Tiedostojen tallennus on tärkeä ominaisuus, jota tarvitaan useissa prosesseissa erityyppisissä sovelluksissa. Prosessien, kuten Content Delivery Networks (CDNs), olemassaolo, jotka on perustettu kolmannen osapuolen pilvivaihtoehtojen, kuten Amazon Web Servicesin, ja paikallisten tiedostojen tallennusvaihtoehtojen avulla, on aina helpottanut tällaisen ominaisuuden rakentamista.
Konsepti tiedostojen tallentamisesta suoraan tietokantaan yhden API-kutsun kautta oli kuitenkin kiehtonut minua jo jonkin aikaa. Siellä GridFS tuli minulle kuvaan.

GridFS – maallikon ymmärrys
MongoDB:llä on ajurimäärittely tiedostojen lataamiseen ja hakemiseen siitä nimeltään GridFS. GridFS:n avulla voit tallentaa ja hakea tiedostoja, myös sellaisia, jotka ylittävät BSON-dokumentin 16 Mt:n kokorajan.
GridFS periaatteessa ottaa tiedoston ja pilkkoo sen useisiin palasiin, jotka tallennetaan yksittäisinä dokumentteina kahteen kokoelmaan:
-
chunk-kokoelmaan (tallentaa dokumentin osat) ja -
file-kokoelmaan (tallentaa siitä johtuvat lisämetatiedot).
Jokainen palanen on rajoitettu 255 kilotavun kokoiseksi. Tämä tarkoittaa, että viimeinen lohko on yleensä joko 255 KB:n kokoinen tai sitä pienempi. Kuulostaa melko siistiltä.
Kun luet GridFS:stä, ajuri kokoaa kaikki chunkit uudelleen tarpeen mukaan. Tämä tarkoittaa, että voit lukea tiedoston osia kyselyalueesi mukaan. Esimerkiksi kuunnella segmentti äänitiedostosta tai hakea osio videotiedostosta.
Huomautus: On suositeltavaa käyttää GridFS:ää tiedostojen tallentamiseen, jotka yleensä ylittävät 16 Mt:n kokorajan. Pienempiä tiedostoja varten on suositeltavaa käyttää BinData-muotoa tiedostojen tallentamiseen yksittäisinä asiakirjoina.
Tässä on yhteenveto siitä, miten GridFS toimii yleisesti. On aika kastaa jalkamme toimivaan koodiin ja katsoa, miten järjestelmä toteutetaan sellaisenaan.
