O armazenamento de arquivos é um recurso importante exigido em múltiplos processos através de vários tipos de aplicações. A existência de processos como Content Delivery Networks (CDNs), configurados através de opções de nuvem de terceiros como Amazon Web Services, e opções de armazenamento de arquivos locais sempre facilitaram a construção de tal recurso.
No entanto, o conceito de armazenar arquivos diretamente em um banco de dados através de uma única chamada de API me intrigou por bastante tempo. Foi aí que o GridFS entrou em cena para mim.

GridFS – A Layman’s Understanding
MongoDB tem uma especificação de driver para carregar e recuperar arquivos dele chamado GridFS. GridFS permite que você armazene e recupere arquivos, o que inclui aqueles que excedem o limite de tamanho do documento BSON de 16 MB.
GridFS basicamente pega um arquivo e o divide em vários pedaços que são armazenados como documentos individuais em duas coleções:
- a
chunkcoleção (armazena as partes do documento), e - a
filecoleção (armazena os consequentes metadados adicionais).
Cada pedaço é limitado a 255 KB de tamanho. Isto significa que o último pedaço é normalmente igual ou inferior a 255 KB. Parece bastante arrumado.
Quando você lê do GridFS, o driver remonta todos os pedaços conforme necessário. Isto significa que você pode ler seções de um arquivo de acordo com o seu intervalo de consulta. Tal como ouvir um segmento de um ficheiro de áudio ou ir buscar uma secção de um ficheiro de vídeo.
Nota: É preferível usar o GridFS para armazenar arquivos que normalmente excedem o limite de 16 MB de tamanho. Para arquivos menores, recomenda-se usar o formato BinData para armazenar os arquivos em documentos únicos.
