Bestandsopslag is een belangrijke functie die nodig is in meerdere processen in verschillende soorten toepassingen. Het bestaan van processen zoals Content Delivery Networks (CDNs), opgezet via cloud-opties van derden zoals Amazon Web Services, en lokale opties voor bestandsopslag hebben het altijd gemakkelijker gemaakt om een dergelijke functie te bouwen.
Het concept van het direct opslaan van bestanden in een database door middel van een enkele API-aanroep intrigeerde me echter al een hele tijd. Dat is waar GridFS voor mij in beeld kwam.

GridFS – A Layman’s Understanding
MongoDB has a driver specification to upload and retrieve files from it called GridFS. GridFS maakt het mogelijk om bestanden op te slaan en op te halen, inclusief bestanden die de BSON-documentlimiet van 16 MB overschrijden.
GridFS neemt in principe een bestand en splitst het op in meerdere chunks die als individuele documenten in twee collecties worden opgeslagen:
- de
chunkcollectie (slaat de documentdelen op), en - de
filecollectie (slaat de resulterende aanvullende metadata op).
Elke chunk is beperkt tot 255 KB in grootte. Dit betekent dat de laatste chunk normaal gesproken 255 KB of minder is. Klinkt nogal netjes.
Wanneer je leest van GridFS, herschikt het stuurprogramma alle chunks naar behoefte. Dit betekent dat je secties van een bestand kunt lezen volgens je query-bereik. Zoals het luisteren naar een segment van een audiobestand of het ophalen van een sectie van een videobestand.
Note: Het verdient de voorkeur om GridFS te gebruiken voor het opslaan van bestanden die normaal gesproken groter zijn dan de 16 MB-limiet. Voor kleinere bestanden wordt aanbevolen om het BinData-formaat te gebruiken om de bestanden in afzonderlijke documenten op te slaan.
Dit vat samen hoe GridFS in het algemeen werkt. Tijd om onze voeten dompelen in een aantal werkende code en zien hoe een systeem te implementeren als zodanig.
Genoeg gepraat, toon me de code
We maken gebruik van Node.js met toegang tot een cloud instantie van MongoDB voor onze setup. U kunt de code repository voor de voorbeeldapplicatie hier vinden.
 tarique93102GitHub
tarique93102GitHub 
We zullen ons volledig richten op segmenten van de code die te maken hebben met de functionaliteiten van GridFS. We zullen leren hoe we het kunnen instellen en gebruiken om bestanden op te slaan, bestanden of een bepaald bestand op te halen en een bepaald bestand te verwijderen. Laten we dan beginnen.
