Stocarea fișierelor este o caracteristică importantă necesară în mai multe procese din diferite tipuri de aplicații. Existența unor procese precum Content Delivery Networks (CDNs), configurate prin intermediul opțiunilor cloud de la terțe părți, precum Amazon Web Services, și a opțiunilor locale de stocare a fișierelor au facilitat întotdeauna construirea unei astfel de caracteristici.
Cu toate acestea, conceptul de stocare a fișierelor direct într-o bază de date prin intermediul unui singur apel API m-a intrigat de ceva timp. Aici a intrat în scenă GridFS pentru mine.

GridFS – A Layman’s Understanding
MongoDB are o specificație de driver pentru a încărca și a prelua fișiere din el numită GridFS. GridFS vă permite să stocați și să preluați fișiere, inclusiv cele care depășesc limita de dimensiune a documentelor BSON de 16 MB.
GridFS practic ia un fișier și îl împarte în mai multe bucăți care sunt stocate ca documente individuale în două colecții:
- colecția
chunk(stochează părțile documentului) și - colecția
file(stochează metadatele suplimentare consecvente).
Care bucată este limitată la 255 KB în dimensiune. Aceasta înseamnă că ultimul chunk este, în mod normal, fie egal, fie mai mic de 255 KB. Sună destul de îngrijit.
Când citiți din GridFS, driverul reasamblează toate chunks-urile după cum este necesar. Acest lucru înseamnă că puteți citi secțiuni ale unui fișier în funcție de intervalul de interogare. Cum ar fi ascultarea unui segment dintr-un fișier audio sau preluarea unei secțiuni dintr-un fișier video.
Nota: Este de preferat să se utilizeze GridFS pentru stocarea fișierelor care depășesc în mod normal limita de dimensiune de 16 MB. Pentru fișiere mai mici, se recomandă utilizarea formatului BinData pentru a stoca fișierele în documente unice.
Acesta este un rezumat al modului în care GridFS funcționează în general. Este timpul să ne băgăm picioarele în niște cod de lucru și să vedem cum se implementează un sistem ca atare.
Suficientă vorbărie, arată-mi codul
Pentru configurația noastră folosim Node.js cu acces la o instanță cloud de MongoDB. Puteți găsi depozitul de cod pentru aplicația de probă aici.
 tarique93102GitHub
tarique93102GitHub 
Ne vom concentra complet pe segmentele de cod care se referă la funcționalitățile GridFS. Vom învăța cum să-l configurăm și să-l folosim pentru a stoca fișiere, a prelua fișiere sau un anumit fișier și a șterge un anumit fișier. Să începem atunci.
Inițializați motorul de stocare
Pachetele necesare pentru a inițializa motorul sunt multer-gridfs-storage și multer. De asemenea, folosim middleware-ul method-override pentru a activa operația de ștergere a fișierelor. Modulul npm crypto este folosit pentru a cripta numele fișierelor la stocarea și citirea din baza de date.
După ce motorul de stocare care folosește GridFS este inițializat, trebuie doar să îl apelați folosind middleware-ul multer. Acesta este apoi trecut la ruta respectivă care execută diversele operații de stocare a fișierelor.