Este resumo resume como o GridFS funciona em geral. Tempo para mergulhar os pés em algum código de trabalho e ver como implementar um sistema como tal.
Suficiente Conversa, Mostre-me o Código
Estamos usando o Node.js com acesso a uma instância em nuvem do MongoDB para nossa configuração. Você pode encontrar o repositório de código para a aplicação de exemplo aqui.
 tarique93102GitHub
tarique93102GitHub 
Nos focaremos completamente nos segmentos do código que se relacionam com as funcionalidades do GridFS. Vamos aprender como configurá-lo e usá-lo para armazenar arquivos, recuperar arquivos ou um determinado arquivo, e excluir um determinado arquivo. Vamos começar então.
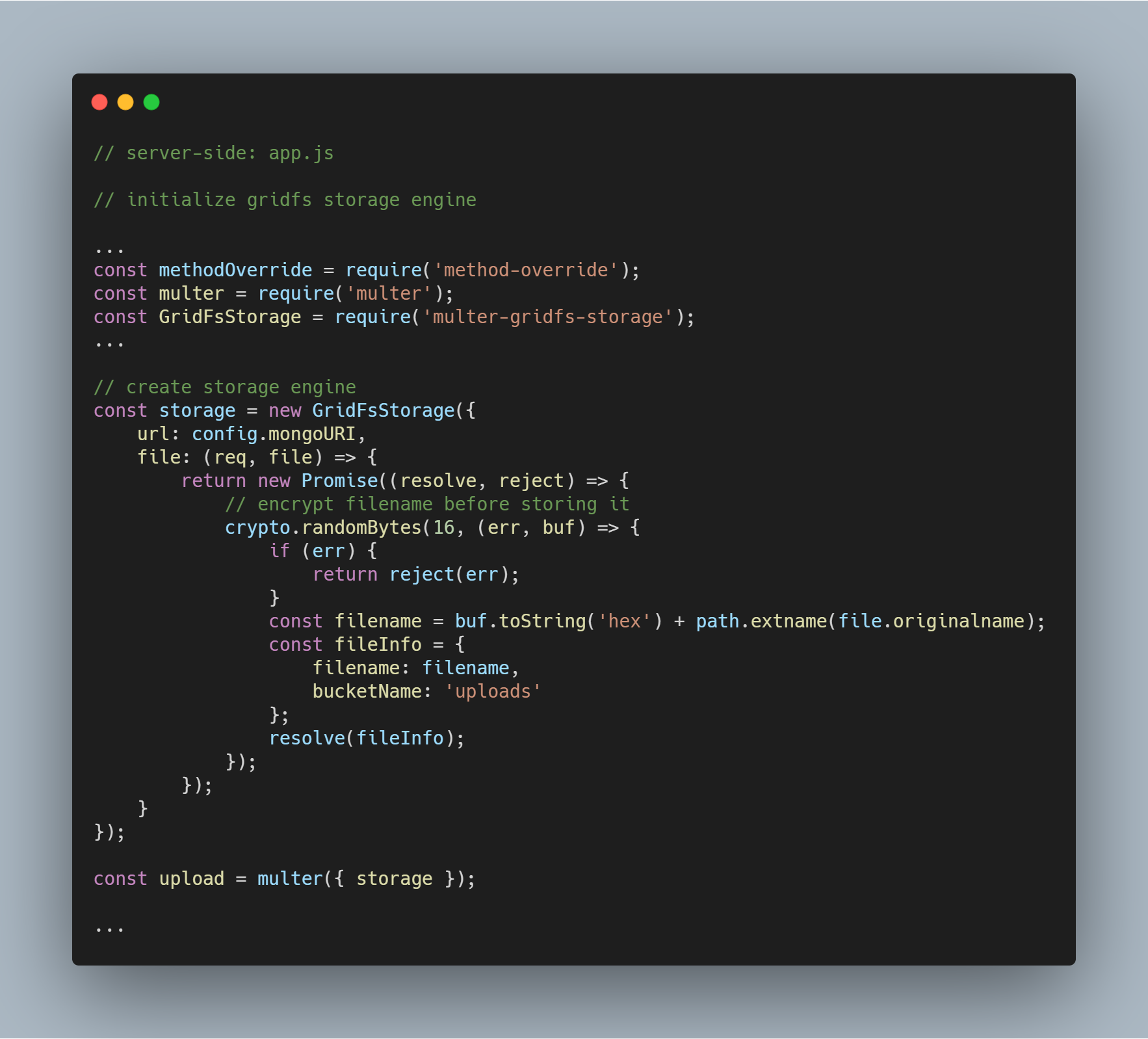
Initializar o motor de armazenamento
Os pacotes necessários para inicializar o motor são multer-gridfs-storage e multer. Nós também usamos method-override middleware para habilitar a operação de exclusão de arquivos. O módulo npm crypto é usado para criptografar os nomes dos arquivos ao serem armazenados e lidos do banco de dados.
A partir do momento em que o mecanismo de armazenamento usando GridFS é inicializado, você só precisa chamá-lo usando o middleware multer. Ele é então passado para a respectiva rota executando as várias operações de armazenamento de arquivos.
Initializar GridFS Stream
Inicializamos um stream GridFS como visto no código abaixo. O fluxo é necessário para ler os arquivos da base de dados e também para ajudar a renderizar uma imagem para um navegador quando necessário.
