurali). Il rescaling è anche usato per algoritmi che usano misure di distanza, per esempio, K-Nearest-Neighbours (KNN).
Codice
#Import libraryfrom sklearn.preprocessing import StandardScalersc_X = StandardScaler()sc_X = sc_X.fit_transform(df)#Convert to table format - StandardScaler sc_X = pd.DataFrame(data=sc_X, columns=)sc_X
Max-Min Normalization
Un altro approccio comune è il cosiddetto Max-Min Normalization (Min-Max scaling). Questa tecnica consiste nel ridimensionare le caratteristiche con un valore di distribuzione tra 0 e 1. Per ogni caratteristica, il valore minimo di quella caratteristica viene trasformato in 0, e il valore massimo viene trasformato in 1. L’equazione generale è mostrata qui sotto:
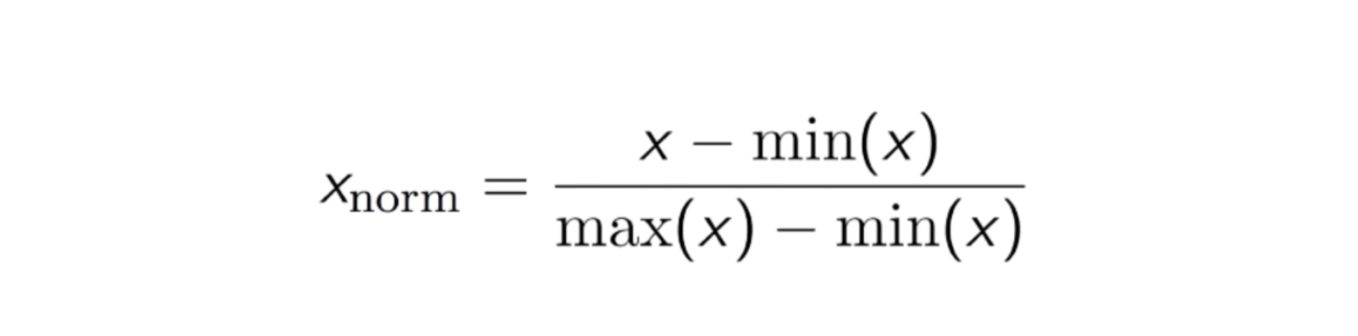
L’equazione della Max-Min Normalization.
Codice
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()scaler.fit(df)scaled_features = scaler.transform(df)#Convert to table format - MinMaxScalerdf_MinMax = pd.DataFrame(data=scaled_features, columns=)
Standardizzazione vs Normalizzazione Max-Min
Al contrario della standardizzazione, otterremo deviazioni standard minori attraverso il processo di Normalizzazione Max-Min. Permettetemi di illustrare di più in quest’area usando il set di dati di cui sopra.
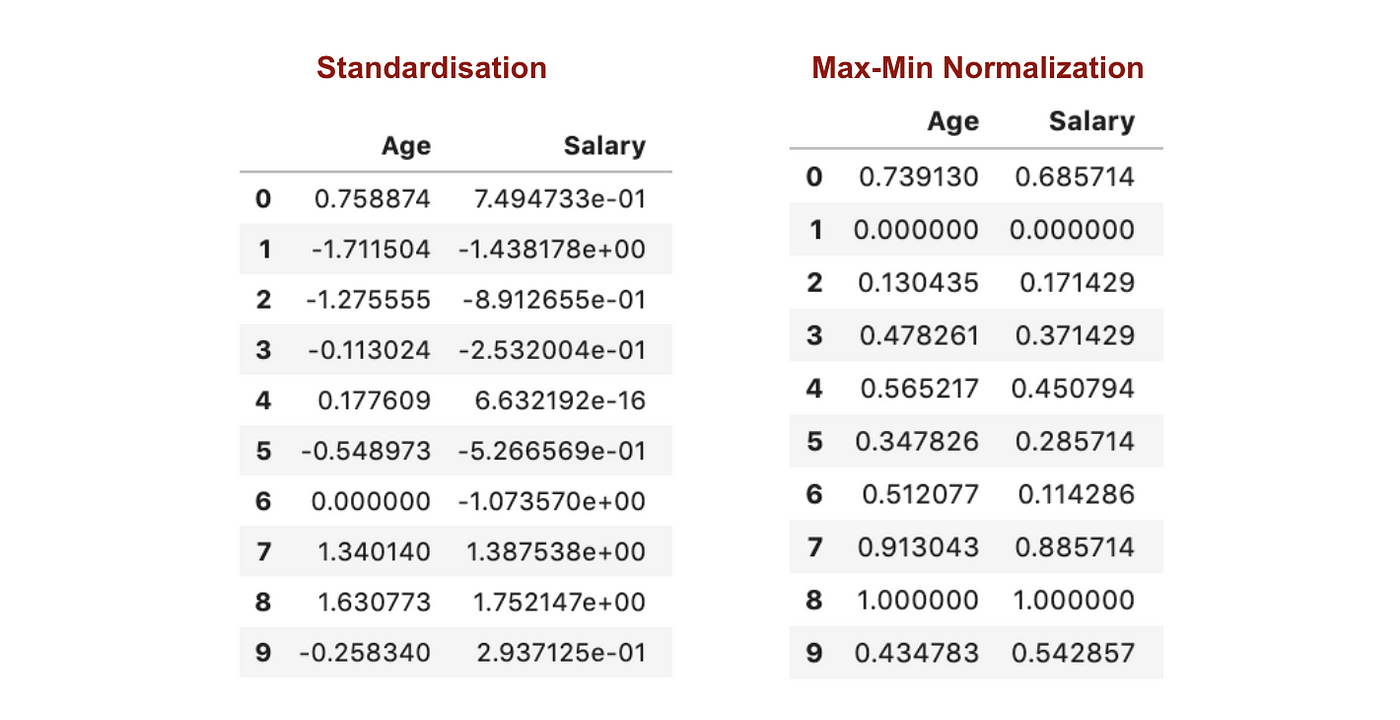
Dopo il Feature scaling.
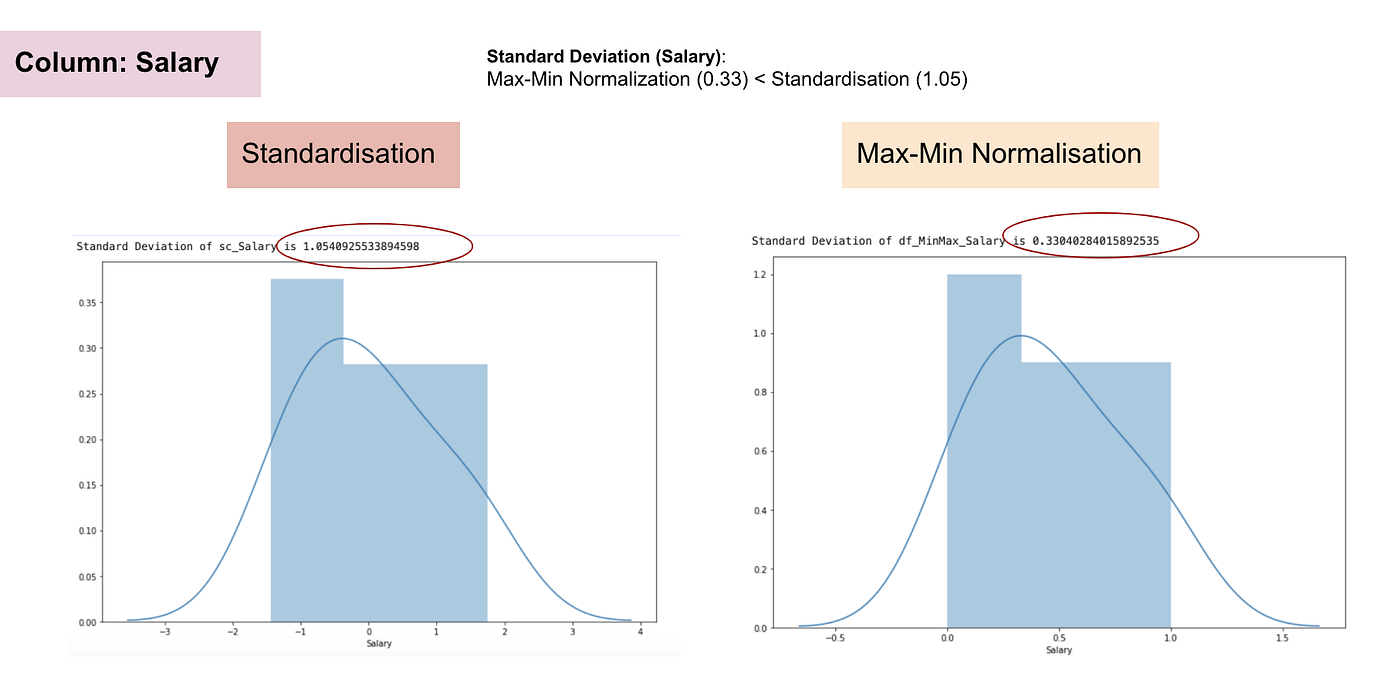
Distribuzione normale e deviazione standard dello stipendio.