Initialiseer de Storage Engine
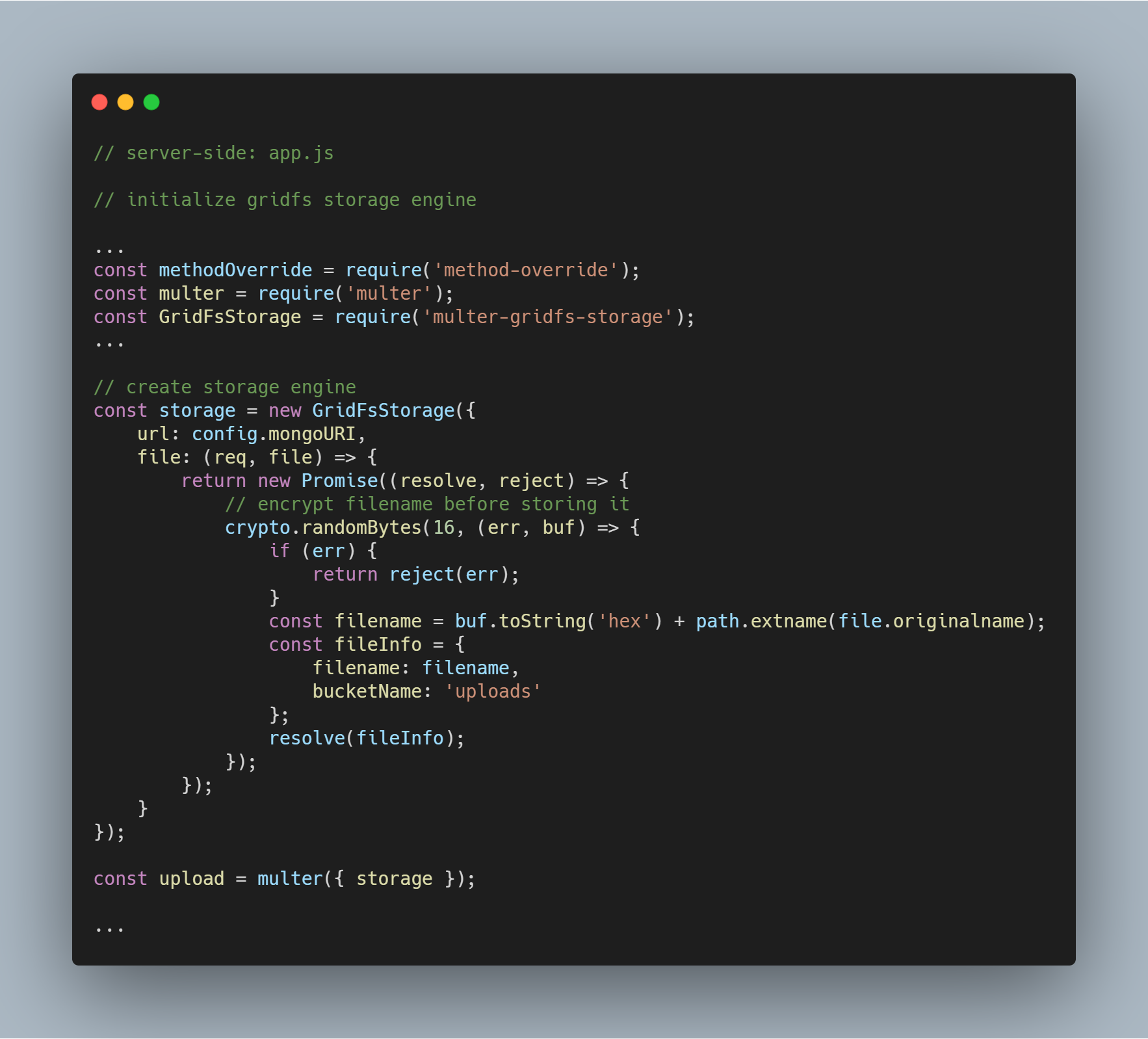
De pakketten die nodig zijn om de engine te initialiseren zijn multer-gridfs-storage en multer. We gebruiken ook method-override middleware om de verwijder operatie voor bestanden mogelijk te maken. De npm module crypto wordt gebruikt om de bestandsnamen te versleutelen bij het opslaan en lezen uit de database.
Als de opslag-engine die GridFS gebruikt eenmaal is geïnitialiseerd, hoef je het alleen maar aan te roepen met behulp van de multer middleware. Deze wordt vervolgens doorgegeven aan de respectieve route die de verschillende bestandsopslagbewerkingen uitvoert.
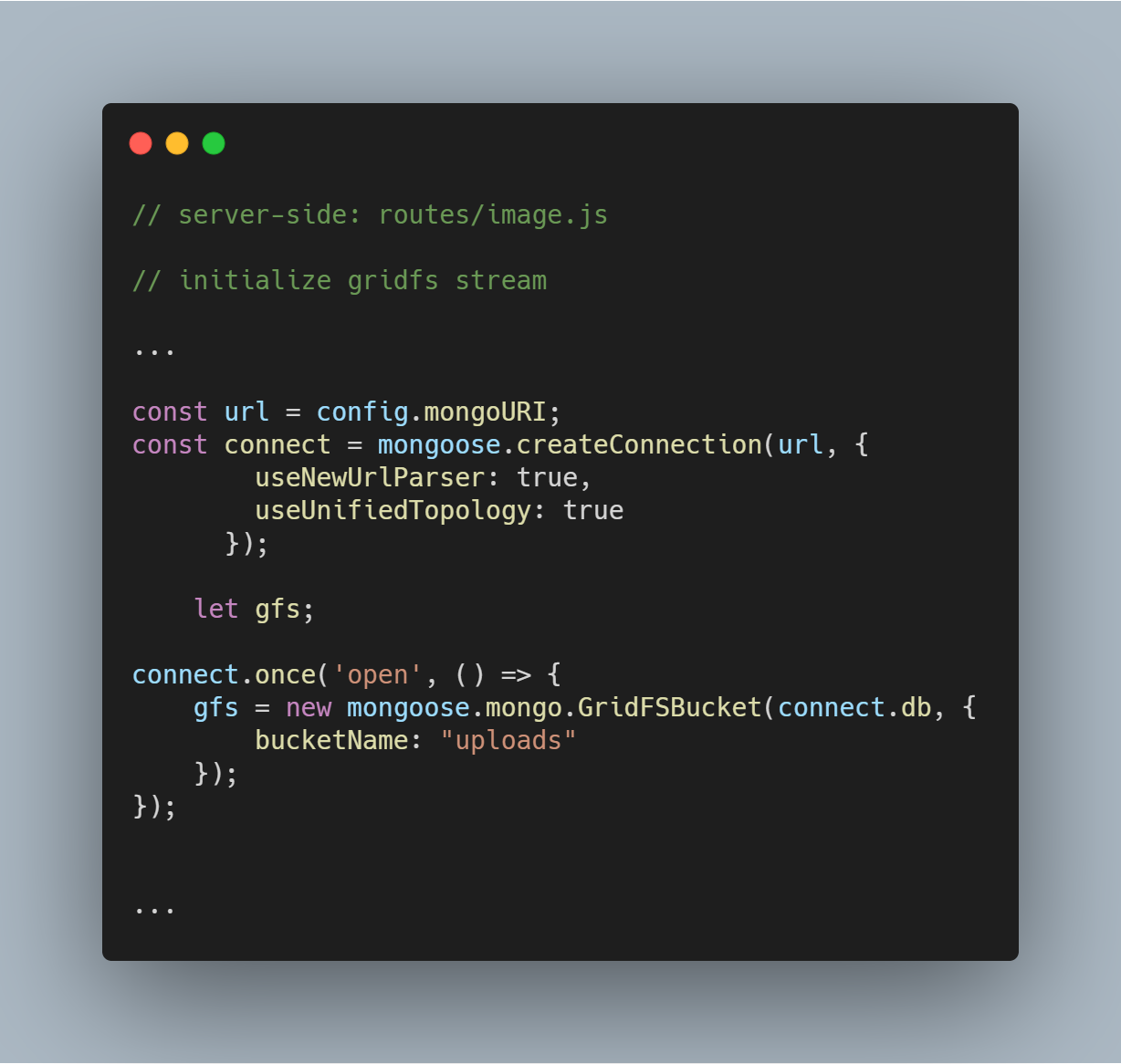
Initialiseer GridFS-stream
We initialiseren een GridFS-stream zoals te zien is in de onderstaande code. De stream is nodig om de bestanden uit de database te lezen en ook om te helpen bij het renderen van een afbeelding naar een browser wanneer dat nodig is.
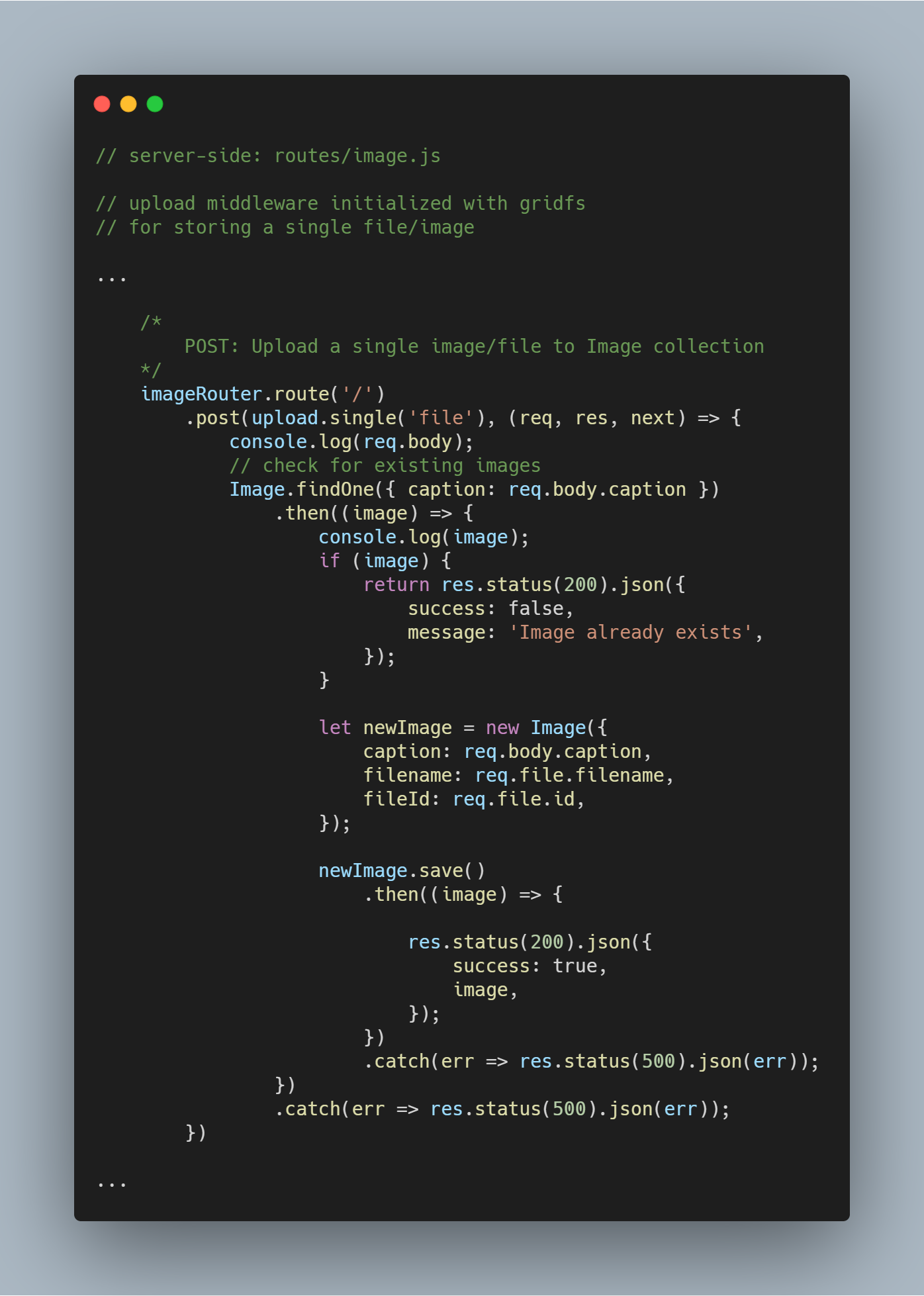
Een enkel bestand of afbeelding uploaden
We hergebruiken de upload middleware die we eerder hebben gemaakt.