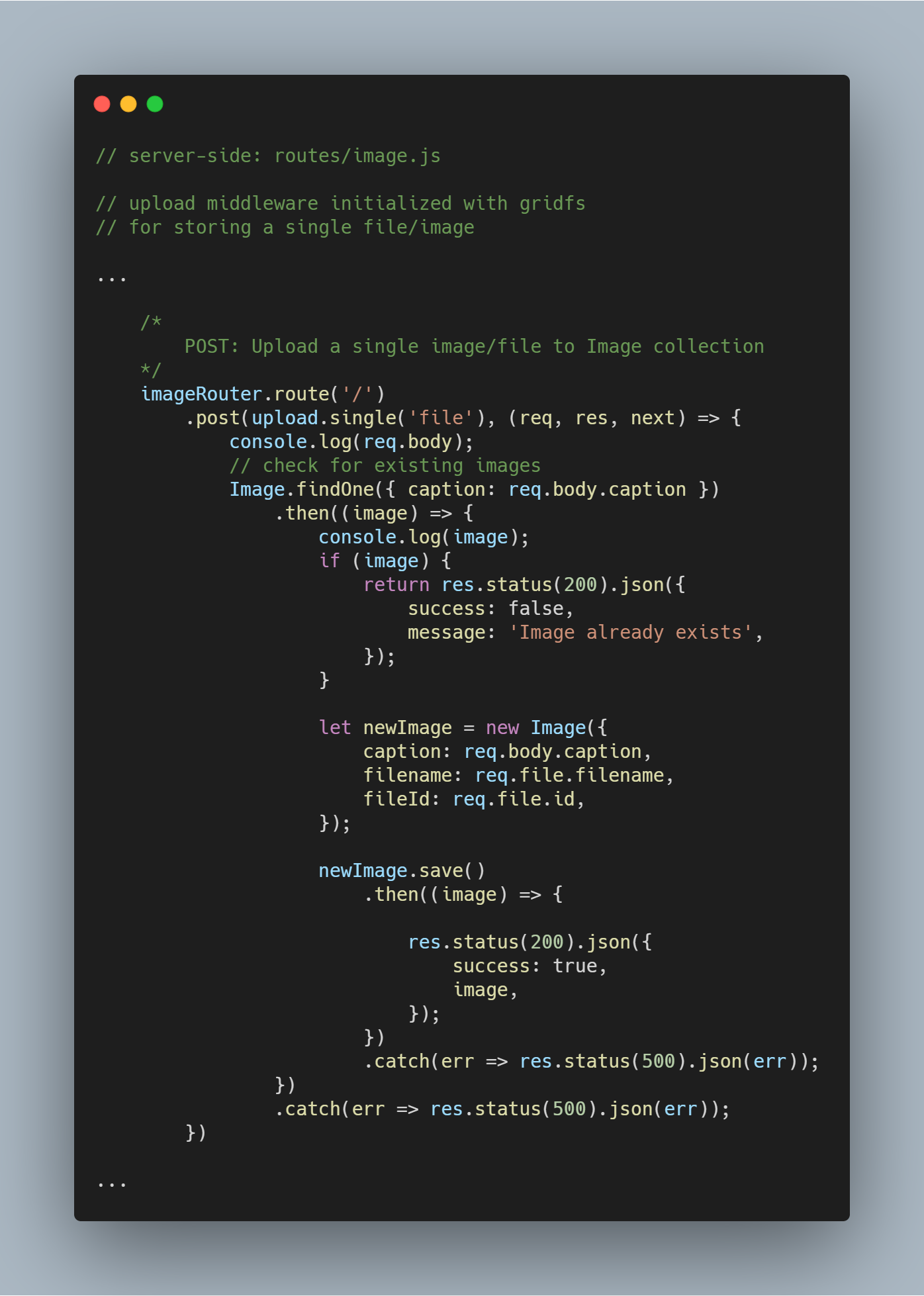
Carregar um único ficheiro ou imagem
Reutilizamos o middleware de carregamento que tínhamos criado anteriormente.
Nota: O nome file é usado como parâmetro em upload.single() uma vez que temos a chave com um nome similar carregando o arquivo que está sendo enviado pelo cliente.
