Przechowywanie plików jest ważną cechą wymaganą w wielu procesach w różnych typach aplikacji. Istnienie procesów takich jak Content Delivery Networks (CDNs), skonfigurowanych przez opcje chmury stron trzecich, takich jak Amazon Web Services, i lokalne opcje przechowywania plików zawsze ułatwiały budowanie takiej funkcji.
Jednakże, koncepcja przechowywania plików bezpośrednio w bazie danych poprzez pojedyncze wywołanie API intrygowała mnie od dłuższego czasu. To właśnie tam pojawił się dla mnie GridFS.

GridFS – A Layman’s Understanding
MongoDB posiada specyfikację sterownika do wysyłania i pobierania z niego plików o nazwie GridFS. GridFS pozwala na przechowywanie i pobieranie plików, w tym takich, które przekraczają limit rozmiaru dokumentu BSON wynoszący 16 MB.
GridFS w zasadzie bierze plik i rozbija go na wiele kawałków, które są przechowywane jako pojedyncze dokumenty w dwóch kolekcjach:
- kolekcja
chunk(przechowuje części dokumentu) i - kolekcja
file(przechowuje dodatkowe metadane).
Każdy kawałek ma rozmiar ograniczony do 255 KB. Oznacza to, że ostatni chunk jest zwykle albo równy albo mniejszy niż 255 KB. Brzmi całkiem zgrabnie.
Kiedy czytasz z GridFS, sterownik ponownie składa wszystkie chunki, jak trzeba. Oznacza to, że możesz czytać sekcje pliku zgodnie z zakresem zapytania. Na przykład słuchanie segmentu pliku audio lub pobieranie sekcji pliku wideo.
