De Derrick Mwiti, analist de date

Nota editorului: Acest tutorial ilustrează cum să începeți să prognozați seriile de timp cu modele LSTM. Datele de pe piața bursieră sunt o alegere excelentă pentru acest lucru, deoarece sunt destul de regulate și disponibile pe scară largă pentru toată lumea. Vă rugăm să nu luați acest lucru ca pe un sfat financiar sau să îl folosiți pentru a face tranzacții proprii.
În acest tutorial, vom construi un model de învățare profundă Python care va prezice comportamentul viitor al prețurilor acțiunilor. Presupunem că cititorul este familiarizat cu conceptele de învățare profundă în Python, în special cu memoria pe termen scurt.
În timp ce prezicerea prețului real al unei acțiuni este o ascensiune ascendentă, putem construi un model care va prezice dacă prețul va crește sau va scădea. Datele și caietul de notițe folosite pentru acest tutorial pot fi găsite aici. Este important să rețineți că există întotdeauna și alți factori care afectează prețul acțiunilor, cum ar fi atmosfera politică și piața. Cu toate acestea, nu ne vom concentra pe acești factori pentru acest tutorial.
Introducere
LSTM-urile sunt foarte puternice în problemele de predicție a secvențelor, deoarece sunt capabile să stocheze informații din trecut. Acest lucru este important în cazul nostru, deoarece prețul anterior al unei acțiuni este crucial în prezicerea prețului său viitor.
Vom începe prin a importa NumPy pentru calculul științific, Matplotlib pentru trasarea graficelor și Pandas pentru a ajuta la încărcarea și manipularea seturilor noastre de date.
Încărcarea setului de date
Postul următor este de a încărca setul nostru de date de instruire și de a selecta Open și Highcolumnele pe care le vom folosi în modelarea noastră.
Verificăm capul setului nostru de date pentru a ne da o idee despre tipul de set de date cu care lucrăm.
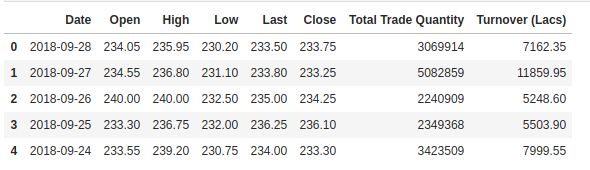
Coloana Open este prețul de pornire, în timp ce coloana Close este prețul final al unei acțiuni într-o anumită zi de tranzacționare. Coloanele High și Low reprezintă cel mai mare și cel mai mic preț pentru o anumită zi.
Feature Scaling
Din experiența anterioară cu modelele de învățare profundă, știm că trebuie să ne scalăm datele pentru o performanță optimă. În cazul nostru, vom folosi MinMaxScaler de la Scikit- Learn și vom scala setul nostru de date la numere între zero și unu.
Crearea datelor cu Timesteps
LSTM-urile se așteaptă ca datele noastre să fie într-un format specific, de obicei o matrice 3D. Începem prin a crea date în 60 de timesteps și prin a le converti într-un array folosind NumPy. Apoi, convertim datele într-un array de dimensiuni 3D cu X_train eșantioane, 60 de timestamp-uri și o caracteristică la fiecare pas.
Construirea LSTM
Pentru a construi LSTM, trebuie să importăm câteva module din Keras:
-
Sequentialpentru inițializarea rețelei neuronale -
Densepentru adăugarea unui strat de rețea neuronală conectată dens -
LSTMpentru adăugarea stratului de memorie pe termen scurt -
Dropoutpentru adăugarea straturilor de renunțare care previn supraadaptarea
Aducem stratul LSTM și mai târziu adăugăm câteva straturi Dropout pentru a preveni supraadaptarea. Adăugăm stratul LSTM cu următoarele argumente:
- 50 de unități care reprezintă dimensionalitatea spațiului de ieșire
-
return_sequences=Truecare determină dacă se returnează ultima ieșire din secvența de ieșire sau secvența completă -
input_shapeca formă a setului nostru de instruire.
Când definim straturile Dropout, specificăm 0,2, ceea ce înseamnă că 20% din straturi vor fi abandonate. Ulterior, adăugăm stratul Dense care specifică ieșirea de 1 unitate. După aceasta, compilăm modelul nostru cu ajutorul popularului optimizator adam și stabilim pierderea ca fiind mean_squarred_error. Acest lucru va calcula media erorilor pătrate. În continuare, potrivim modelul pentru a rula pe 100 de epoci cu o dimensiune a lotului de 32. Rețineți că, în funcție de specificațiile computerului dumneavoastră, acest lucru ar putea dura câteva minute pentru a termina de rulat.
Predicting Future Stock using the Test Set
În primul rând, trebuie să importăm setul de teste pe care îl vom folosi pentru a face predicțiile noastre.
Pentru a prezice prețurile viitoare ale acțiunilor trebuie să facem câteva lucruri după ce încărcăm setul de testare:
- Mergeți setul de instruire și setul de testare pe axa 0.
- Setați pasul de timp ca fiind 60 (așa cum s-a văzut anterior)
- Utilizați
MinMaxScalerpentru a transforma noul set de date - Reformați setul de date așa cum s-a făcut anterior
După efectuarea predicțiilor, folosim inverse_transform pentru a obține înapoi prețurile acțiunilor în format normal, lizibil.
Plotting the Results
În cele din urmă, folosim Matplotlib pentru a vizualiza rezultatul prețului prezis al acțiunilor și prețul real al acțiunilor.
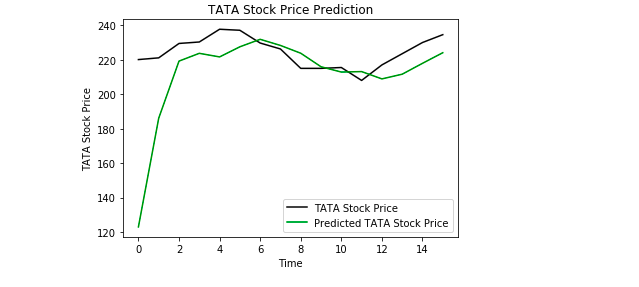
Din grafic putem vedea că prețul real al acțiunilor a crescut în timp ce modelul nostru a prezis, de asemenea, că prețul acțiunilor va crește. Acest lucru arată în mod clar cât de puternice sunt LSTM-urile pentru analiza seriilor de timp și a datelor secvențiale.
Concluzie
Există alte câteva tehnici de predicție a prețurilor acțiunilor, cum ar fi mediile mobile, regresia liniară, K-Nearest Neighbours, ARIMA și Prophet. Acestea sunt tehnici pe care cineva le poate testa pe cont propriu și le poate compara performanța cu Keras LSTM. Dacă doriți să aflați mai multe despre Keras și învățarea profundă, puteți găsi articolele mele pe această temă aici și aici.
Discută această postare pe Reddit și Hacker News.
Bio: Derrick Mwiti este un analist de date, un scriitor și un mentor. El este condus de livrarea de rezultate excelente în fiecare sarcină și este mentor la Lapid Leaders Africa.
Original. Reluat cu permisiune.
Relaționat:
- Introducere la Deep Learning cu Keras
- Introducere la PyTorch pentru Deep Learning
- The Keras 4 Step Workflow
.