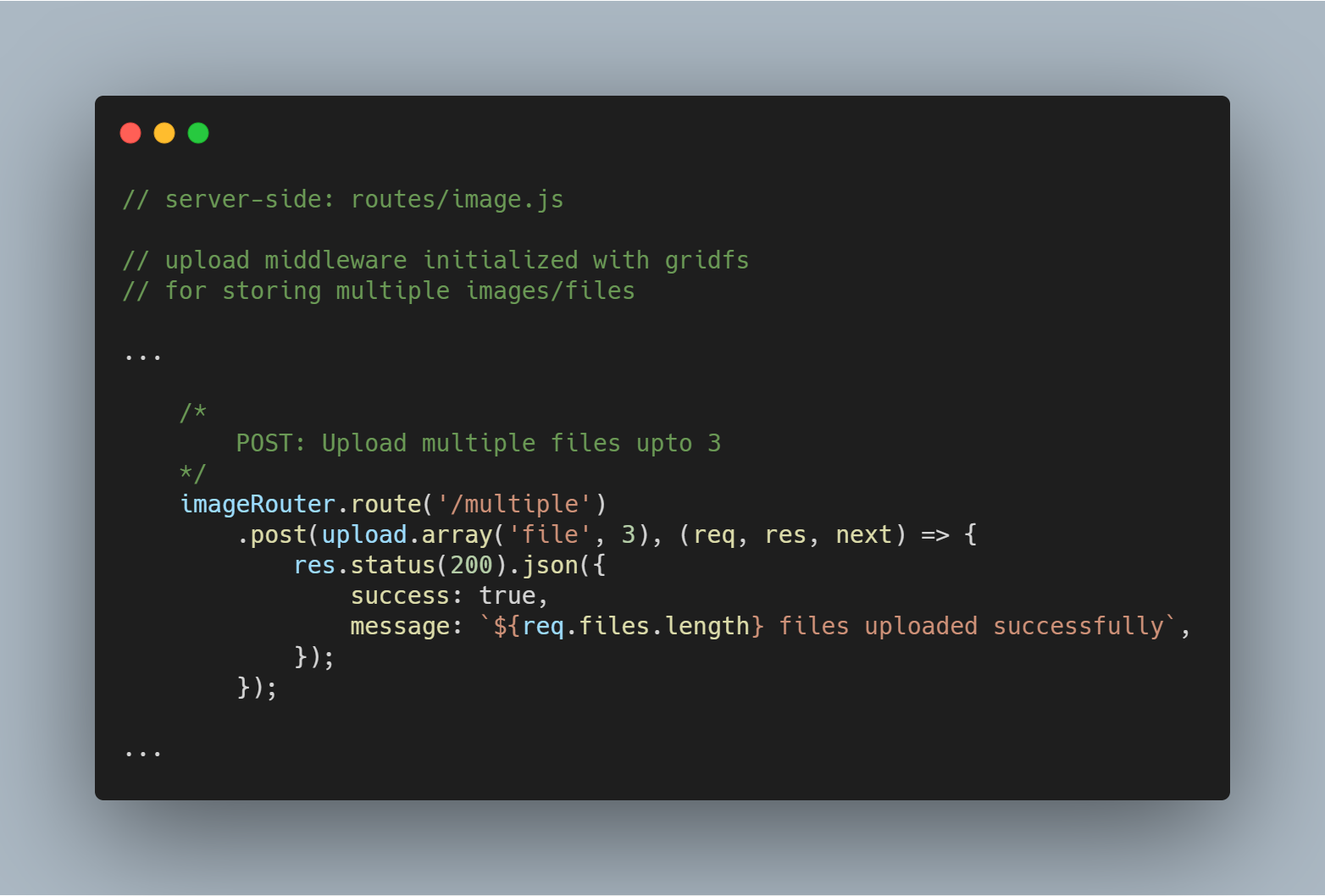
Carregar Vários Arquivos ou Imagens
Também podemos carregar vários arquivos ao mesmo tempo. Ao invés de upload.single(), nós temos que simplesmente usar upload.multiple(<number of files>).
Nota: O número de ficheiros carregados pode ser inferior ao número definido de ficheiros.