Uwaga: Preferowane jest używanie GridFS do przechowywania plików normalnie przekraczających limit rozmiaru 16 MB. Dla mniejszych plików, zalecane jest użycie formatu BinData do przechowywania plików w pojedynczych dokumentach.
To podsumowuje jak GridFS działa w ogólności. Czas zanurzyć stopy w jakimś działającym kodzie i zobaczyć, jak zaimplementować system jako taki.
Dość gadania, pokaż mi kod
Do naszej konfiguracji używamy Node.js z dostępem do chmurowej instancji MongoDB. Możesz znaleźć repozytorium kodu dla przykładowej aplikacji tutaj.
 tarique93102GitHub
tarique93102GitHub 
Zupełnie skupimy się na segmentach kodu, które odnoszą się do funkcjonalności GridFS. Dowiemy się jak go skonfigurować i używać do przechowywania plików, pobierania plików lub konkretnego pliku oraz usuwania konkretnego pliku. Zacznijmy zatem.
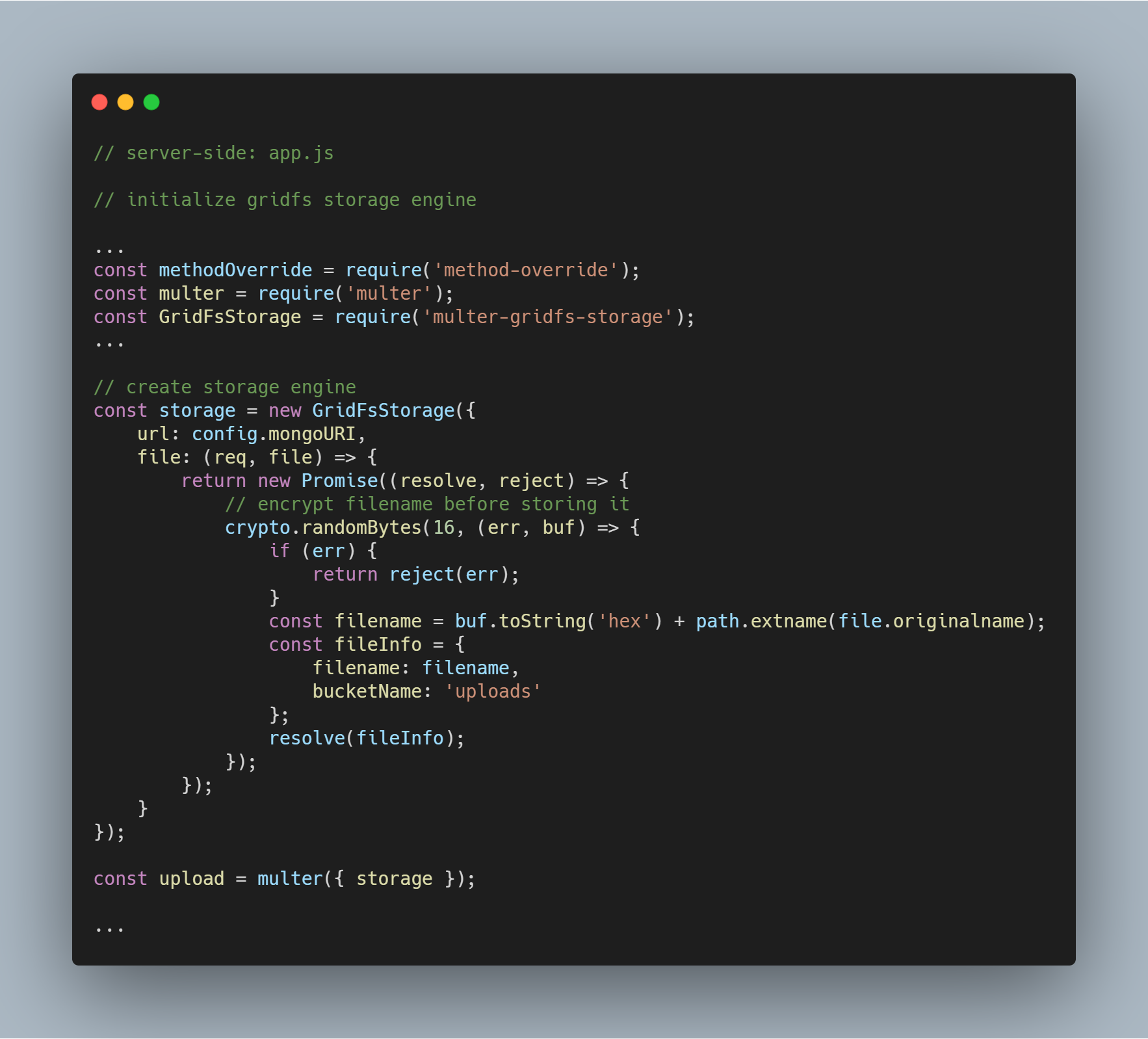
Initialize the Storage Engine
Pakiety potrzebne do zainicjalizowania silnika to multer-gridfs-storage i multer. Używamy również method-override middleware, aby umożliwić operację usuwania plików. Moduł npm crypto jest używany do szyfrowania nazw plików podczas ich przechowywania i odczytywania z bazy danych.
Gdy silnik magazynowania wykorzystujący GridFS jest już zainicjalizowany, musisz go po prostu wywołać za pomocą oprogramowania pośredniczącego multer. Jest on następnie przekazywany do odpowiedniej trasy wykonującej różne operacje przechowywania plików.