Note: De naam file wordt gebruikt als parameter in upload.single() omdat we de sleutel met een vergelijkbare naam hebben die het bestand draagt dat door de client wordt verzonden.
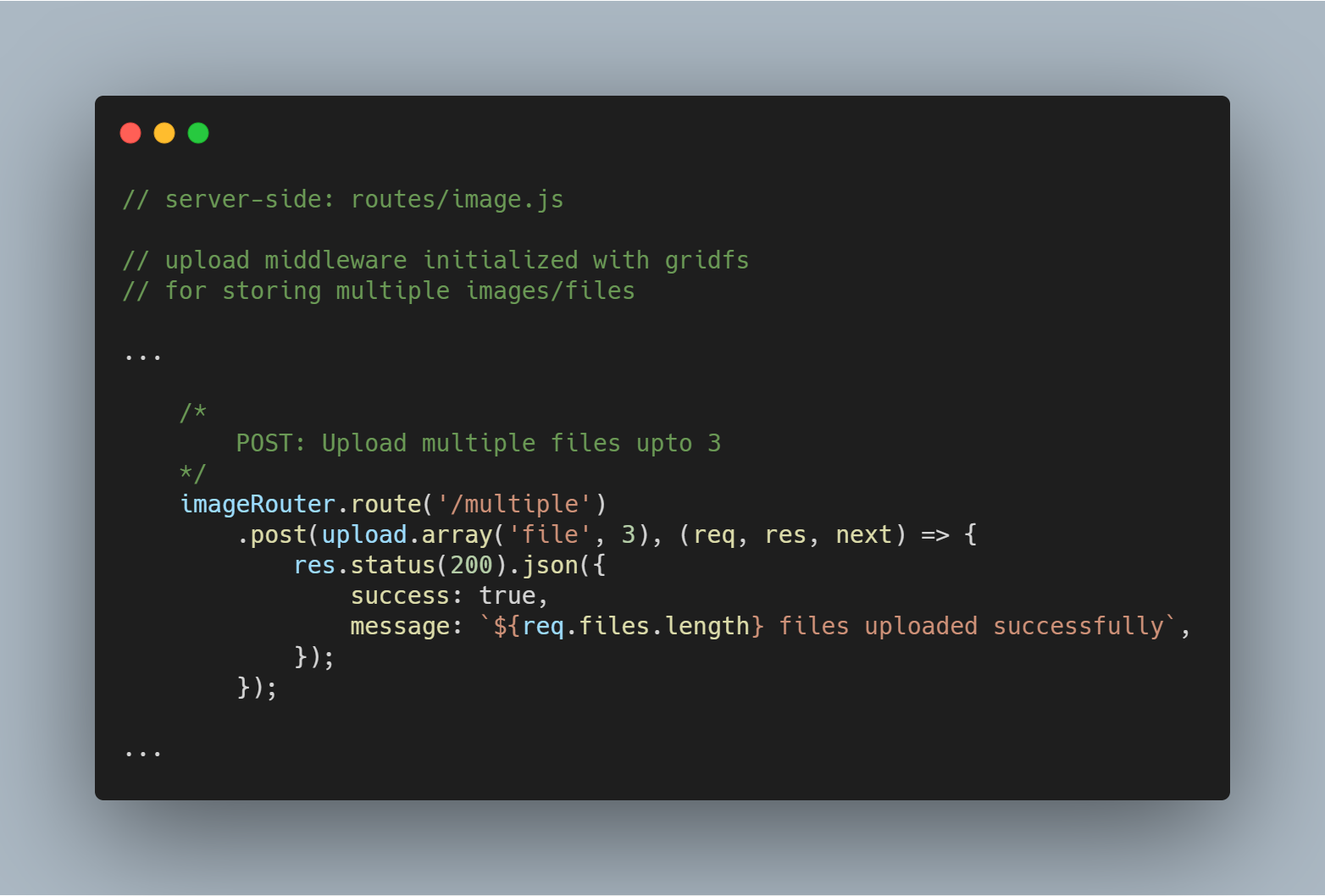
Meerdere bestanden of afbeeldingen uploaden
We kunnen ook meerdere bestanden tegelijk uploaden. In plaats van upload.single(), moeten we gewoon upload.multiple(<number of files>) gebruiken.