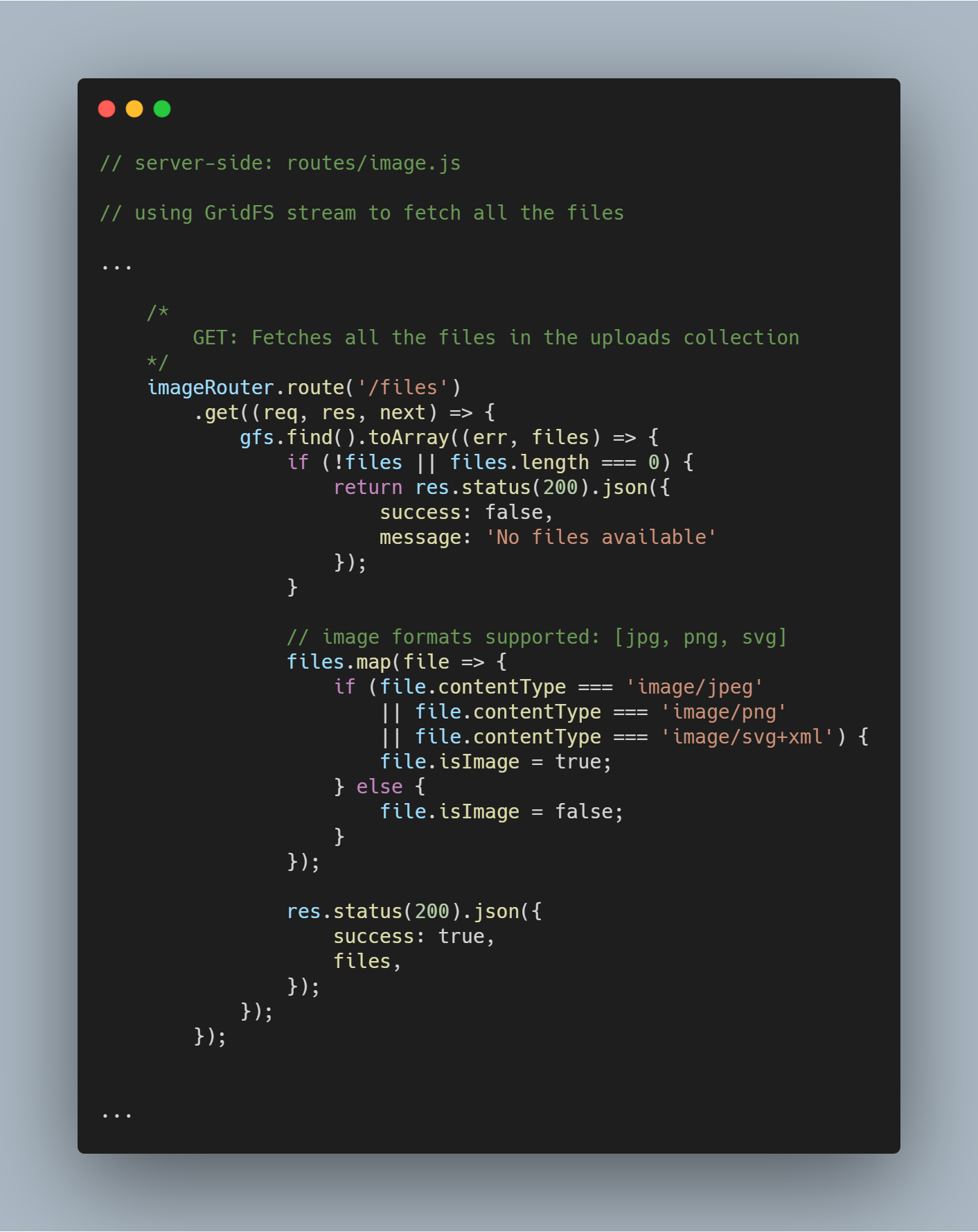
Voltar todos os ficheiros da base de dados
Utilizando o stream inicializado podemos ir buscar todos os ficheiros da base de dados em particular usando gfs.find().toArray(...). Uma vez que os arquivos são obtidos mapeamos para um array e enviamos a resposta.