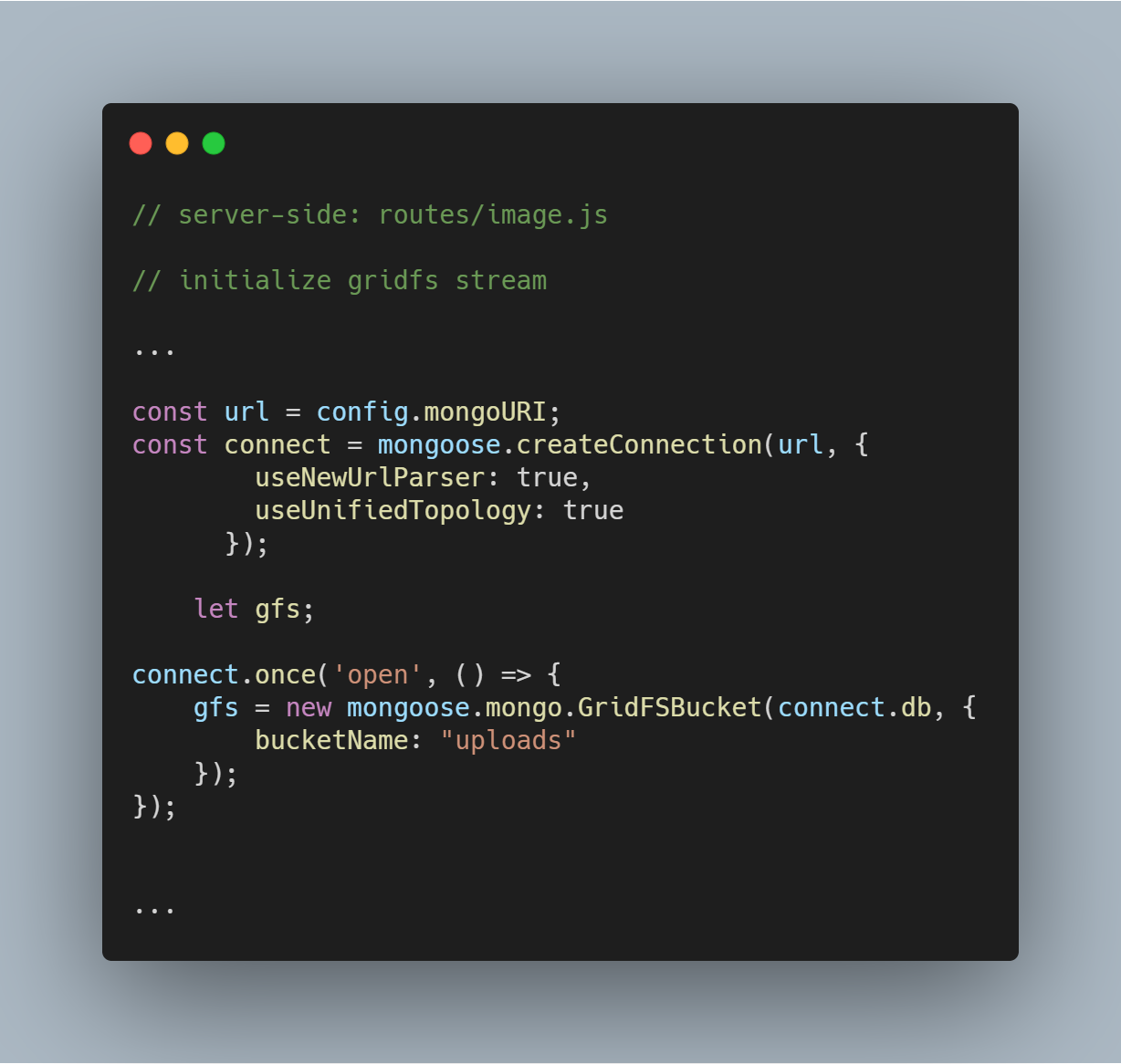
Inicjalizacja strumienia GridFS
Inicjalizujemy strumień GridFS, jak widać w poniższym kodzie. Strumień jest potrzebny do odczytu plików z bazy danych, a także do pomocy w renderowaniu obrazu do przeglądarki, gdy jest to potrzebne.