Et tarpeeksi puhetta, näytä minulle koodi
Käytämme asennuksessamme Node.js:ää, jolla on pääsy MongoDB:n pilvipalvelun instanssiin. Löydät esimerkkisovelluksen koodivaraston täältä.
 tarique93102GitHub
tarique93102GitHub 
Keskitymme täysin GridFS:n toiminnallisuuksiin liittyviin koodin osiin. Opettelemme, miten se asetetaan ja miten sitä käytetään tiedostojen tallentamiseen, tiedostojen tai tietyn tiedoston hakemiseen ja tietyn tiedoston poistamiseen. Aloitetaan siis.
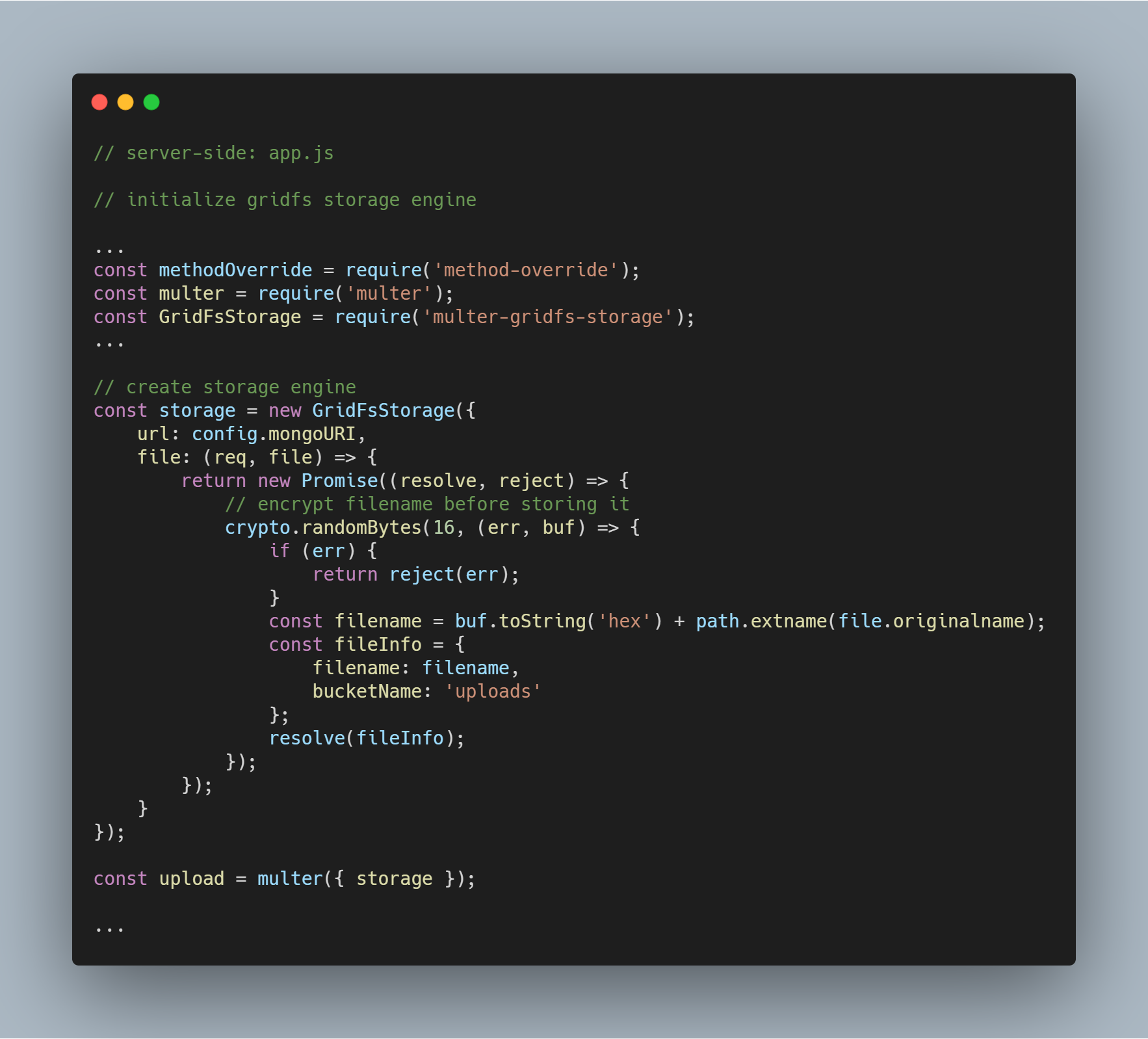
Tallennuskoneen alustaminen
Koneen alustamiseen tarvittavat paketit ovat multer-gridfs-storage ja multer. Käytämme myös method-override-väliohjelmistoa ottaaksemme käyttöön tiedostojen poisto-operaation. Npm-moduulia crypto käytetään tiedostojen nimien salaamiseen tallennettaessa ja luettaessa tietokannasta.