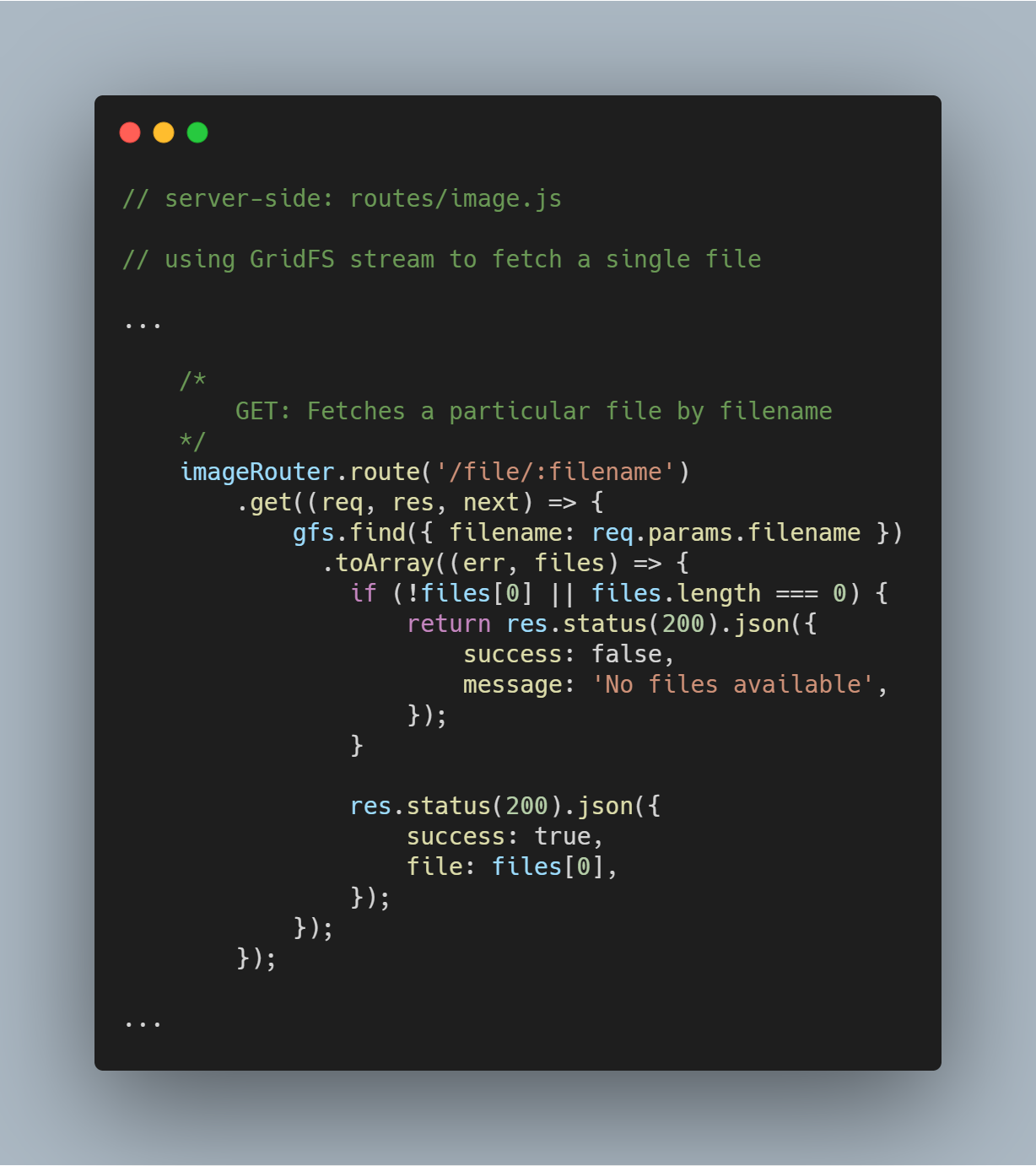
Fetch a Single File By Filename
É super simples consultar o GridFS para um único arquivo baseado em um atributo específico como filename. Usando o fluxo GridFS, você pode consultar o banco de dados através da função gfs.find({<add query here>}).