Opmerking: Het aantal geüploade bestanden kan minder zijn dan het gedefinieerde aantal bestanden.
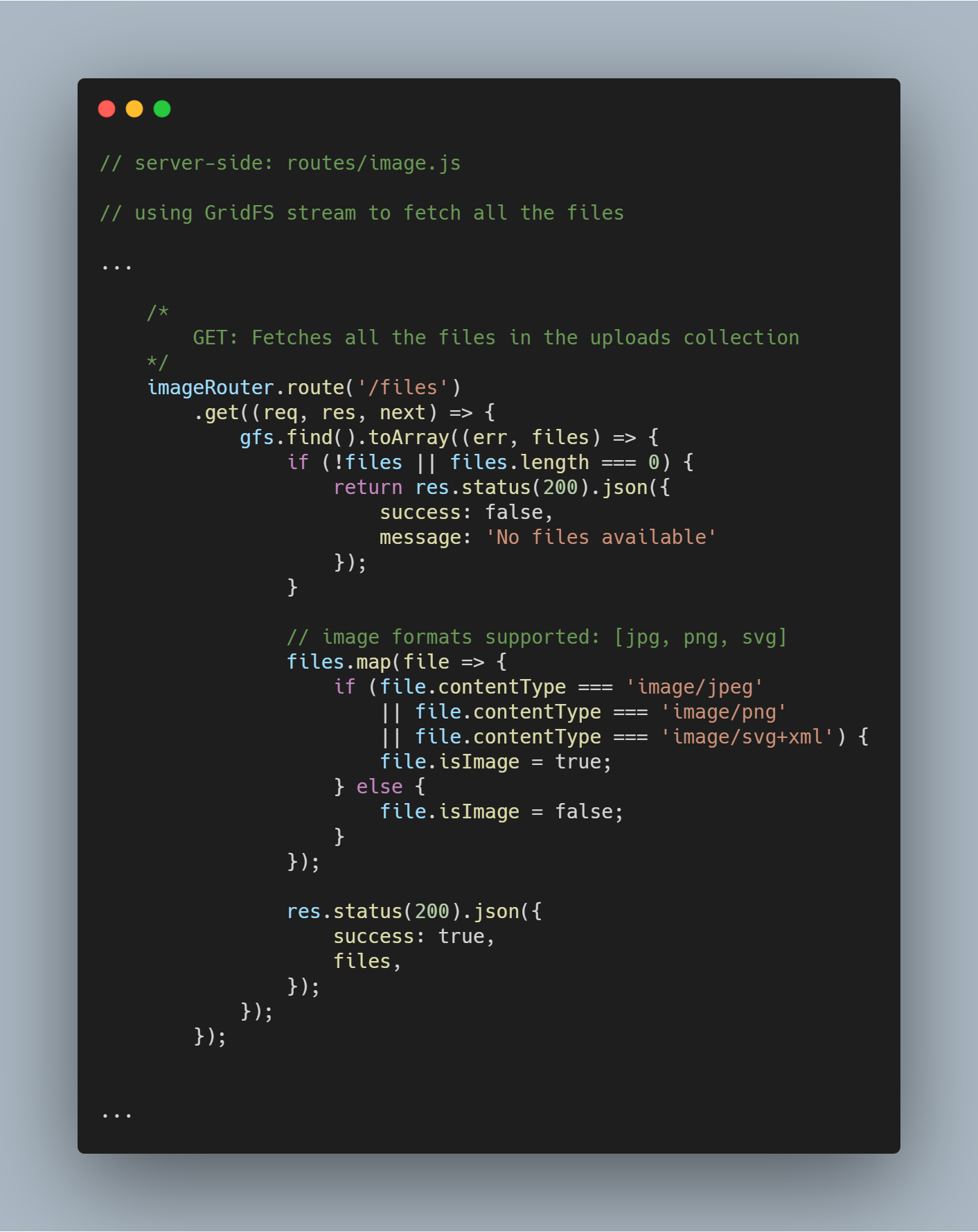
Alle bestanden ophalen uit database
Met behulp van de geïnitialiseerde stream kunnen we alle bestanden in de betreffende database ophalen met gfs.find().toArray(...). Zodra de bestanden zijn verkregen, mappen we ze in een array en verzenden we de respons.
