av Derrick Mwiti, dataanalytiker

Redaktörens anmärkning: Den här handledningen illustrerar hur man kan komma igång med att förutsäga tidsserier med LSTM-modeller. Aktiemarknadsdata är ett utmärkt val för detta eftersom de är ganska regelbundna och allmänt tillgängliga för alla. Ta inte detta som finansiell rådgivning och använd det inte för att göra egna affärer.
I den här handledningen kommer vi att bygga en Python deep learning-modell som kommer att förutsäga det framtida beteendet hos aktiekurser. Vi antar att läsaren är bekant med begreppen för djupinlärning i Python, särskilt Long Short-Term Memory.
Men även om det är svårt att förutsäga det faktiska priset på en aktie kan vi bygga en modell som kan förutsäga om priset kommer att gå upp eller ner. De data och den anteckningsbok som används för den här handledningen finns här. Det är viktigt att notera att det alltid finns andra faktorer som påverkar priset på aktier, till exempel den politiska atmosfären och marknaden. Vi kommer dock inte att fokusera på dessa faktorer i den här handledningen.
Introduktion
LSTMs är mycket kraftfulla i problem med sekvensförutsägelser eftersom de kan lagra tidigare information. Detta är viktigt i vårt fall eftersom det tidigare priset på en aktie är avgörande för att förutsäga dess framtida pris.
Vi börjar med att importera NumPy för vetenskapliga beräkningar, Matplotlib för att plotta grafer och Pandas för att hjälpa till med att ladda och manipulera våra dataset.
Laddning av datasetet
Nästa steg är att ladda in vårt träningsdataset och välja de Open och Highkolumner som vi kommer att använda i vår modellering.
Vi kontrollerar huvudet på vårt dataset för att ge oss en inblick i vilken typ av dataset vi arbetar med.
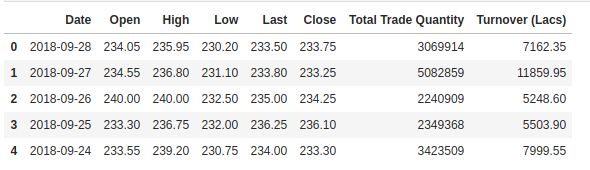
Kolumnen Open är startpriset medan kolumnen Close är slutpriset för en aktie på en viss handelsdag. Kolumnerna High och Low representerar det högsta och lägsta priset för en viss dag.
Skalering av egenskaper
Från tidigare erfarenheter av djupinlärningsmodeller vet vi att vi måste skala våra data för optimal prestanda. I vårt fall använder vi Scikit- Learns MinMaxScaler och skalar vår datamängd till tal mellan noll och ett.
Skapande av data med tidssteg
LSTMs förväntar sig att våra data ska vara i ett specifikt format, vanligtvis en 3D-array. Vi börjar med att skapa data i 60 tidssteg och omvandlar dem till en array med hjälp av NumPy. Därefter omvandlar vi data till en array med 3D-dimension med X_train samplingar, 60 tidsstämplar och en funktion i varje steg.
Byggandet av LSTM
För att bygga LSTM måste vi importera ett par moduler från Keras:
-
Sequentialför att initialisera det neurala nätverket -
Denseför att lägga till ett tätt sammankopplat neuralt nätverkslager -
LSTMför att lägga till lagret för det långa korttidsminnet -
Dropoutför att lägga till dropout-lagren som förhindrar överanpassning
Vi lägger till LSTM-skiktet och lägger senare till ett par Dropout-lager för att förhindra överanpassning. Vi lägger till LSTM-skiktet med följande argument:
- 50 enheter som är dimensionaliteten för utdatarummet
-
return_sequences=Truesom bestämmer om vi ska returnera den sista utmatningen i utdatasekvensen eller hela sekvensen -
input_shapesom formen på vår träningsuppsättning.
När vi definierar Dropout-skikten anger vi 0,2, vilket innebär att 20 % av lagren kommer att slopas. Därefter lägger vi till Dense lagret som anger utgången på 1 enhet. Efter detta kompilerar vi vår modell med den populära adam-optimeraren och ställer in förlusten som mean_squarred_error. Detta kommer att beräkna medelvärdet av de kvadrerade felen. Därefter anpassar vi modellen för att köra på 100 epoker med en batchstorlek på 32. Tänk på att det, beroende på din dators specifikationer, kan ta några minuter att köra klart.
Förutsägelse av framtida aktier med hjälp av testuppsättningen
Först måste vi importera testuppsättningen som vi kommer att använda för att göra våra förutsägelser på.
För att kunna förutsäga framtida aktiekurser måste vi göra ett par saker efter att ha laddat in testuppsättningen:
- Förena träningsuppsättningen och testuppsättningen på 0-axeln.
- Sätt tidssteget till 60 (som tidigare sett)
- Använd
MinMaxScalerför att transformera det nya datasetet - Förändra datasetet som tidigare gjort
Efter att ha gjort förutsägelserna använder vi inverse_transform för att få tillbaka aktiekurserna i normalt läsbart format.
Plottning av resultaten
Slutligt använder vi Matplotlib för att visualisera resultatet av det förutspådda aktiekursen och den verkliga aktiekursen.
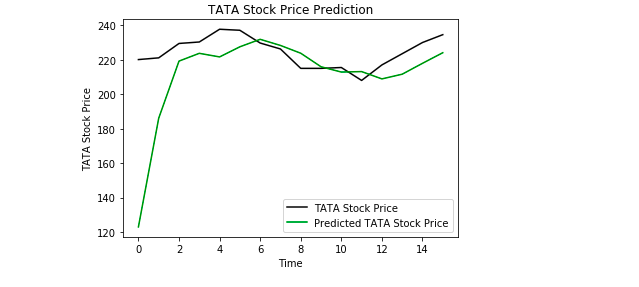
Från plottningen kan vi se att den verkliga aktiekursen steg samtidigt som vår modell också förutspådde att aktiekursen kommer att gå upp. Detta visar tydligt hur kraftfulla LSTMs är för att analysera tidsserier och sekventiella data.
Slutsats
Det finns ett par andra tekniker för att förutsäga aktiekurser, till exempel glidande medelvärden, linjär regression, K-Nearest Neighbours, ARIMA och Prophet. Detta är tekniker som man kan testa på egen hand och jämföra deras prestanda med Keras LSTM. Om du vill lära dig mer om Keras och deep learning kan du hitta mina artiklar om det här och här.
Diskutera det här inlägget på Reddit och Hacker News.
Bio: Jag är en dataanalytiker, en författare och en mentor. Han drivs av att leverera bra resultat i varje uppgift och är mentor hos Lapid Leaders Africa.
Original. Återpublicerad med tillstånd.
Relaterat:
- Introduktion till djupinlärning med Keras
- Introduktion till PyTorch för djupinlärning
- The Keras 4 Step Workflow