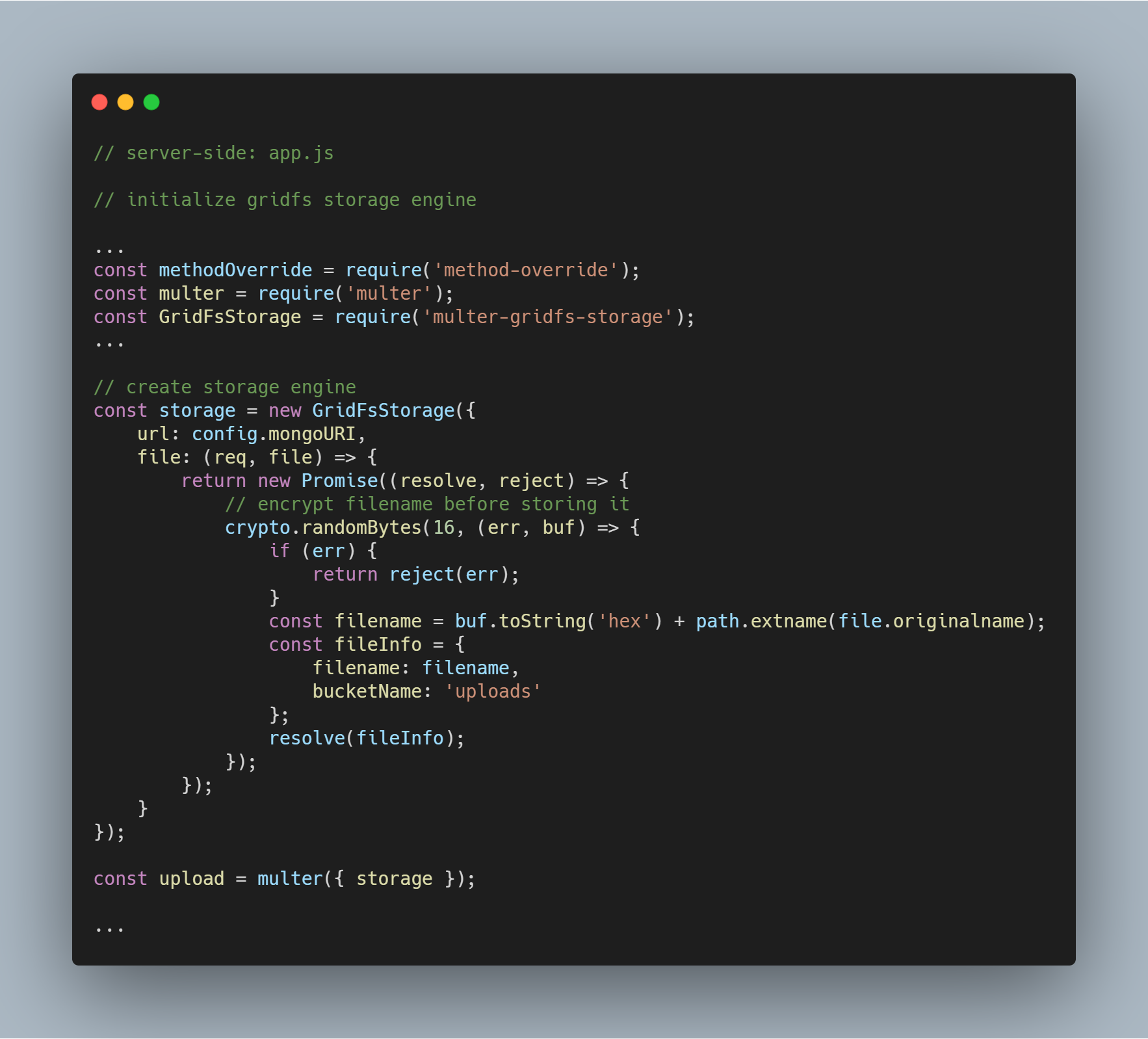
Inițializarea fluxului GridFS
Inițializăm un flux GridFS așa cum se vede în codul de mai jos. Fluxul este necesar pentru a citi fișierele din baza de date și, de asemenea, pentru a ajuta la redarea unei imagini către un browser atunci când este necesar.