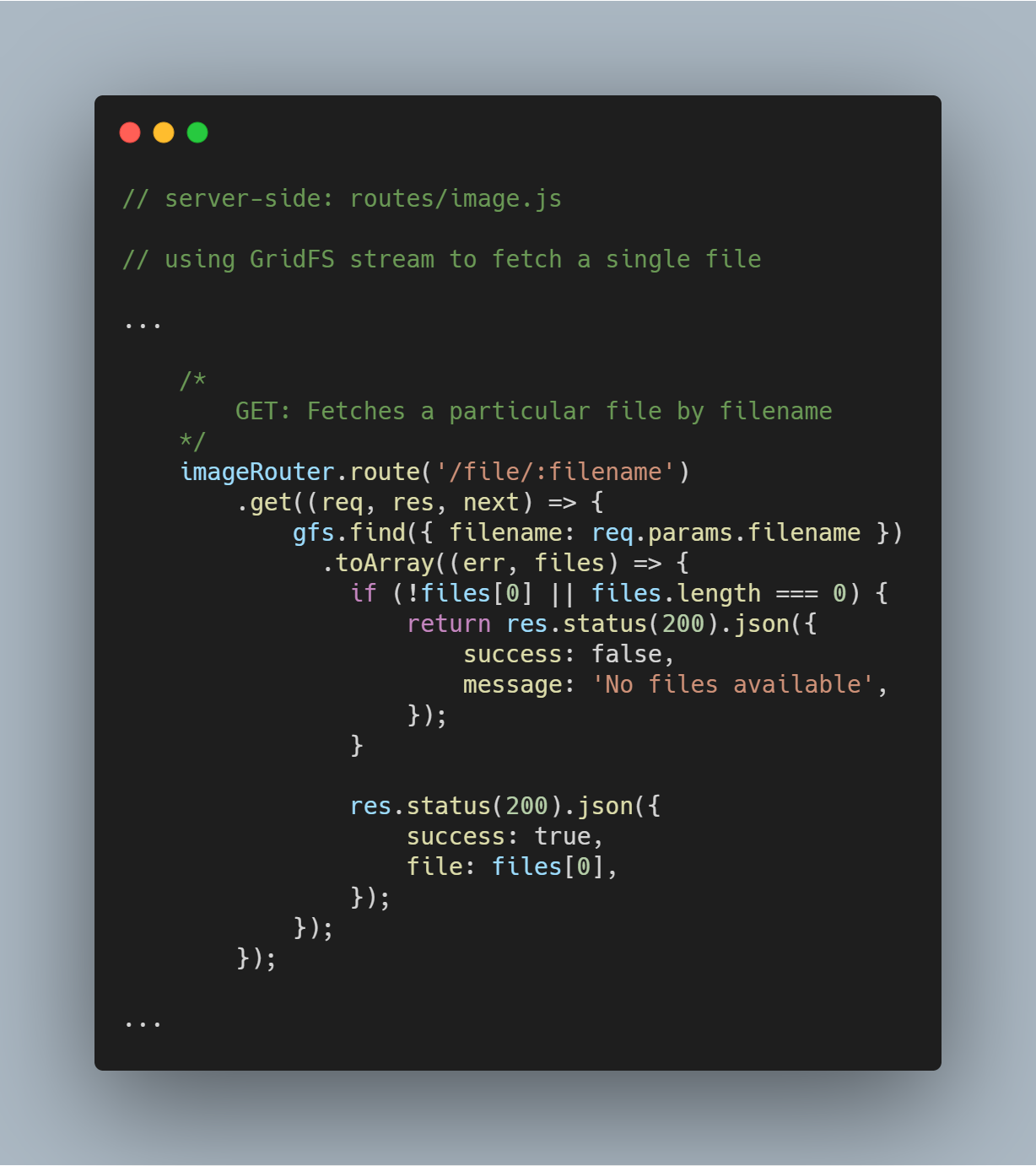
Een enkel bestand ophalen op bestandsnaam
Het is heel eenvoudig om GridFS om een enkel bestand te vragen op basis van een specifiek kenmerk zoals filename. Met behulp van de GridFS-stream kunt u de database doorzoeken via de functie gfs.find({<add query here>}).