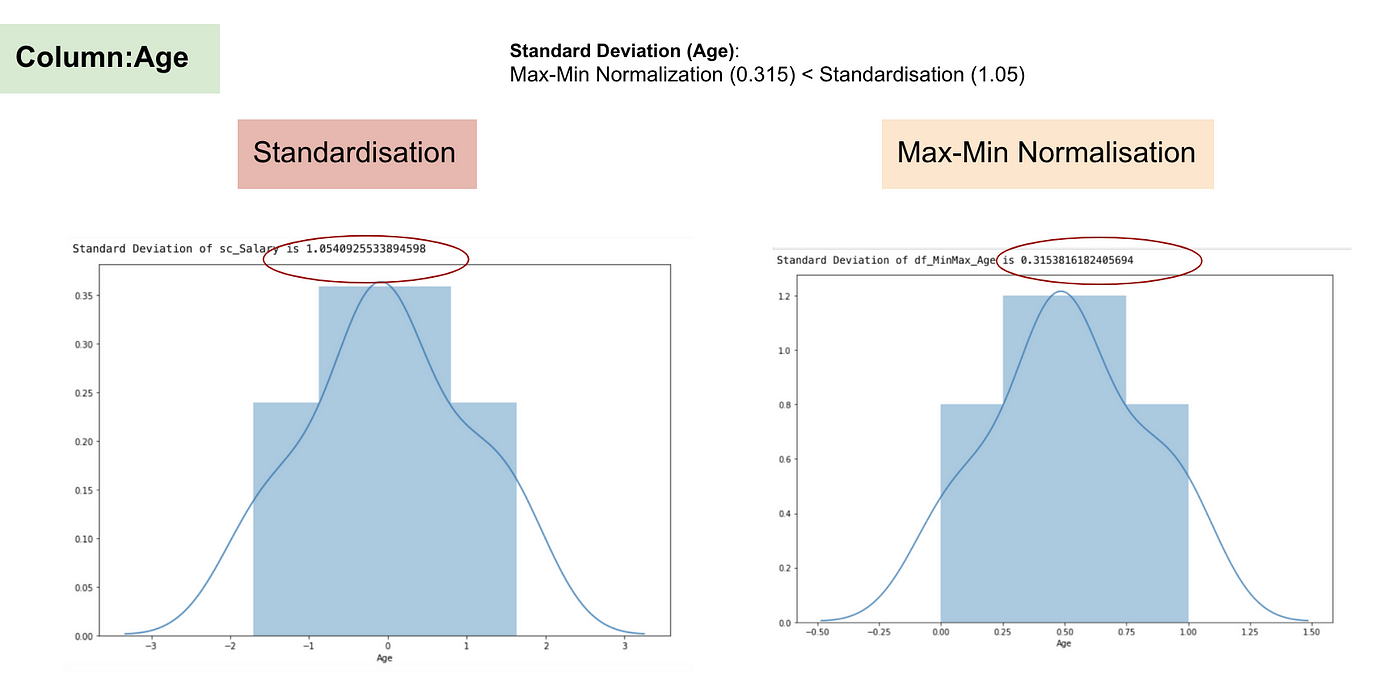
Distribuzione normale e deviazione standard dell’età.
Dai grafici di cui sopra, possiamo chiaramente notare che l’applicazione della nomaralizzazione Max-Min nel nostro set di dati ha generato deviazioni standard (stipendio ed età) più piccole rispetto al metodo della standardizzazione. Ciò implica che i dati sono più concentrati intorno alla media se scaliamo i dati usando la Max-Min Nomaralisation.
Come risultato, se avete outlier nella vostra caratteristica (colonna), la normalizzazione dei dati scalerà la maggior parte dei dati ad un piccolo intervallo, il che significa che tutte le caratteristiche avranno la stessa scala ma non gestisce bene gli outlier. La normalizzazione è più robusta agli outliers, e in molti casi, è preferibile alla normalizzazione Max-Min.
Quando il Feature Scaling conta

Alcuni modelli di apprendimento automatico sono fondamentalmente basati sulla matrice di distanza, anche conosciuta come classificatore basato sulla distanza, per esempio, K-Nearest-Neighbours, SVM, e Rete Neurale. La scalatura delle caratteristiche è estremamente essenziale per questi modelli, specialmente quando la gamma delle caratteristiche è molto diversa. Altrimenti, le caratteristiche con un grande intervallo avranno una grande influenza nel calcolo della distanza.