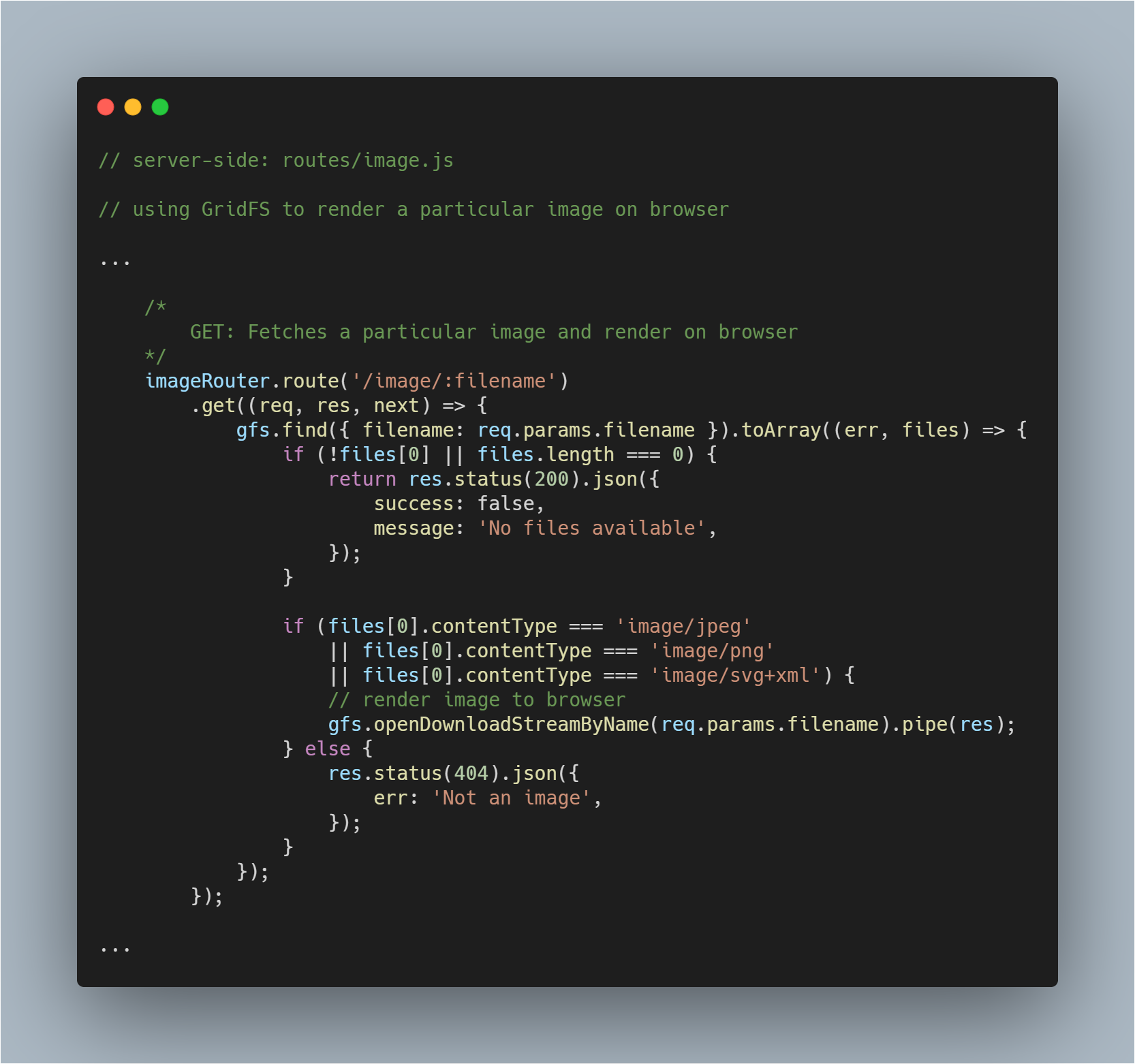
Render uma imagem buscada para o browser
Esta é uma parte um pouco mais complicada uma vez que você tem que não só buscar um arquivo do banco de dados, mas também renderizá-lo como uma imagem no respectivo browser. Nós buscamos o arquivo normalmente. Nenhuma alteração nesse processo.
Então, com a ajuda do método openDownloadStreamByName() no fluxo gfs, podemos facilmente renderizar uma imagem enquanto ela retorna um fluxo legível. Tendo feito isso, podemos usar o JavaScript’s pipe() para fazer stream da resposta.
