Door Derrick Mwiti, Data Analyst

Opmerking van de redacteur: Deze tutorial illustreert hoe je aan de slag kunt met het voorspellen van tijdreeksen met LSTM-modellen. Beursgegevens zijn hiervoor een goede keuze omdat ze regelmatig voorkomen en voor iedereen beschikbaar zijn. Beschouw dit niet als financieel advies en gebruik het niet om zelf transacties te doen.
In deze tutorial bouwen we een Python deep learning model dat het toekomstige gedrag van aandelenkoersen zal voorspellen. We gaan ervan uit dat de lezer bekend is met de concepten van deep learning in Python, met name Long Short-Term Memory.
Hoewel het voorspellen van de werkelijke prijs van een aandeel een zware klim is, kunnen we een model bouwen dat zal voorspellen of de prijs omhoog of omlaag zal gaan. De gegevens en het notitieblok die voor deze tutorial zijn gebruikt, zijn hier te vinden. Het is belangrijk op te merken dat er altijd andere factoren zijn die de koersen van aandelen beïnvloeden, zoals de politieke sfeer en de markt. We zullen ons in deze tutorial echter niet op die factoren richten.
Inleiding
LSTM’s zijn zeer krachtig in sequentievoorspellingsproblemen omdat ze in staat zijn informatie uit het verleden op te slaan. Dit is belangrijk in ons geval omdat de vorige prijs van een aandeel cruciaal is voor het voorspellen van de toekomstige prijs.
We beginnen met het importeren van NumPy voor wetenschappelijke berekeningen, Matplotlib voor het plotten van grafieken, en Pandas om te helpen bij het laden en manipuleren van onze datasets.
De dataset laden
De volgende stap is het laden van onze trainingsdataset en het selecteren van de Open en Highkolommen die we in onze modellering zullen gebruiken.
We controleren de kop van onze dataset om ons een indruk te geven van het soort dataset waarmee we werken.
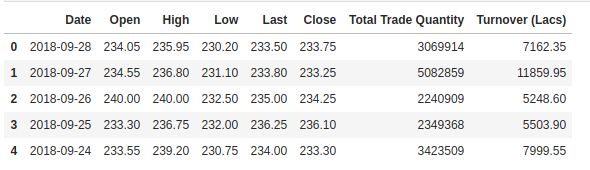
De Open-kolom is de startprijs, terwijl de Close-kolom de uiteindelijke prijs van een aandeel op een bepaalde handelsdag is. De kolommen High en Low vertegenwoordigen de hoogste en laagste prijzen voor een bepaalde dag.
Feature Scaling
Vanuit eerdere ervaring met deep learning-modellen weten we dat we onze gegevens moeten schalen voor optimale prestaties. In ons geval zullen we Scikit- Learn’s MinMaxScaler gebruiken en onze dataset schalen naar getallen tussen nul en één.
Gegevens creëren met timesteps
LSTM’s verwachten dat onze gegevens in een specifiek formaat zijn, meestal een 3D-array. We beginnen met het maken van data in 60 timesteps en converteren die naar een array met NumPy. Vervolgens converteren we de data in een 3D-dimensie array met X_train samples, 60 timestamps, en een feature bij elke stap.
Bouwen van de LSTM
Om de LSTM te bouwen, moeten we een aantal modules uit Keras importeren:
-
Sequentialvoor het initialiseren van het neurale netwerk -
Densevoor het toevoegen van een dicht verbonden neurale netwerklaag -
LSTMvoor het toevoegen van de Long Short-Term Memory-laag -
Dropoutvoor het toevoegen van uitvallagen die overfitting voorkomen
We voegen de LSTM-laag toe en voegen later een paar Dropout lagen toe om overfitting te voorkomen. We voegen de LSTM-laag toe met de volgende argumenten:
- 50 eenheden die de dimensionaliteit van de uitvoerruimte is
-
return_sequences=Truedie bepaalt of de laatste uitvoer in de uitvoerreeks wordt teruggegeven, of de volledige reeks -
input_shapeals de vorm van onze trainingsset.
Bij het definiëren van de Dropout lagen, specificeren we 0,2, wat betekent dat 20% van de lagen zal worden weggelaten. Daarna voegen wij de Dense laag toe die de output van 1 eenheid specificeert. Hierna compileren wij ons model met de populaire adam optimizer en stellen het verlies in op mean_squarred_error. Dit berekent het gemiddelde van de gekwadrateerde fouten. Vervolgens passen we het model om te draaien op 100 epochs met een batchgrootte van 32.
Voorspellen van toekomstige aandelen met behulp van de testset
Eerst moeten we de testset importeren die we zullen gebruiken om onze voorspellingen op te baseren.
Om toekomstige aandelenprijzen te voorspellen, moeten we een paar dingen doen na het inladen van de testset:
- Samenvoeging van de trainingsset en de testset op de 0-as.
- Stel de tijdstap in op 60 (zoals eerder gezien)
- Gebruik
MinMaxScalerom de nieuwe dataset te transformeren - Reshape de dataset zoals eerder gedaan
Na het maken van de voorspellingen gebruiken we inverse_transform om de aandelenkoersen terug te krijgen in normaal leesbaar formaat.
Plotten van de resultaten
Ten slotte gebruiken we Matplotlib om het resultaat van de voorspelde en de echte aandelenkoers te visualiseren.
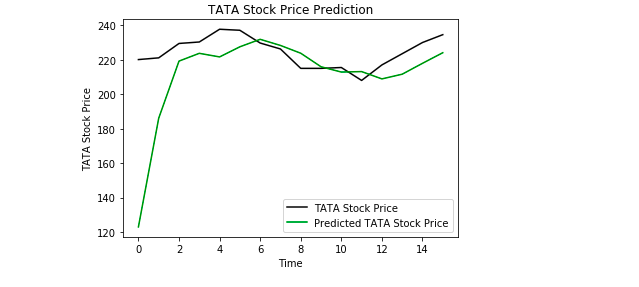
Van de plot kunnen we zien dat de echte aandelenkoers omhoog ging terwijl ons model ook voorspelde dat de aandelenkoers omhoog zal gaan. Dit laat duidelijk zien hoe krachtig LSTM’s zijn voor het analyseren van tijdreeksen en sequentiële gegevens.
Conclusie
Er zijn een paar andere technieken om aandelenkoersen te voorspellen, zoals voortschrijdende gemiddelden, lineaire regressie, K-Nearest Neighbours, ARIMA en Prophet. Dit zijn technieken die je zelf kunt testen en vergelijken met de Keras LSTM. Als je meer wilt leren over Keras en deep learning kun je mijn artikelen daarover hier en hier vinden.
Discussieer deze post op Reddit en Hacker News.
Bio: Derrick Mwiti is een data-analist, een schrijver, en een mentor. Hij is gedreven door het leveren van geweldige resultaten in elke taak, en is een mentor bij Lapid Leaders Africa.
Original. Herplaatst met toestemming.
Gerelateerd:
- Inleiding tot Deep Learning met Keras
- Inleiding tot PyTorch voor Deep Learning
- De Keras 4 stappen workflow