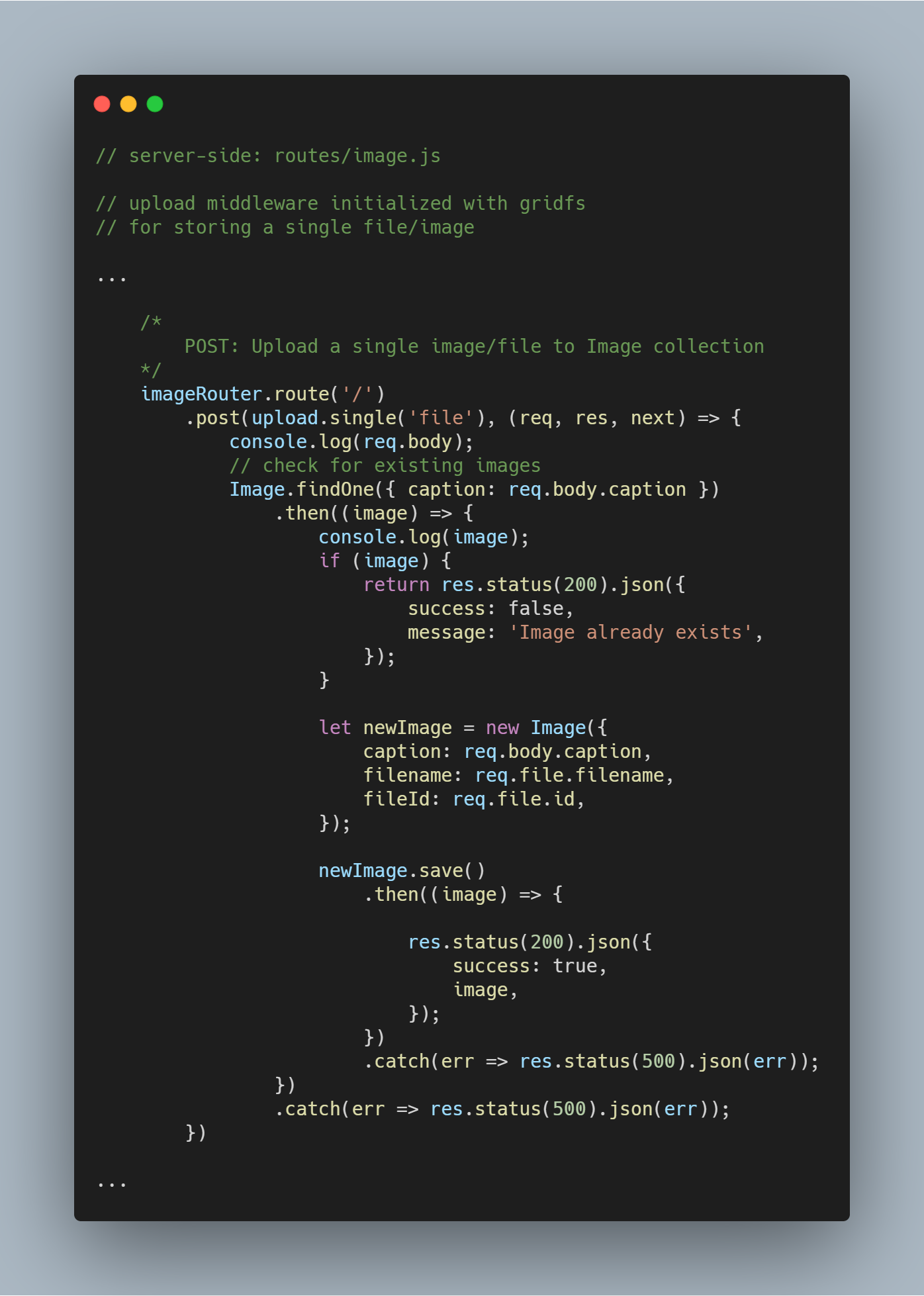
Upload pojedynczego pliku lub obrazu
Wykorzystujemy ponownie middleware uploadu, który stworzyliśmy wcześniej.
Uwaga: Nazwa file jest używana jako parametr w upload.single(), ponieważ mamy klucz o podobnej nazwie przenoszący plik wysyłany z klienta.
