“Het zijn allemaal 1-en en 0-en.” Mensen zeggen dit als ze een grap of een sarcastische opmerking maken. Als het op computers aankomt, is het echt waar. En op het niveau van de hardware, is dat alles wat er is. De processor, het geheugen, verschillende vormen van opslag, USB, HDMI, en netwerkverbindingen, samen met al het andere in die mobiele telefoon, tablet, laptop, of desktop gebruikt alleen maar 1s en 0s. Bytes zorgen voor de groepering van de 1-en en de 0-en. Ze zijn dus een grote hulp om ze georganiseerd te houden. Laten we eens kijken hoe ze dat doen.
Bytes zijn de meeteenheid voor gegevens en programma’s die in uw computer worden opgeslagen en gebruikt. Hoewel de byte al lang in de computergeschiedenis bestaat en verschillende vormen heeft aangenomen, is de huidige lengte van 8 bits goed ingeburgerd. Op zichzelf of als aangrenzende groepen, zijn bytes de algemeen aanvaarde meest gebruikelijke manier waarop de Bits in een computer worden georganiseerd.
Dus wat is een bit? Een bit is een binair cijfer, dat wil zeggen dat het slechts twee waarden kan hebben. In computers zijn de twee waarden die een bit kan hebben, nul (0) en één (1). Dat is het, geen andere keuzes. Een byte zijn slechts acht binaire bits die samen binaire getallen voorstellen. Door middel van verschillende coderingsschema’s kunnen de getallen een grote verscheidenheid van andere dingen voorstellen, zoals de tekens waarmee we schrijven.
De onderstaande tabel toont een enkele Big-Endian byte met de afzonderlijke bits van deze byte en hun bijbehorende machten van twee. Alle bytes met gegevens zijn in Big-Endian formaat. Er zijn andere bytes, zoals programmacode, waar de Endian opmaak niet van toepassing is. De decimale waarden van elke macht van twee wordt ter referentie bij elk bit getoond. Een lijn tussen Bit 3 en Bit 4 is waar de byte is onderverdeeld in vier bitgroepen, Nibbles genaamd. Little-Endian is een veelgebruikt byte-formaat. Blijf kijken voor meer informatie over Endians. Als je nieuwsgierig bent naar de naam, zoek dan eens op (etymologie van endian).
Een Big-Endian Byte:
| Bit0 | Bit1 | Bit2 | Bit3 | Bit4 | Bit5 | Bit6 | Bit7 | |
| Kracht van 2 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 21 |
| Decimale waarde | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
Elke nibble van een byte kan een binair getal van vier bits bevatten, zoals in de volgende tabel is aangegeven. Als een bit op “1” wordt gezet, wordt die macht van twee opgeteld bij de waarde van de nibble. Als een bit op “0” wordt gezet, wordt die macht van twee niet bij de waarde van de nibble opgeteld. Een byte, die uit twee nibbles bestaat, kan een hexadecimaal getal van twee cijfers bevatten. Bits zijn eigenlijk alles wat een computer kan gebruiken. Programmeurs en ingenieurs die computerhardware ontwikkelen, gebruiken hexadecimale getallen om gemakkelijker met bits om te gaan. In de tabel hieronder staat het meest significante bit links 20, 21, 22, 23
Eén Big-Endian Nibble:
| Binary Number |
Hexidecimal Value |
| 0000 | 0 |
| 0001 | 1 |
| 0010 | 2 |
| 0011 | 3 |
| 0100 | 4 |
| 0101 | 5 |
| 0110 | 6 |
| 0111 | 7 |
| 1000 | 8 |
| 1001 | 9 |
| 1010 | A |
| 1011 | B |
| 1100 | C |
| 1101 | D |
| 1110 | E |
| 1111 | F |
Ik zal uitleggen hoe Big-Endian beginnen met een diagram van één byte. De langere lijnen aan het einde van dit frame zijn de grenzen van de byte, zodat als je een groep van aangrenzende bytes zou tekenen het duidelijk zou zijn waar de ene byte ophield en de andere begon. De kleine lijnen verdelen het frame in afzonderlijke locaties waar elk van de acht bits kan worden weergegeven. De middellijn in het midden verdeelt de byte in twee gelijke stukken van vier bits die de nibbles zijn. Nibbles hebben ook een lange en gevarieerde geschiedenis. Ik heb nooit gezien dat ze gestandaardiseerd zijn. De huidige gangbare opvatting is echter dat nibbles groepen van vier bits zijn, zoals ik ze hieronder heb weergegeven. Al deze lijnen bestaan alleen als mensen bytes tekenen. De lijnen bestaan niet in de computer.