Kun GridFS:ää käyttävä tallennusmoottori on alustettu, sitä täytyy vain kutsua multer-väliohjelmiston avulla. Sen jälkeen se välitetään vastaavalle reitittimelle, joka suorittaa eri tiedostojen tallennusoperaatiot.
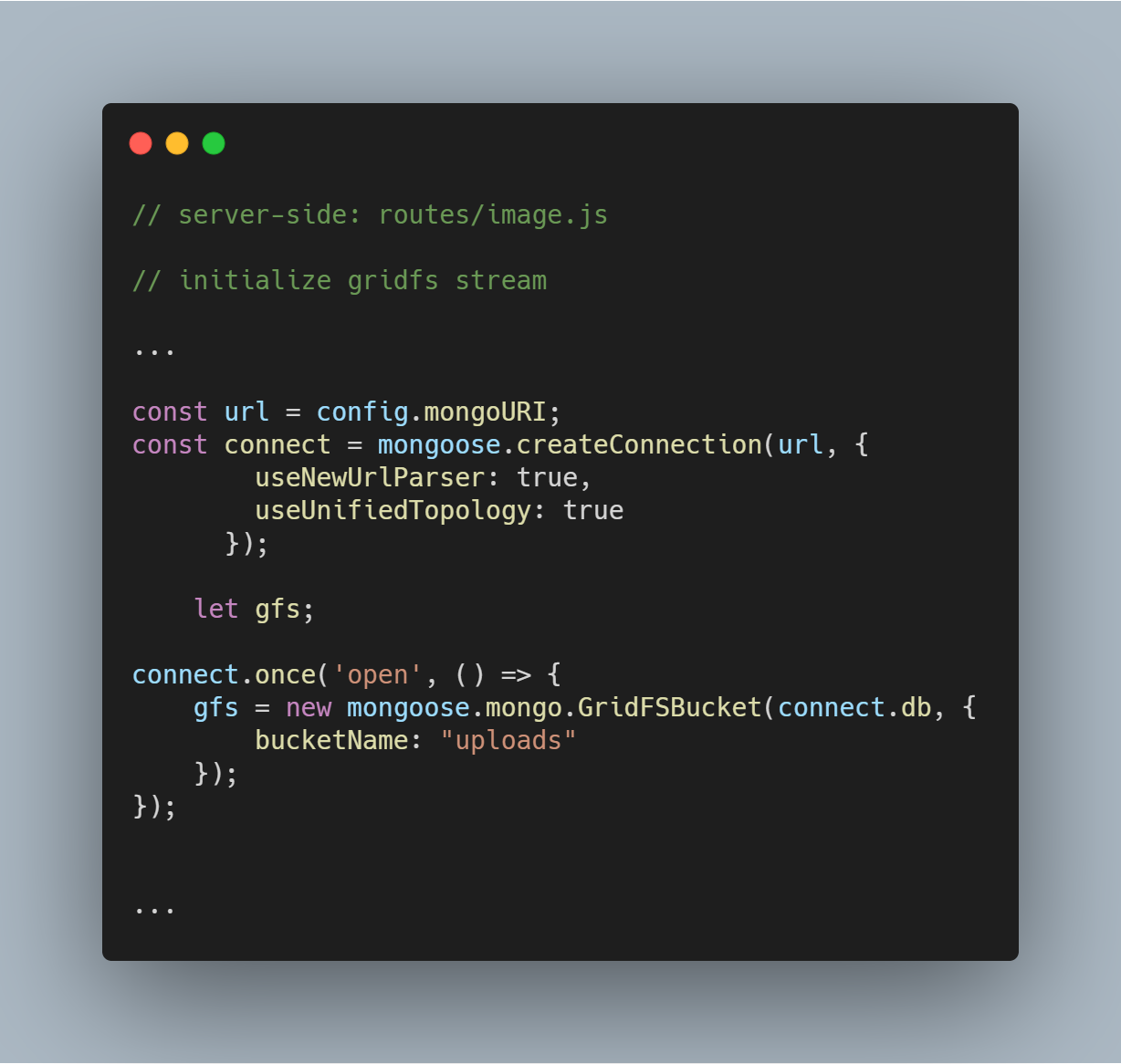
Initialize GridFS Stream
Initialisoimme GridFS-virran alla olevan koodin mukaisesti. Streamia tarvitaan tiedostojen lukemiseen tietokannasta ja myös auttamaan kuvan renderöinnissä selaimelle tarvittaessa.
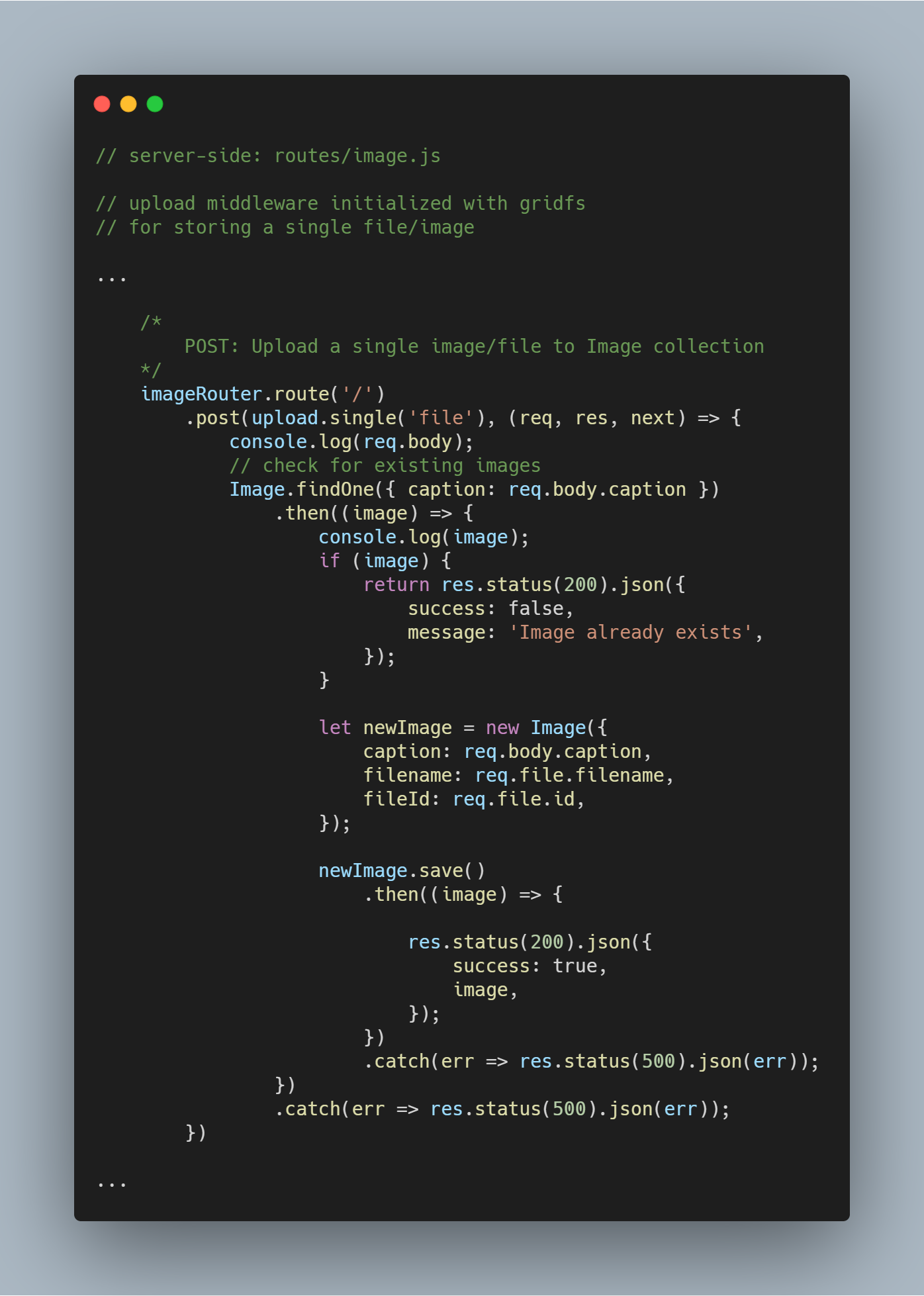
Yksittäisen tiedoston tai kuvan lataaminen
Käytämme uudelleen aiemmin luomamme upload-väliohjelmiston.
Huomaa: Nimeä file käytetään parametrina kohdassa upload.single(), koska meillä on samanniminen avain, joka kantaa asiakkaalta lähetettävää tiedostoa.
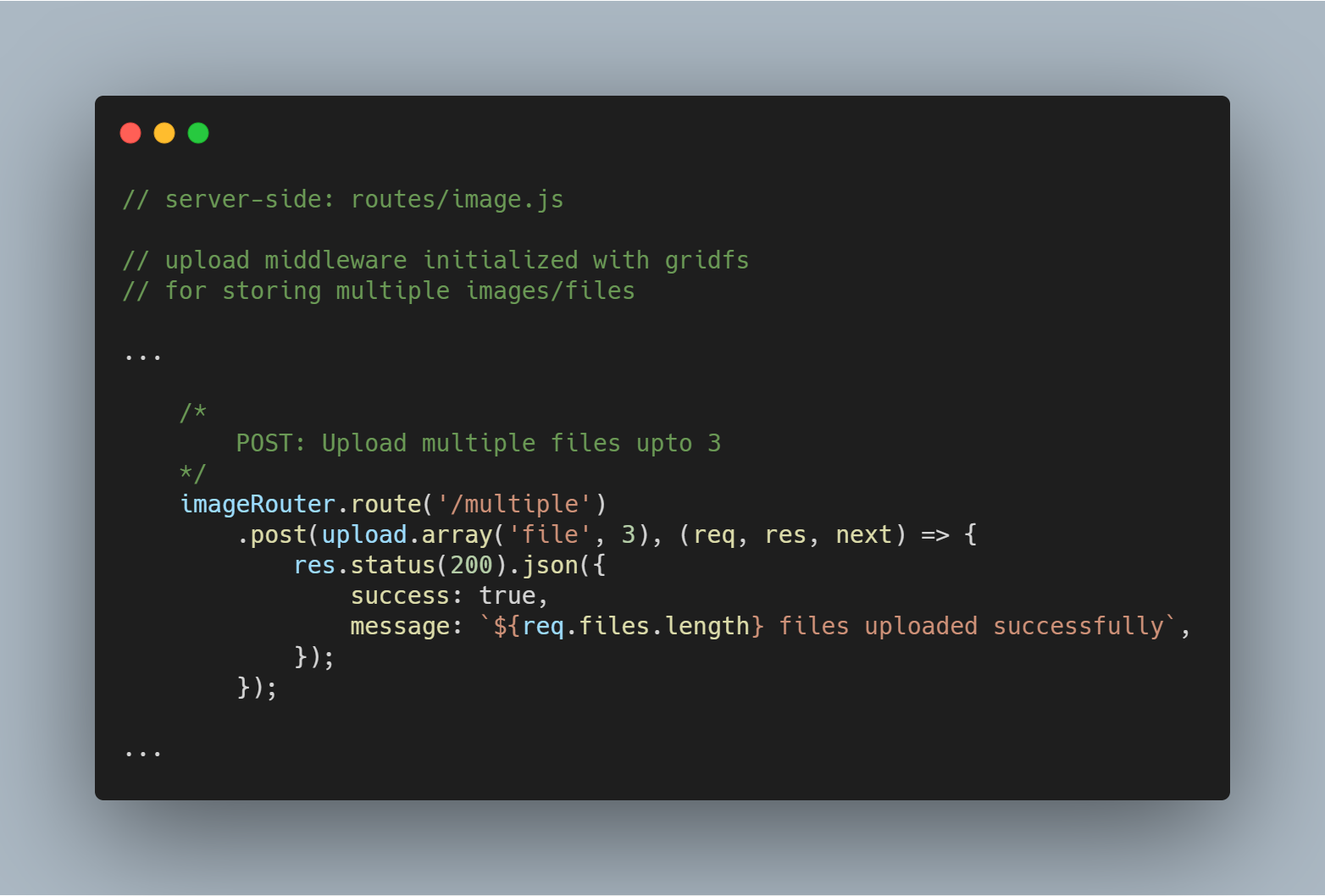
Lataamme useita tiedostoja tai kuvia
Voimme myös ladata useita tiedostoja kerralla. Meidän on yksinkertaisesti käytettävä upload.single():n sijasta upload.multiple(<number of files>).
