Työskentelee Derrick Mwiti, data-analyytikko

Toimittajan huomautus: Tämä opetusohjelma havainnollistaa, miten pääset alkuun aikasarjojen ennustamisessa LSTM-malleilla. Pörssidata on tähän hyvä valinta, koska se on melko säännöllistä ja laajalti kaikkien saatavilla. Älä pidä tätä taloudellisena neuvona tai käytä sitä omien kauppojen tekemiseen.
Tässä opetusohjelmassa rakennamme Python-syväoppimismallin, joka ennustaa osakekurssien tulevaa käyttäytymistä. Oletamme, että lukija tuntee syväoppimisen käsitteet Pythonissa, erityisesti Long Short-Term Memory (lyhytkestoinen pitkäkestoinen muisti).
Vaikka osakkeen todellisen hinnan ennustaminen on vaikeaa, voimme rakentaa mallin, joka ennustaa, nouseeko tai laskeeko hinta. Tässä opetusohjelmassa käytetyt tiedot ja muistikirja löytyvät täältä. On tärkeää huomata, että osakkeiden hintoihin vaikuttavat aina myös muut tekijät, kuten poliittinen ilmapiiri ja markkinat. Emme kuitenkaan keskity näihin tekijöihin tässä tutoriaalissa.
Esittely
LSTM:t ovat erittäin tehokkaita sekvenssin ennustamisongelmissa, koska ne pystyvät tallentamaan aiempaa tietoa. Tämä on tärkeää tapauksessamme, koska osakkeen aiempi hinta on ratkaisevaa sen tulevan hinnan ennustamisessa.
Aloitamme tuomalla NumPy:n tieteellisiä laskutoimituksia varten, Matplotlib:n graafien piirtämistä varten ja Pandas:n auttamaan datajoukkojemme lataamisessa ja käsittelyssä.
Datasetin lataaminen
Seuraavaksi lataamme harjoitustietoaineistomme ja valitsemme Open– ja Highsarakkeet, joita käytämme mallinnuksessamme.
Tarkistamme tietokokonaisuutemme pään, jotta saamme käsityksen siitä, millaisen tietokokonaisuuden kanssa työskentelemme.
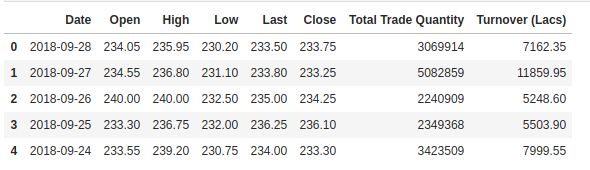
Open-sarake on lähtöhinta, kun taas Close-sarake on osakkeen lopullinen hinta tiettynä kaupankäyntipäivänä. High– ja Low-sarakkeet edustavat tietyn päivän korkeinta ja matalinta hintaa.
Ominaisuuksien skaalaus
Syväoppimismalleista saadun aikaisemman kokemuksen perusteella tiedämme, että meidän on skaalattava datamme optimaalisen suorituskyvyn saavuttamiseksi. Tapauksessamme käytämme Scikit- Learnin MinMaxScaler ja skaalaamme aineistomme luvuiksi nollan ja yhden välillä.
Datan luominen aika-askeleilla
LSTM-mallit odottavat, että datamme on tietyssä formaatissa, tavallisesti 3D-matriisina. Aloitamme luomalla dataa 60 timestepillä ja muuntamalla sen matriisiksi NumPy:n avulla. Seuraavaksi muunnamme datan 3D-ulottuvuusmatriisiksi, jossa on X_train näytettä, 60 aikaleimaa ja yksi piirre jokaisella askeleella.