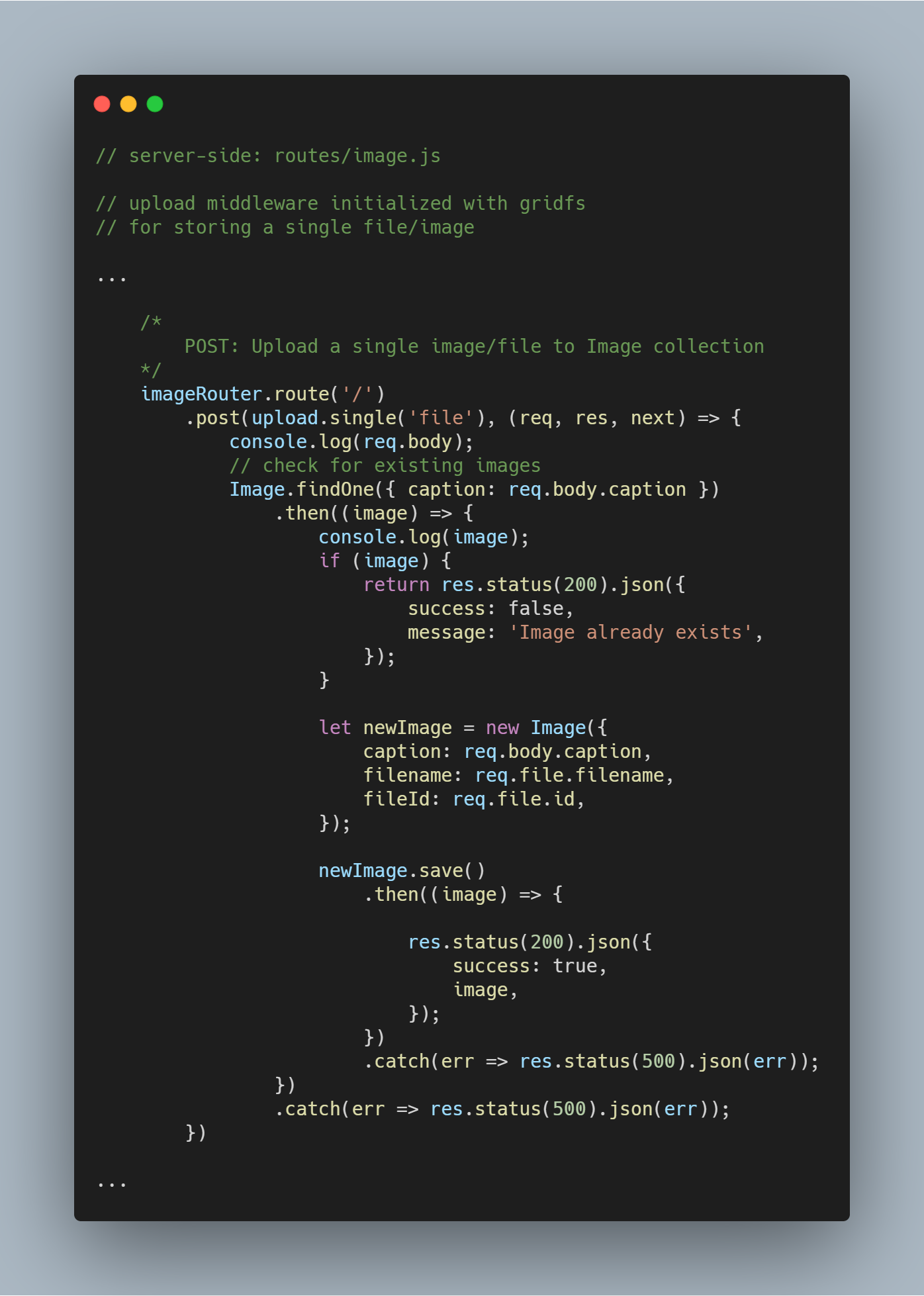
Upload a Single File or Image
Reutilizăm middleware-ul de încărcare pe care l-am creat mai devreme.
Nota: Numele file este folosit ca parametru în upload.single() deoarece avem cheia cu un nume similar care poartă fișierul trimis de client.