Max-Min Normalisation tipicamente ci permette di trasformare i dati con scale variabili in modo che nessuna dimensione specifica domini le statistiche, e non richiede di fare un’assunzione molto forte sulla distribuzione dei dati, come k-nearest neighbours e reti neurali artificiali. Tuttavia, la Normalizzazione non tratta molto bene gli outliner. Al contrario, la normalizzazione permette di gestire meglio gli outlier e facilitare la convergenza per alcuni algoritmi di calcolo come la discesa del gradiente. Pertanto, di solito preferiamo la standardizzazione alla normalizzazione Min-Max.
Esempio: Quali algoritmi hanno bisogno del feature scaling
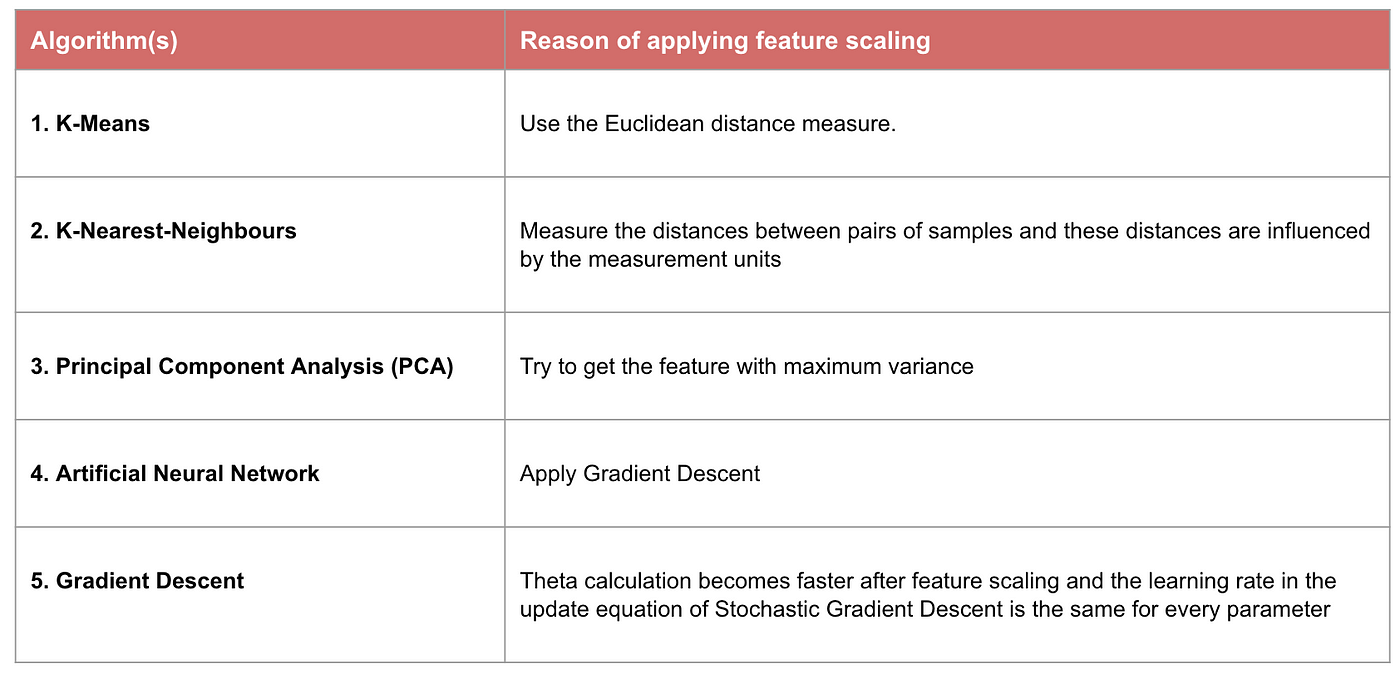
Nota: Se un algoritmo non è basato sulla distanza, il feature scaling non è importante, inclusi Naive Bayes, Linear Discriminant Analysis, e modelli Tree-Based (gradient boosting, random forest, ecc.).
Sommario: Ora dovresti sapere
- l’obiettivo di usare il Feature Scaling
- la differenza tra Standardizzazione e Normalizzazione
- gli algoritmi che hanno bisogno di applicare la Standardizzazione o la Normalizzazione
- applicare il feature scaling in Python
Per favore trova il codice e il dataset qui.