Huomautus: Ladattavien tiedostojen määrä voi olla pienempi kuin määritetty tiedostojen määrä.
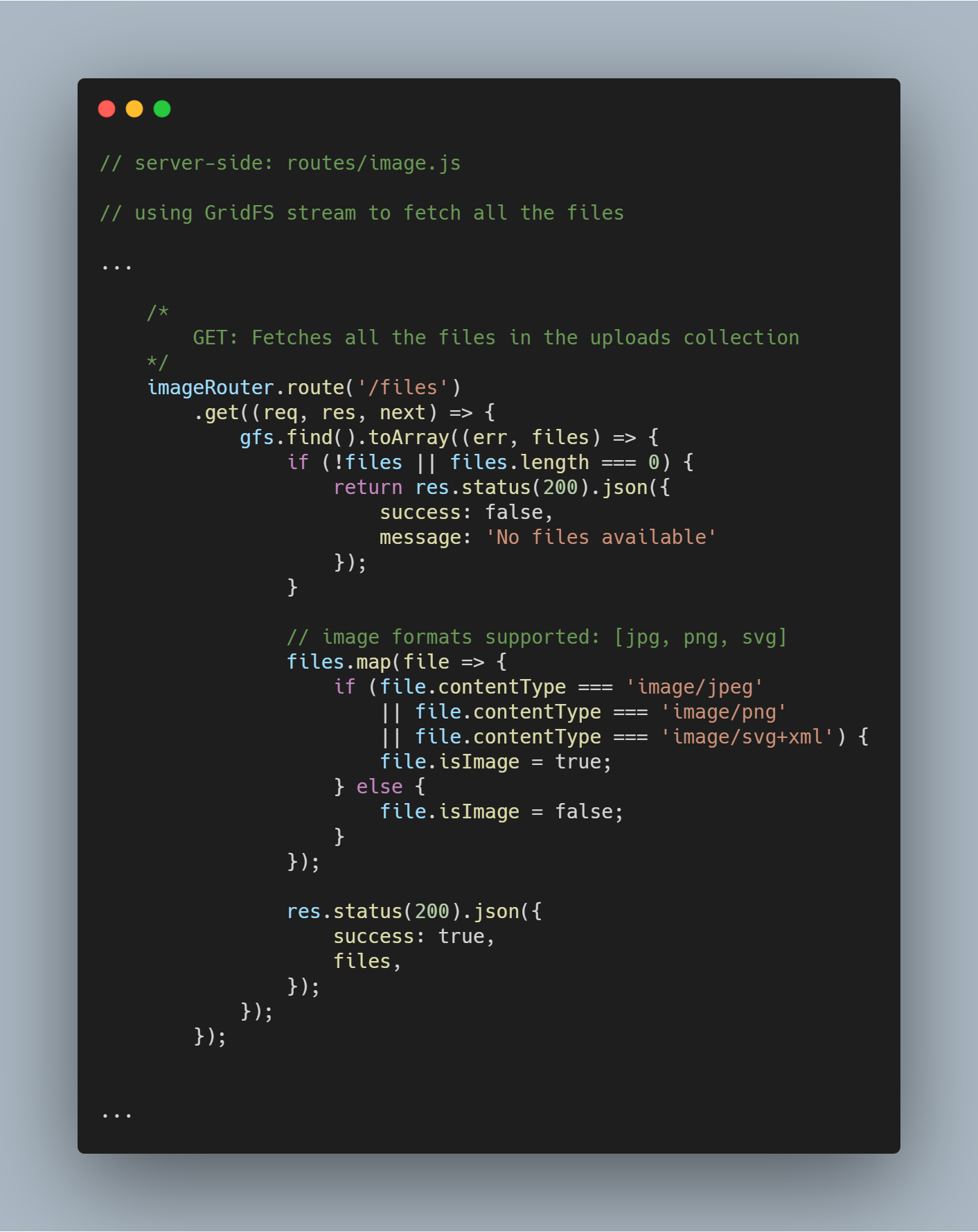
Noutaa kaikki tiedostot tietokannasta
Käyttämällä virtaa, joka on alustettu, voimme hakea kaikki tietyssä tietokannassa olevat tiedostot käyttämällä gfs.find().toArray(...). Kun tiedostot on saatu, kartoitamme ne arrayyn ja lähetämme vastauksen.