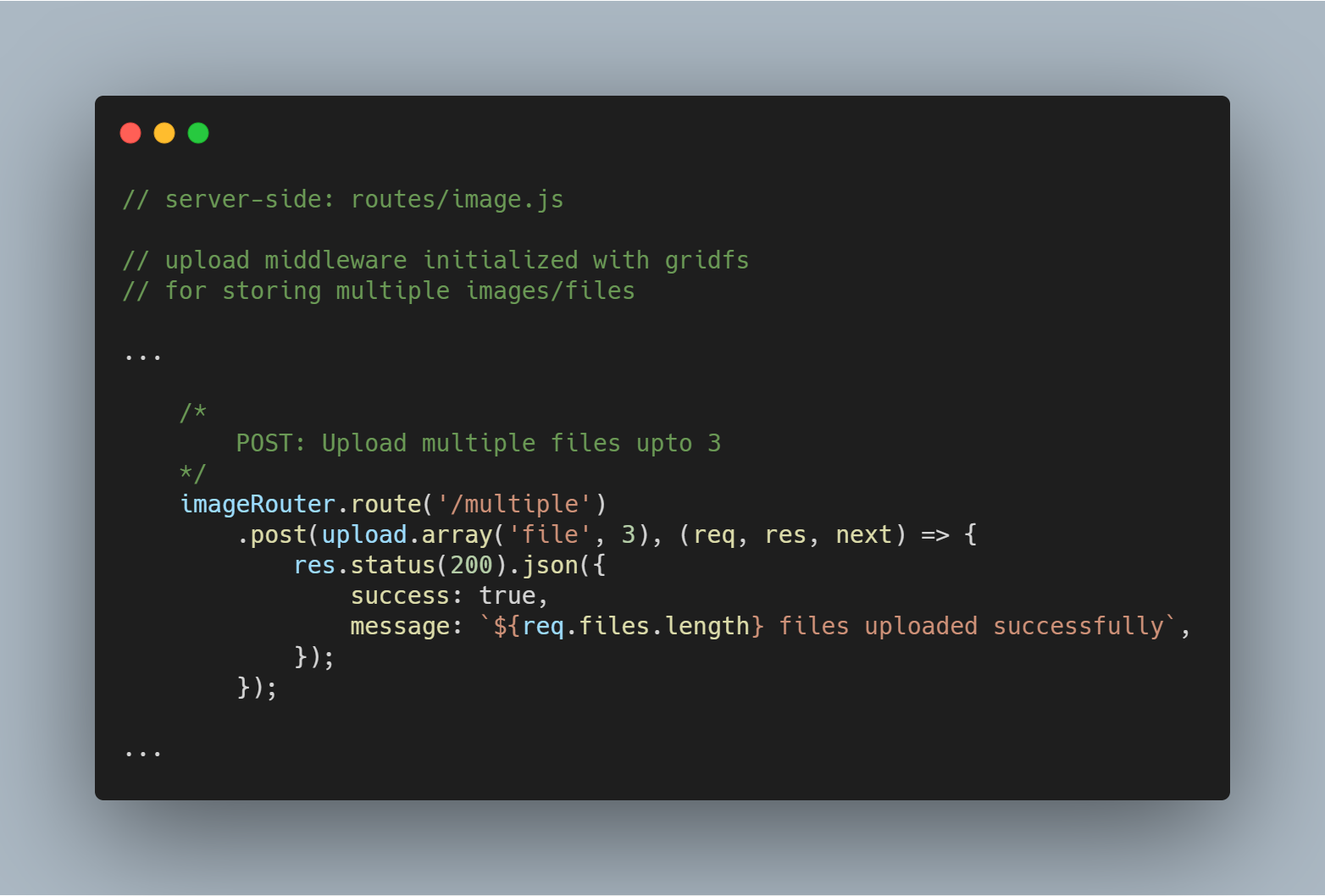
Încărcați mai multe fișiere sau imagini
De asemenea, putem încărca mai multe fișiere în același timp. În loc de upload.single(), trebuie să folosim pur și simplu upload.multiple(<number of files>).
Nota: Numărul de fișiere încărcate poate fi mai mic decât numărul definit de fișiere.