LSTM:n rakentaminen
LSTM:n rakentamiseksi meidän on tuotava pari moduulia Kerasista:
-
Sequentialneuroverkon alustamiseen -
Densetiheästi kytketyn neuroverkkokerroksen lisäämiseen -
LSTMLong Short-Term Memory -kerroksen lisäämiseen -
Dropoutpudotuskerrosten lisäämiseen, jotka estävät ylisovittamisen
Lisäämme LSTM-kerroksen ja lisäämme sen jälkeen muutamat Dropout-kerrokset ylisovittamisen estämiseksi. Lisäämme LSTM-kerroksen seuraavilla argumenteilla:
- 50 yksikköä, joka on ulostuloavaruuden ulottuvuus
-
return_sequences=True, joka määrittää, palautetaanko ulostulosekvenssin viimeinen ulostulo vai koko sekvenssi -
input_shapeharjoittelujoukkomme muodoksi.
Määritellessämme Dropout-kerroksia annamme arvoksi 0.2 eli 20 % kerroksista pudotetaan pois. Tämän jälkeen lisäämme Dense-kerroksen, joka määrittää 1 yksikön ulostulon. Tämän jälkeen käännämme mallimme käyttäen suosittua adam-optimointiohjelmaa ja asetamme häviöksi mean_squarred_error. Tämä laskee neliövirheiden keskiarvon. Seuraavaksi sovitamme mallin ajettavaksi 100 epookilla, kun eräkoko on 32. Kannattaa muistaa, että tietokoneen spekseistä riippuen tämän suorittaminen saattaa kestää muutaman minuutin.
Predicting Future Stock using the Test Set
Ensin meidän on tuotava testijoukko, jonka perusteella teemme ennusteet.
Voidaksemme ennustaa tulevia osakekursseja meidän on tehtävä pari asiaa testijoukon lataamisen jälkeen:
- Yhdistetään koulutusjoukko ja testijoukko 0-akselilla.
- Aika-askeleeksi asetetaan 60 (kuten aiemmin nähtiin)
- Käytä
MinMaxScalermuuntamaan uusi dataset - Muotoile dataset kuten aiemmin tehtiin
Ennusteiden tekemisen jälkeen käytämme inverse_transform saadaksemme takaisin osakekurssit normaalissa luettavassa muodossa.
Tulosten piirtäminen
Viimeiseksi käytämme Matplotlibiä visualisoidaksemme ennustetun osakekurssin ja todellisen osakekurssin tuloksen.
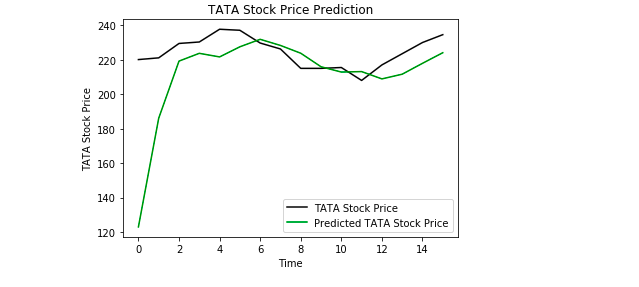
Diagrammista näemme, että todellinen osakekurssi nousi, kun mallimme myös ennusti osakekurssin nousevan. Tämä osoittaa selvästi, kuinka tehokkaita LSTM-mallit ovat aikasarjojen ja peräkkäisten tietojen analysoinnissa.
Johtopäätös
On olemassa pari muutakin tekniikkaa osakekurssien ennustamiseen, kuten liukuvat keskiarvot, lineaarinen regressio, K-Nearest Neighbours, ARIMA ja Prophet. Näitä tekniikoita voi testata omatoimisesti ja verrata niiden suorituskykyä Kerasin LSTM:n kanssa. Jos haluat oppia lisää Kerasista ja syväoppimisesta, löydät artikkelini siitä täältä ja täältä.
Keskustele tästä viestistä Redditissä ja Hacker Newsissa.
Bio: Derrick Mwiti on data-analyytikko, kirjoittaja ja mentori. Häntä ajaa loistavien tulosten tuottaminen jokaisessa tehtävässä, ja hän on mentori Lapid Leaders Afrikassa.
Original. Reposted with permission.
Related:
- Introduction to Deep Learning with Keras
- Introduction to PyTorch for Deep Learning
- The Keras 4 Step Workflow