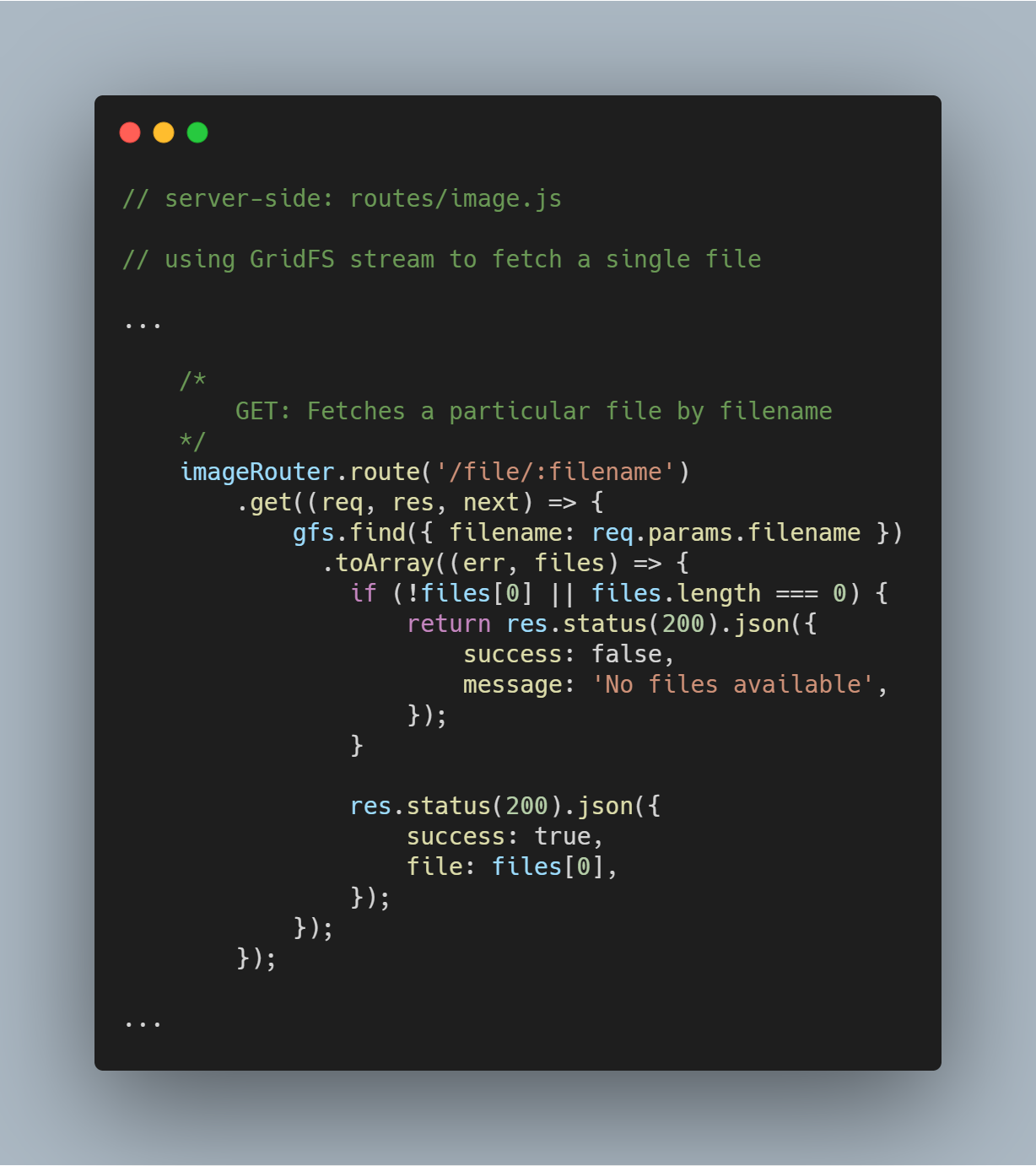
Hakea yksittäinen tiedosto tiedostonimen perusteella
On erittäin yksinkertaista kysyä GridFS:ltä yksittäistä tiedostoa tietyn attribuutin perusteella kuten filename. GridFS-virran avulla voit tehdä tietokannasta kyselyn toiminnon gfs.find({<add query here>}) kautta.