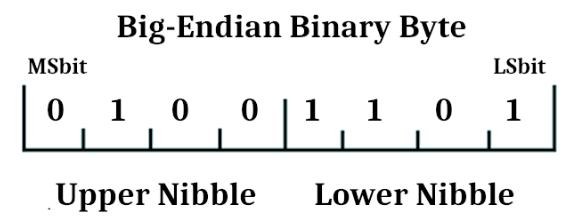
De Upper Nibble en Lower Nibble zijn labels zoals ze in een Big-Endian byte zouden worden gebruikt. In Big-Endian staat het meest significante cijfer aan de linkerkant van een getal. De Lower Nibble is dus de minst significante helft van het getal in de byte. Het minst significante bit bevindt zich rechts LSBit (gewoonlijk LSB genoemd) staat voor Least Significant Bit. En het meest significante bit zit aan de linkerkant. De Upper Nibble aan de linkerkant is de meest significante helft van het getal. MSBit (meestal genoteerd als MSB) is het meest significante bit. Dit is hetzelfde als hoe we decimale getallen schrijven met het meest significante cijfer aan de linkerkant. Dit wordt Big-Endian genoemd omdat het “grote einde” van het getal eerst komt.
Omdat de byte twee hexadecimale cijfers kan bevatten, kan een byte hexadecimale getallen bevatten tussen 00 en FF (0 tot 255 in decimaal) Dus als je bytes gebruikt om de karakters van een menselijk leesbare taal weer te geven, geef je gewoon elk karakter, leesteken, enz. een nummer. (En dan natuurlijk iedereen laten instemmen met de codering die je hebt bedacht.) Dit is slechts één gebruik van bytes. Bytes worden ook gebruikt als programmacode die je computer uitvoert, nummers voor verschillende gegevens die je zou kunnen hebben, en al het andere dat een computer bewoont in de CPU, het geheugen, de opslag, of rondzwervend op de verschillende bussen en interface poorten.
Zo blijkt dat er twee algemeen gebruikte byte-formaten zijn. Little-Endian is gebruikt in de voorgaande voorbeelden. Het meest significante cijfer staat links en het minst significante cijfer staat rechts.
Er is ook een formaat dat Little-Endian heet. Zoals je zou verwachten is dit het tegenovergestelde van Big-Endian, met het minst significante cijfer links en het meest significante cijfer rechts. Dit is het tegenovergestelde van hoe wij decimale getallen schrijven. Little-Endian wordt niet gebruikt voor de volgorde van bits in een byte, maar wel voor de volgorde van bytes in een grotere structuur. Bijvoorbeeld: Een groot getal in een Little-Endian Word van twee bytes zou de minst significante byte aan de linkerkant hebben. Als het getal van twee bytes in Big-Endian zou zijn, zou de meest significante byte aan de rechterkant zijn. Little-Endian wordt alleen gebruikt in de context van lange multi-byte getallen om de significantie volgorde van de bytes in de grotere datastructuur in te stellen.
Er zijn redenen om zowel Big als Little byte-ordening te gebruiken en de vleesachtige redenen vallen buiten het bestek van dit artikel. Echter, Little-Endian heeft de neiging om te worden gebruikt in microprocessoren. De x86-64 processoren in de meeste PC’s gebruiken het Little-Endian byte-formaat. Hoewel de latere generaties speciale instructies hebben die beperkt gebruik maken van het Big-Endian formaat. Het Big-Endian byte-formaat wordt veel gebruikt in netwerken en met name in die grote Z-computers. Nu ben je niet noodzakelijkerwijs beperkt tot het een of het ander. De nieuwere ARM processoren kunnen beide formaten gebruiken. Apparaten zoals microprocessoren die zowel Big-Endian als Little Endian byte-indeling kunnen gebruiken, worden soms aangeduid als Bi-Endian.
Wel, soms heb je echt meer dan één byte nodig om een getal te bevatten. Daartoe zijn er langere formaten beschikbaar die uit meerdere bytes bestaan. Bijvoorbeeld: De x86-64 processoren hebben Words die bestaan uit 16 bits of 2 bytes die toevallig kop aan staart naast elkaar liggen, om het zo maar te zeggen. Ze hebben ook Double Words (32 bits of 4 bytes), en Quad Words (64 bits of 8 bytes). Dit zijn slechts voorbeelden van gegevensvormen die door de processorhardware beschikbaar worden gesteld.
Programmeurs die met talen werken, hebben nog veel meer manieren om de bits en bytes te organiseren. Als het programma klaar is, zet een compiler of een ander mechanisme de manier waarop het programma bits en bytes heeft georganiseerd, om in gegevensvormen die de CPU-hardware aankan.