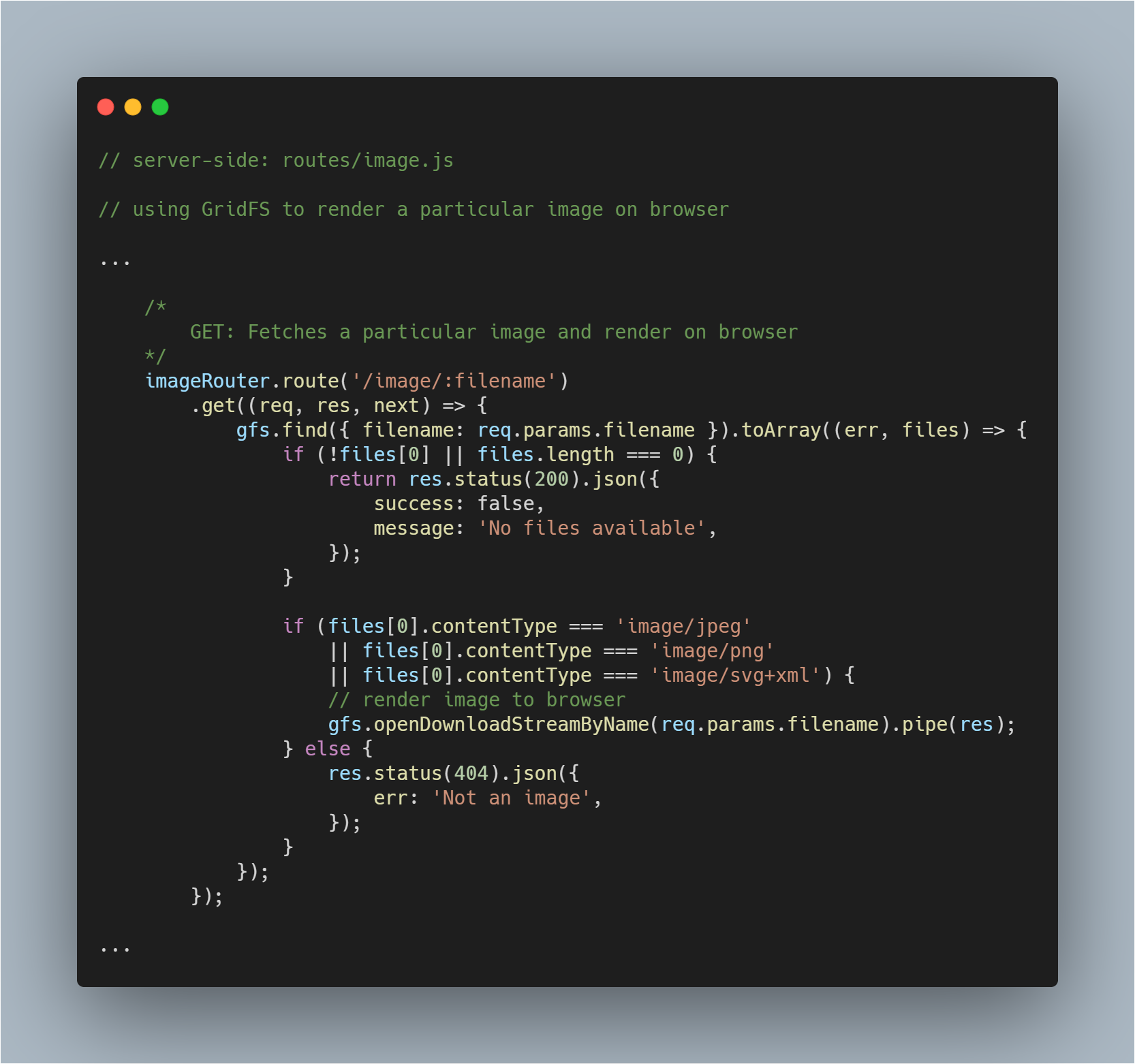
Render a Fetched Image to Browser
Dit is een iets lastiger gedeelte, omdat u niet alleen een bestand uit de database moet ophalen, maar het ook als een afbeelding in de browser moet renderen. We halen het bestand normaal op. Geen verandering in dat proces.
Dan met de hulp van de methode openDownloadStreamByName() op gfs stream, kunnen we gemakkelijk een afbeelding renderen aangezien het een leesbare stream teruggeeft. Als we dat hebben gedaan, kunnen we JavaScript’s pipe() gebruiken om het antwoord te streamen.