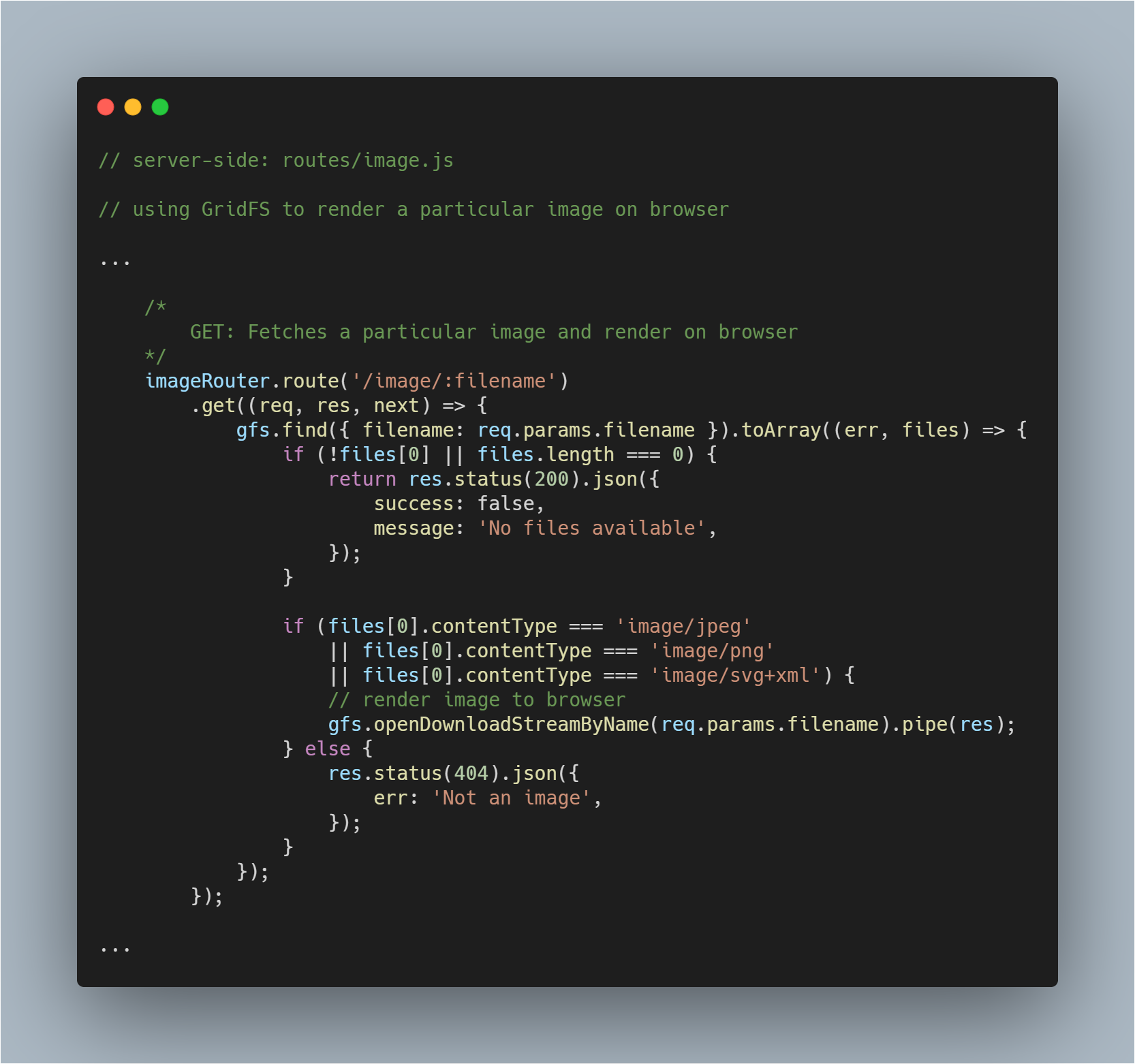
Renderöi haettu kuva selaimelle
Tämä on hieman hankalampi osa, koska sinun ei tarvitse vain hakea tiedostoa tietokannasta vaan myös renderöidä se kuvana kyseisessä selaimessa. Haemme tiedoston normaalisti. Siinä prosessissa ei tapahdu mitään muutosta.
Sitten gfs streamin metodin openDownloadStreamByName() avulla voimme helposti renderöidä kuvan, koska se palauttaa luettavissa olevan streamin. Kun tämä on tehty, voimme käyttää JavaScriptin pipe():tä vastauksen striimaamiseen.