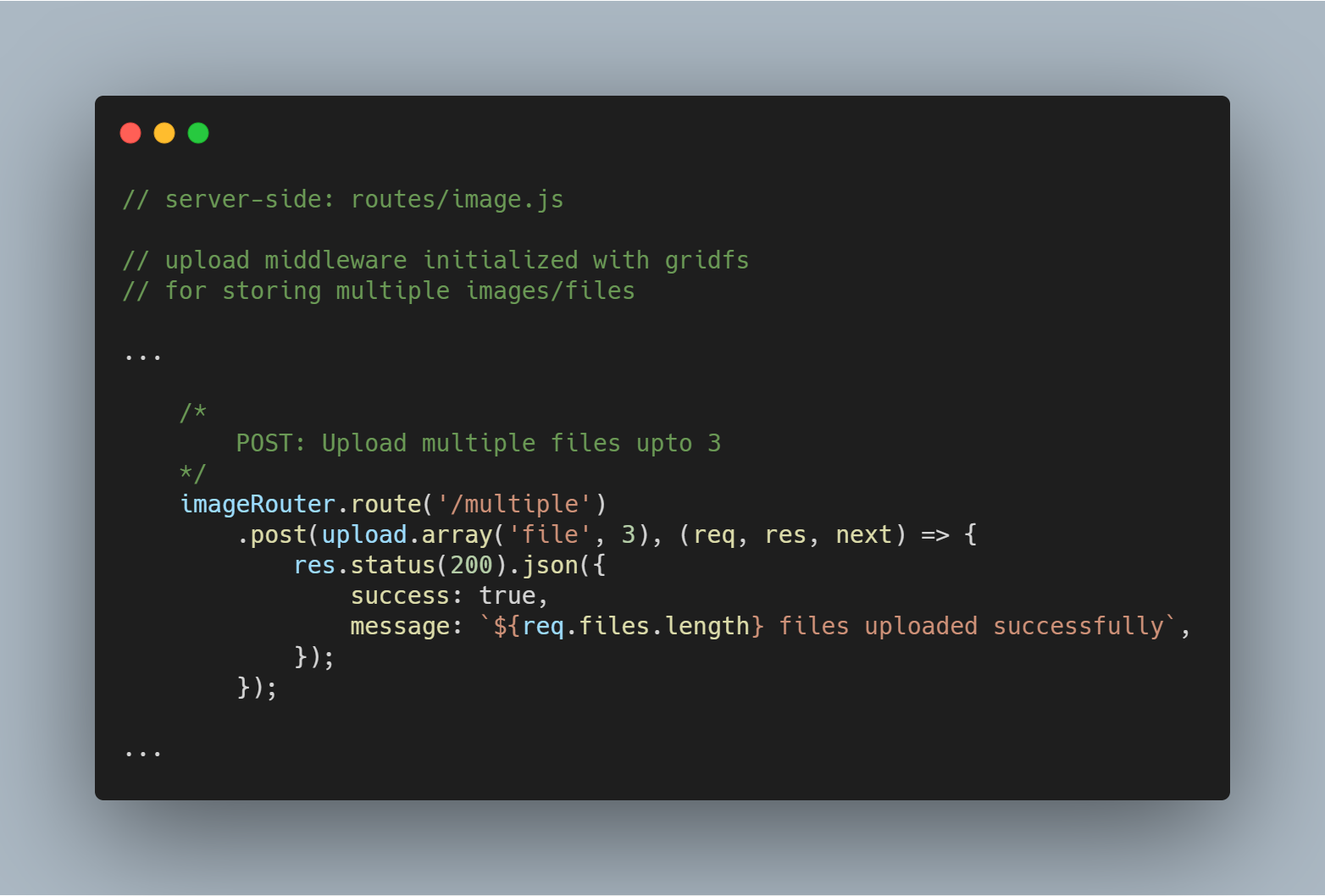
Upload Multiple Files or Images
Możemy również przesłać wiele plików jednocześnie. Zamiast upload.single(), musimy po prostu użyć upload.multiple(<number of files>).
Uwaga: Liczba przesłanych plików może być mniejsza niż zdefiniowana liczba plików.