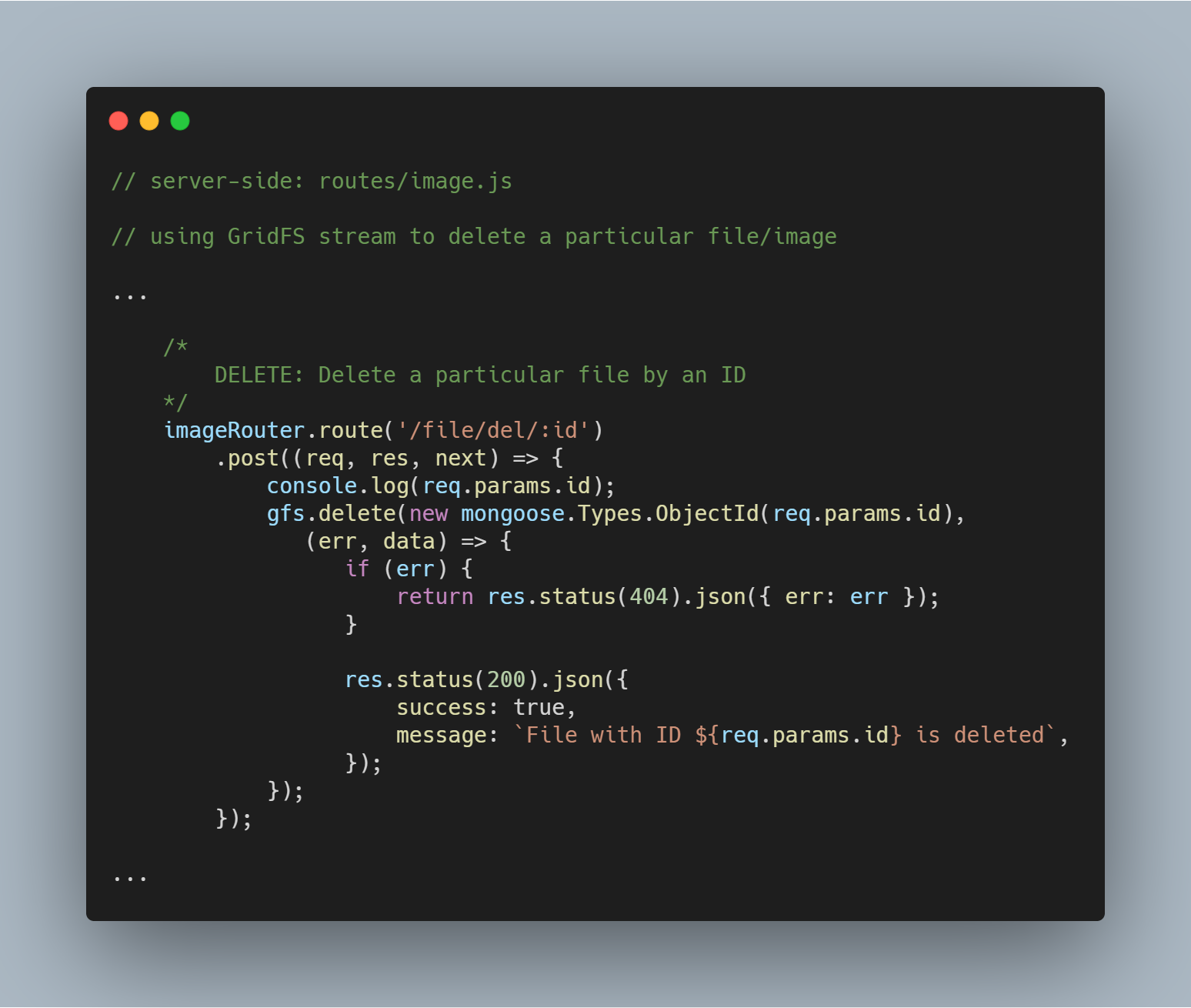
Een bepaald bestand op id verwijderen
Het verwijderen van een bestand is net zo eenvoudig. We gebruiken de stream-methode delete() met parameter _id om het bestand in kwestie op te vragen en te verwijderen.
Dit zijn de belangrijkste functionaliteiten die door het ontwerp van de opslagmotor worden geboden. Ik heb de besproken GridFS-functies gebruikt om een eenvoudige toepassing voor het uploaden van afbeeldingen te maken. U kunt dieper in de code duiken in de respository.
Conclusie
Het heeft me wat tijd en moeite gekost om te begrijpen hoe ik GridFS voor een persoonlijk project kan gebruiken. Daarom wilde ik ervoor zorgen dat ten minste één ander persoon niet dezelfde hoeveelheid tijd hoefde te investeren.
Dat gezegd hebbende, zou ik aanraden om GridFS met voorzichtigheid te gebruiken. Het is geen wondermiddel voor al uw zorgen over bestandsopslag. Maar het is wel een handige specificatie om te kennen en je ervan bewust te zijn.