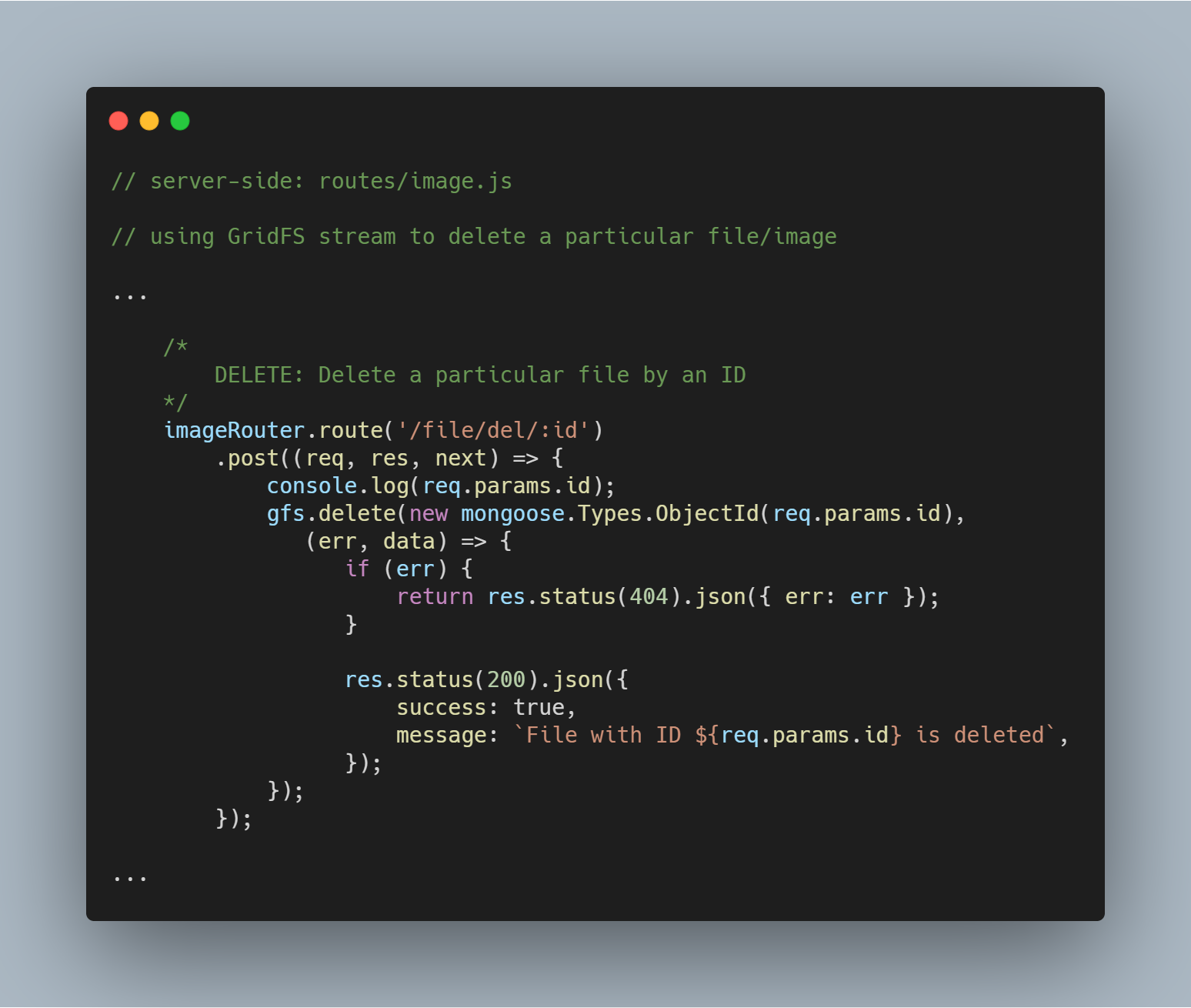
Delete a Particular File by Id
Tiedoston poistaminen on yhtä suoraviivaista. Käytämme stream-metodia delete(), jossa on _id-parametri, kysyäksemme ja poistaaksemme kyseisen tiedoston.
Nämä ovat tärkeimmät toiminnallisuudet, joita storage engine design tarjoaa. Olin hyödyntänyt käsiteltyjä GridFS:n ominaisuuksia luodakseni yksinkertaisen kuvan lataussovelluksen. Voit syventyä koodiin syvällisemmin respositoriossa.
Johtopäätös
Minulta kesti jonkin aikaa ja kohtuullisen paljon kamppailua ymmärtää, miten GridFS:ää voi hyödyntää henkilökohtaisessa projektissa. Tämän vuoksi halusin varmistaa, ettei ainakaan yhden muun henkilön tarvitsisi uhrata saman verran aikaa.
Sen jälkeen suosittelen käyttämään GridFS:ää varoen. Se ei ole hopealuoti kaikkiin tiedostojen tallennusongelmiin. Silti se on näppärä spesifikaatio, joka on hyvä tuntea ja josta on hyvä olla tietoinen.