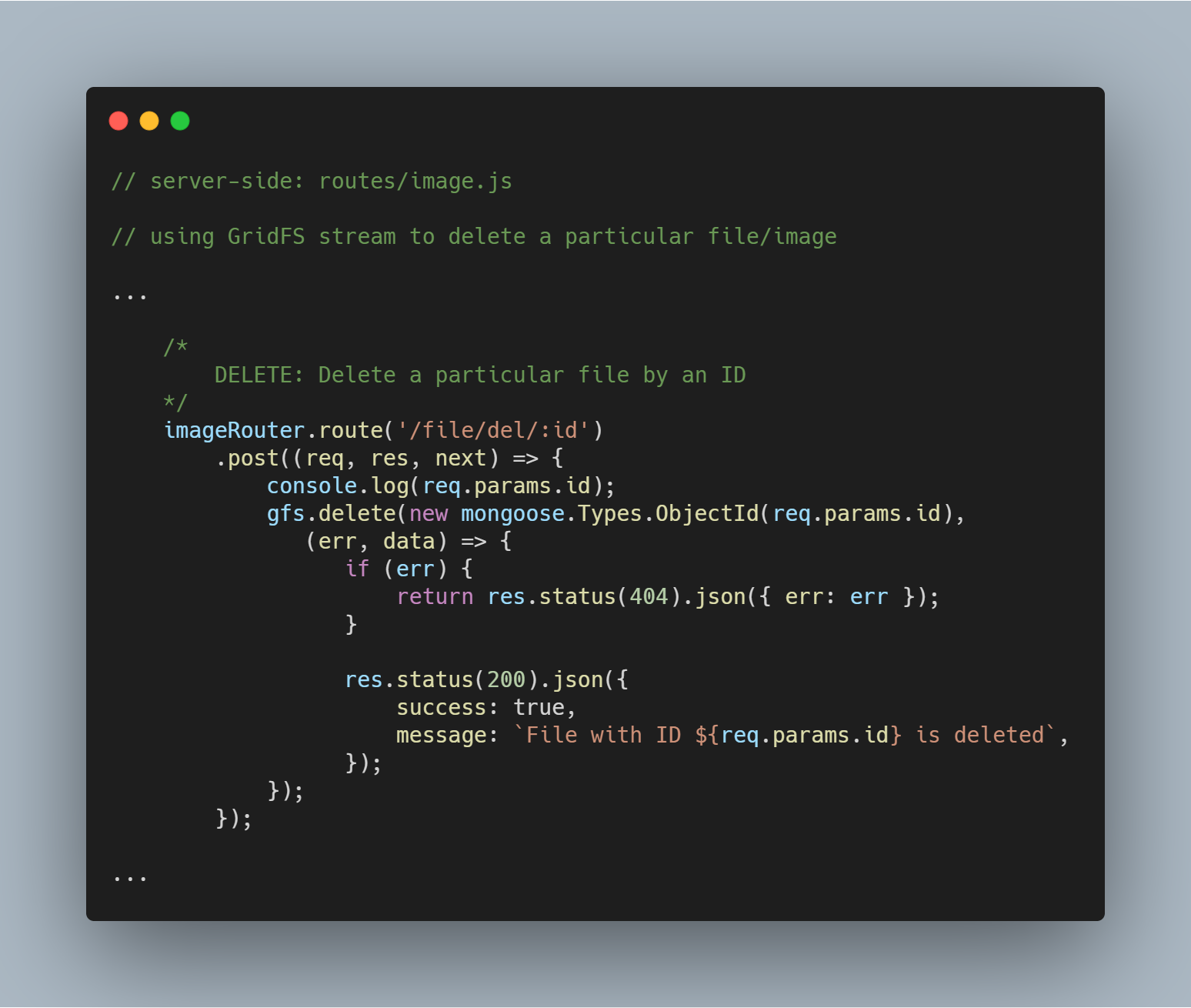
Delete a Particular File by Id
Deleting a file is equally straight-forward. Usamos o método de fluxo de dados delete() com parâmetro _id para consultar e excluir o arquivo em questão.
Essas são as principais funcionalidades oferecidas pelo projeto do motor de armazenamento. Eu tinha aproveitado as funcionalidades do GridFS discutidas para criar uma aplicação simples de carregamento de imagens. Você pode se aprofundar no código no respositório.
Conclusion
Levou algum tempo e uma quantidade decente de luta para entender como fazer uso do GridFS para um projeto pessoal. Por causa disso, eu queria ter certeza de que pelo menos uma outra pessoa não teria que investir o mesmo tempo.
Dizendo isso, eu recomendaria o uso do GridFS com cautela. Não é uma bala de prata para todas as suas preocupações de armazenamento de arquivos. Mesmo assim, é uma especificação elegante de se conhecer e estar atento.