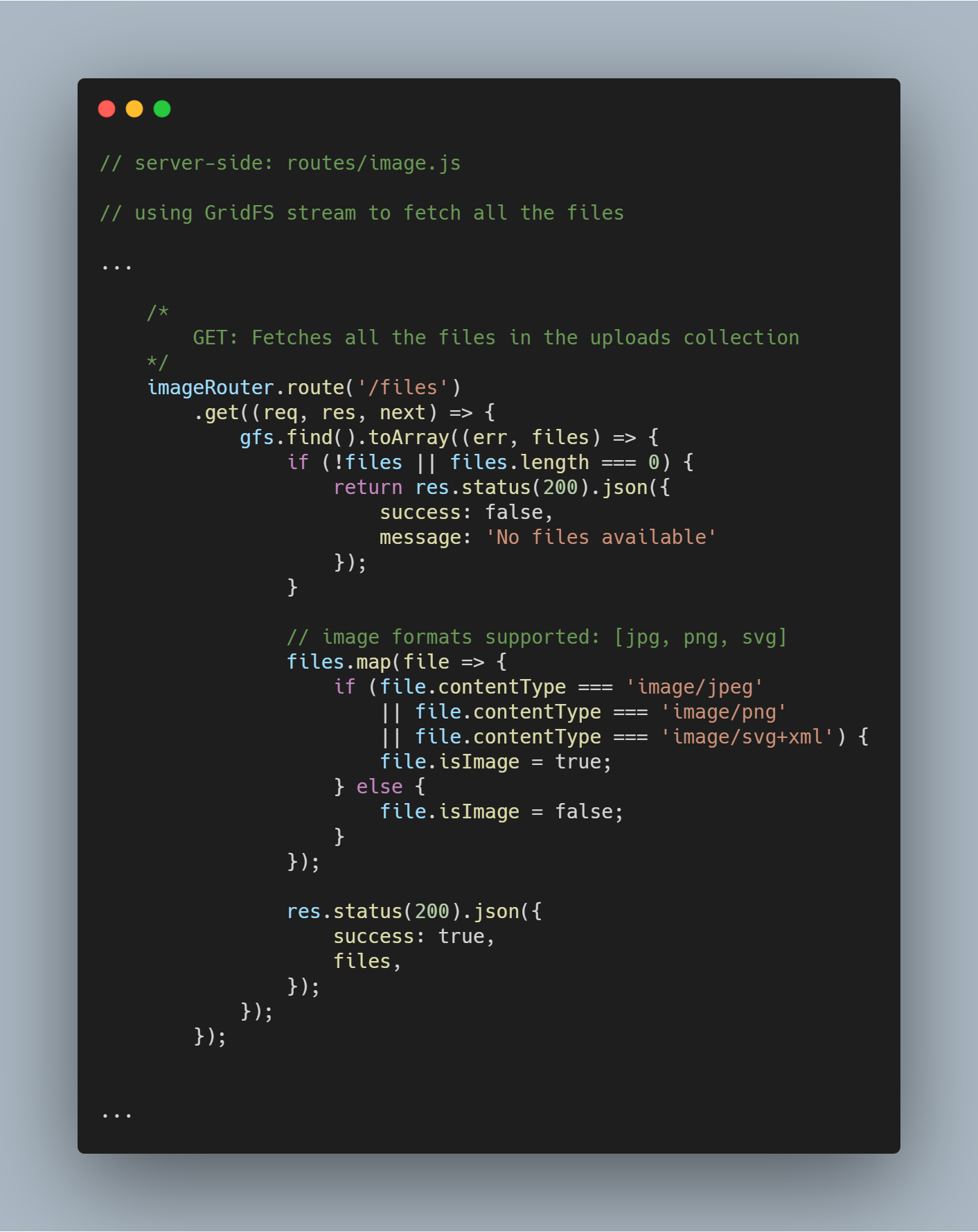
Fetch all Files From Database
Utilizând fluxul inițializat putem prelua toate fișierele din baza de date respectivă folosind gfs.find().toArray(...). Odată ce fișierele sunt obținute, le mapăm într-o matrice și trimitem răspunsul.