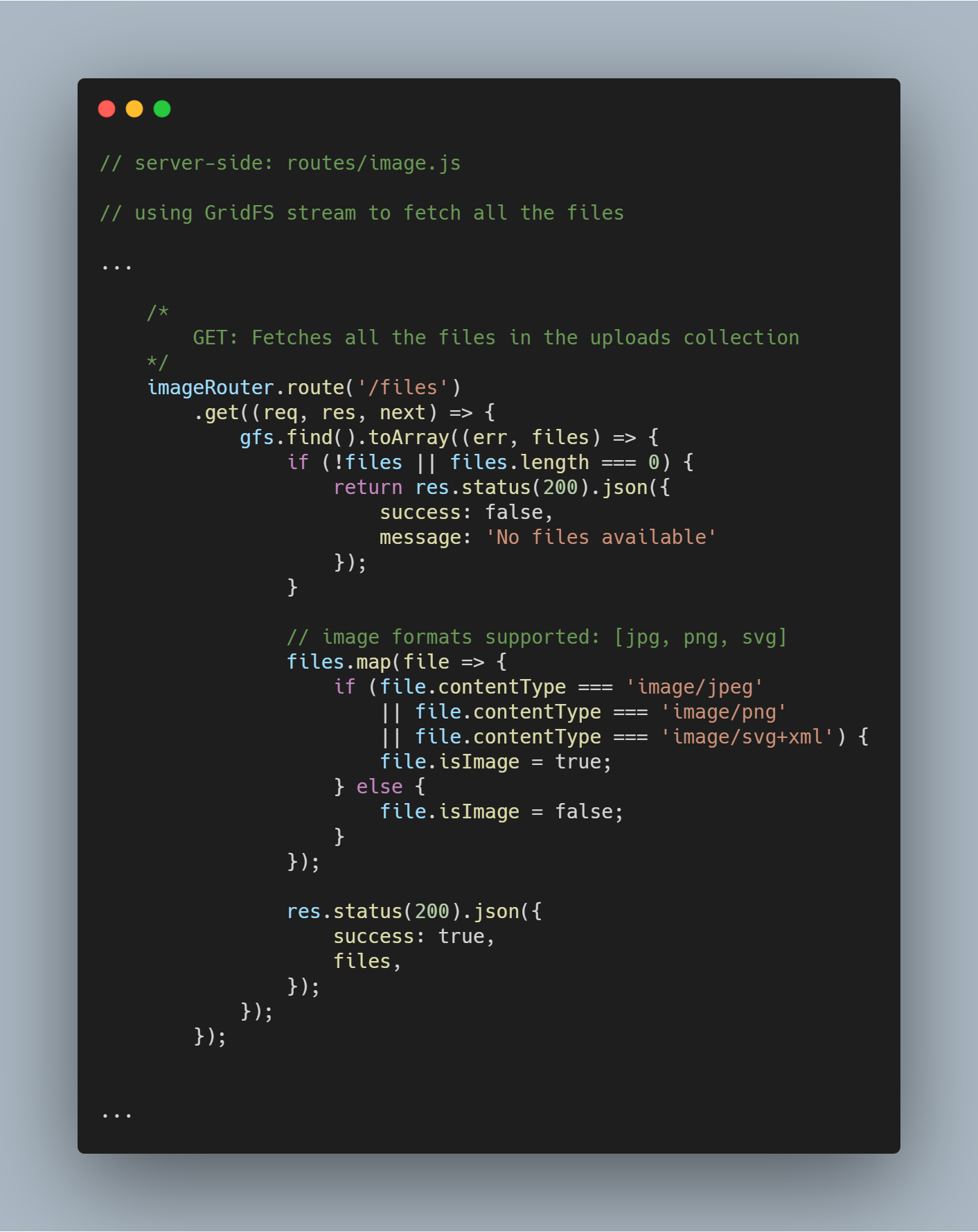
Pobierz wszystkie pliki z bazy danych
Używając zainicjalizowanego strumienia możemy pobrać wszystkie pliki w danej bazie danych używając gfs.find().toArray(...). Po uzyskaniu plików mapujemy je do tablicy i wysyłamy odpowiedź.