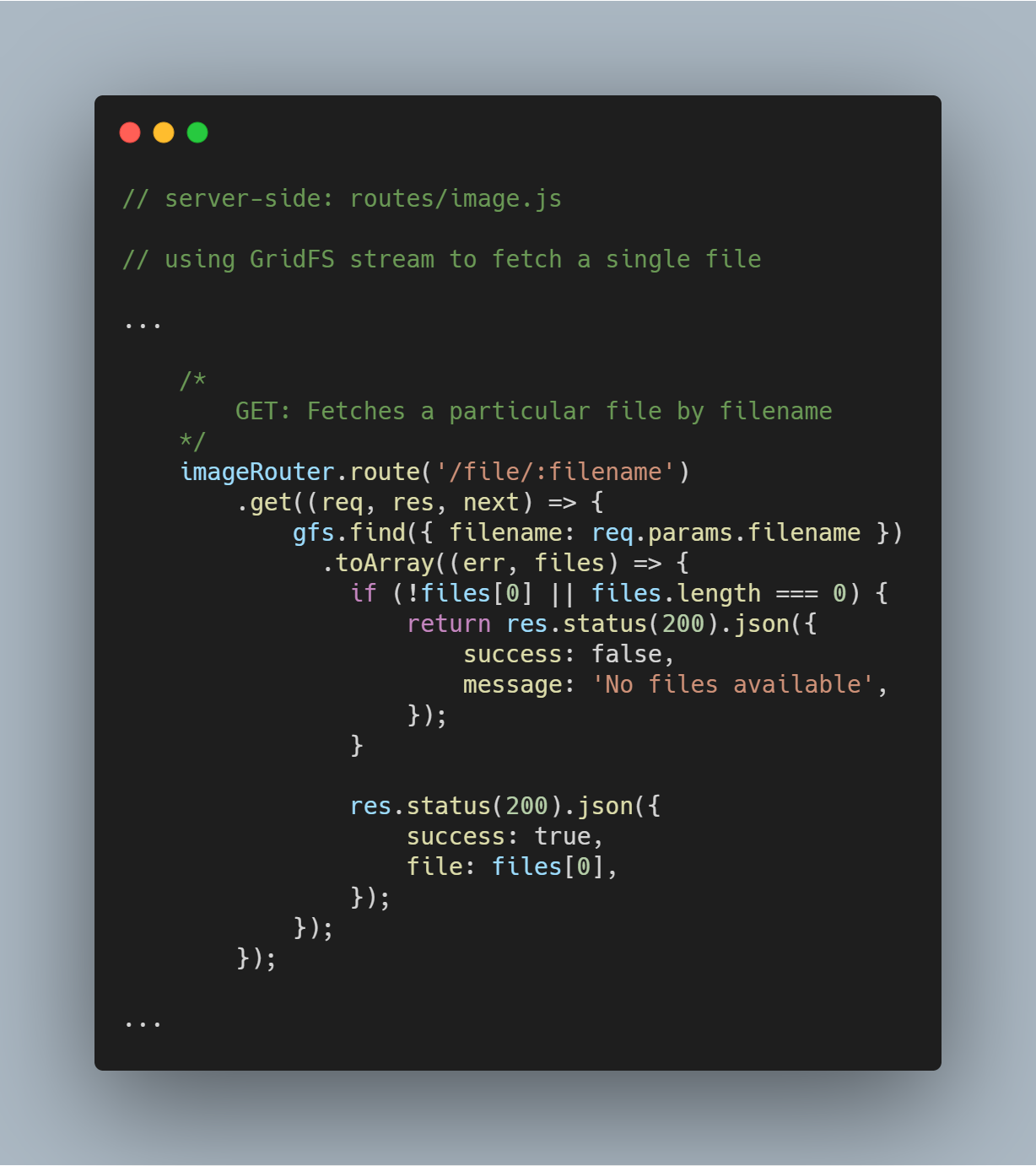
Fetch a Single File By Filename
Este foarte simplu să interogăm GridFS pentru un singur fișier pe baza unui atribut specific, cum ar fi filename. Utilizând fluxul GridFS, puteți interoga baza de date prin intermediul funcției gfs.find({<add query here>}).
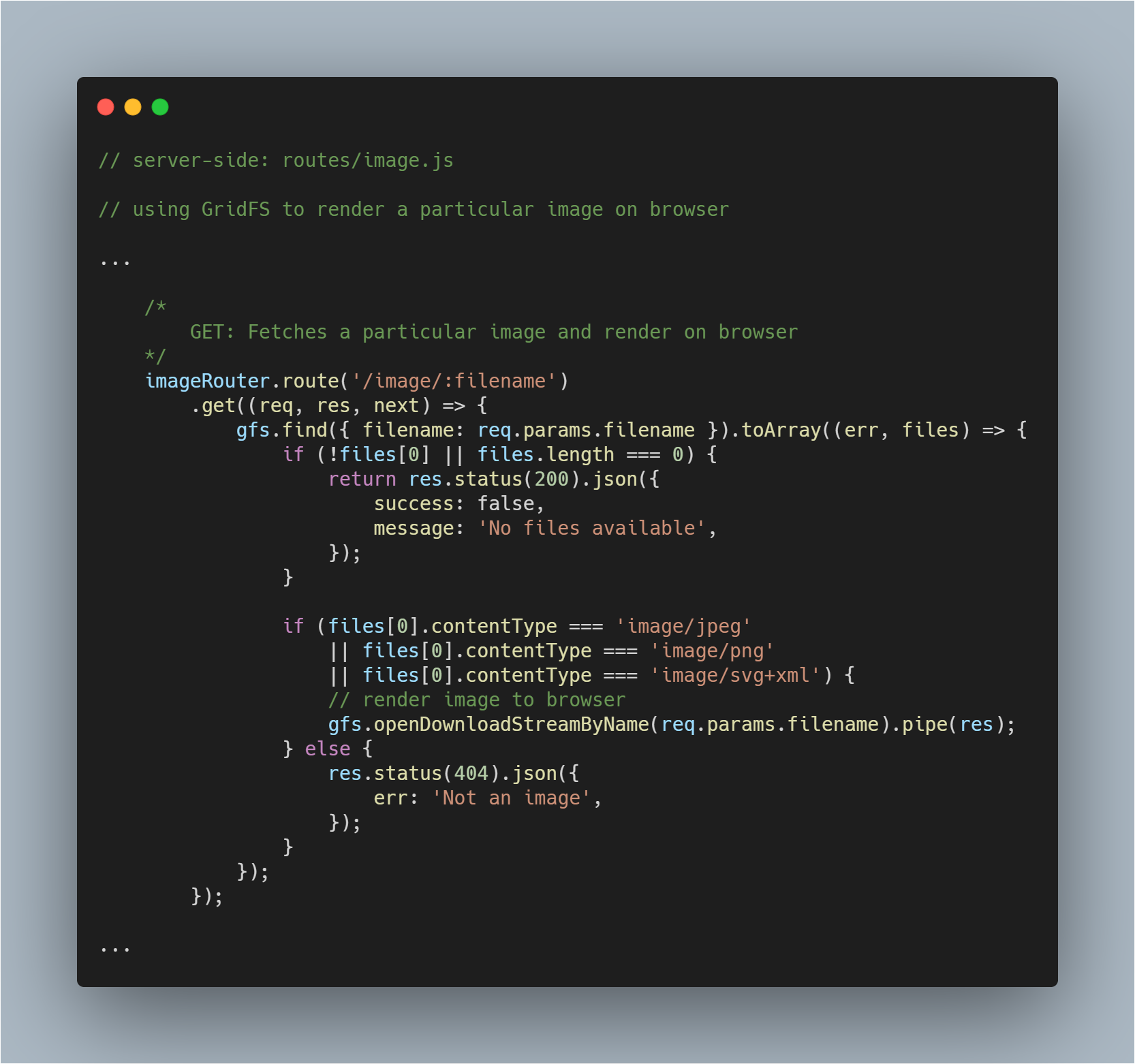
Renunțați o imagine obținută în browser
Aceasta este o parte puțin mai complicată, deoarece trebuie nu numai să preluați un fișier din baza de date, ci și să îl redați ca imagine în browserul respectiv. Preluăm fișierul în mod normal. Nici o schimbare în acest proces.
Apoi, cu ajutorul metodei openDownloadStreamByName() pe gfs stream, putem reda cu ușurință o imagine, deoarece aceasta returnează un flux lizibil. După ce am făcut acest lucru, putem folosi pipe() din JavaScript pentru a transmite în flux răspunsul.
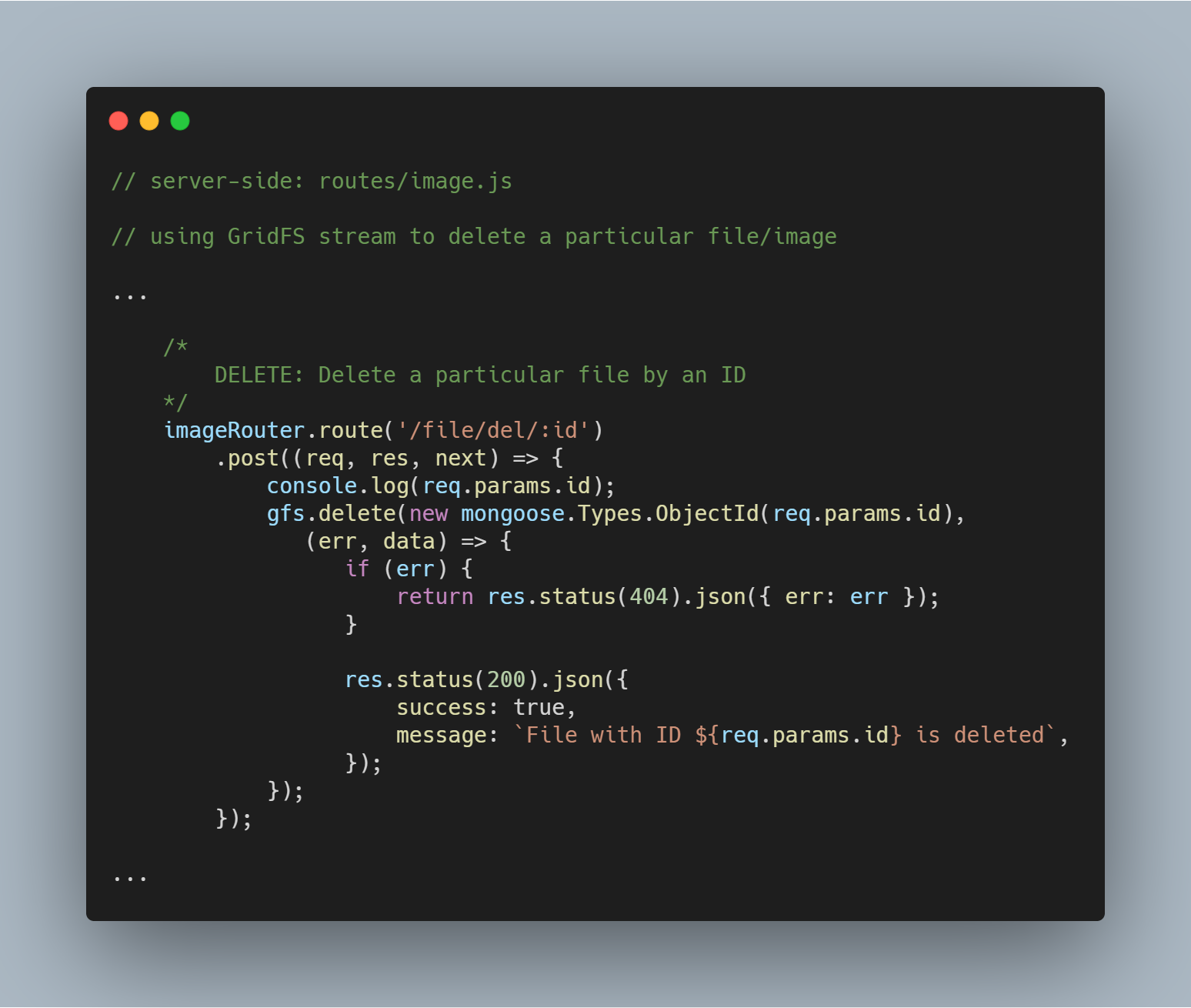
Delete a Particular File by Id
Deletarea unui fișier este la fel de simplă. Utilizăm metoda stream delete() cu parametrul _id pentru a interoga și a șterge fișierul în cauză.
Acestea sunt principalele funcționalități oferite de proiectarea motorului de stocare. Am exploatat caracteristicile GridFS discutate pentru a crea o aplicație simplă de încărcare de imagini. Puteți aprofunda codul în respository.
Concluzie
Am avut nevoie de ceva timp și de o cantitate decentă de luptă pentru a înțelege cum să folosesc GridFS pentru un proiect personal. Din această cauză, am vrut să mă asigur că cel puțin o altă persoană nu a trebuit să investească aceeași cantitate de timp.
După ce am spus asta, aș recomanda utilizarea GridFS cu precauție. Nu este un glonț de argint pentru toate preocupările dvs. de stocare a fișierelor. Totuși, este o specificație ingenioasă pe care trebuie să o cunoașteți și de care trebuie să fiți conștienți.