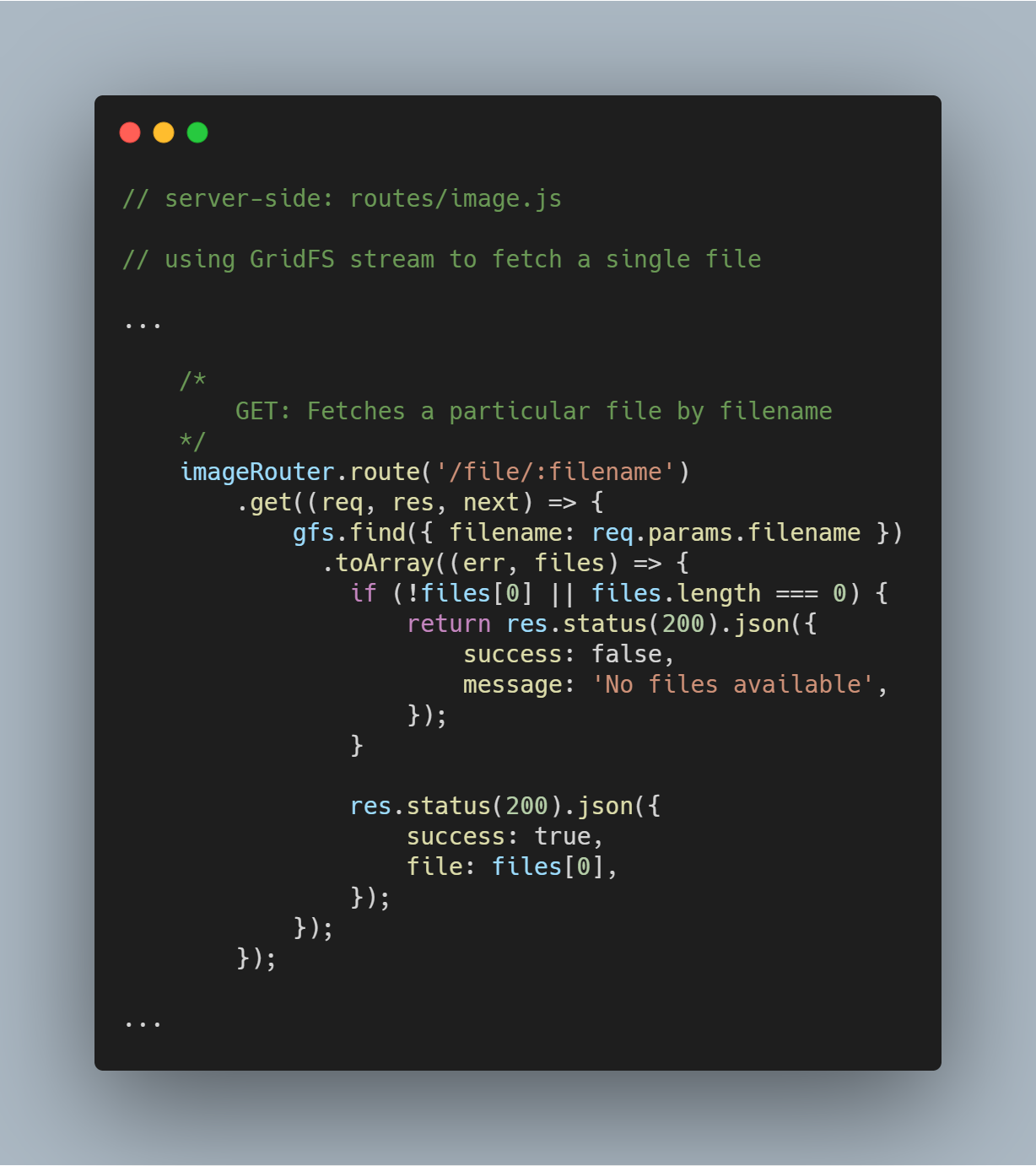
Fetch a Single File By Filename
Bardzo proste jest zapytanie do GridFS o pojedynczy plik na podstawie określonego atrybutu jak filename. Używając strumienia GridFS, możesz zapytać bazę danych poprzez funkcję gfs.find({<add query here>}).
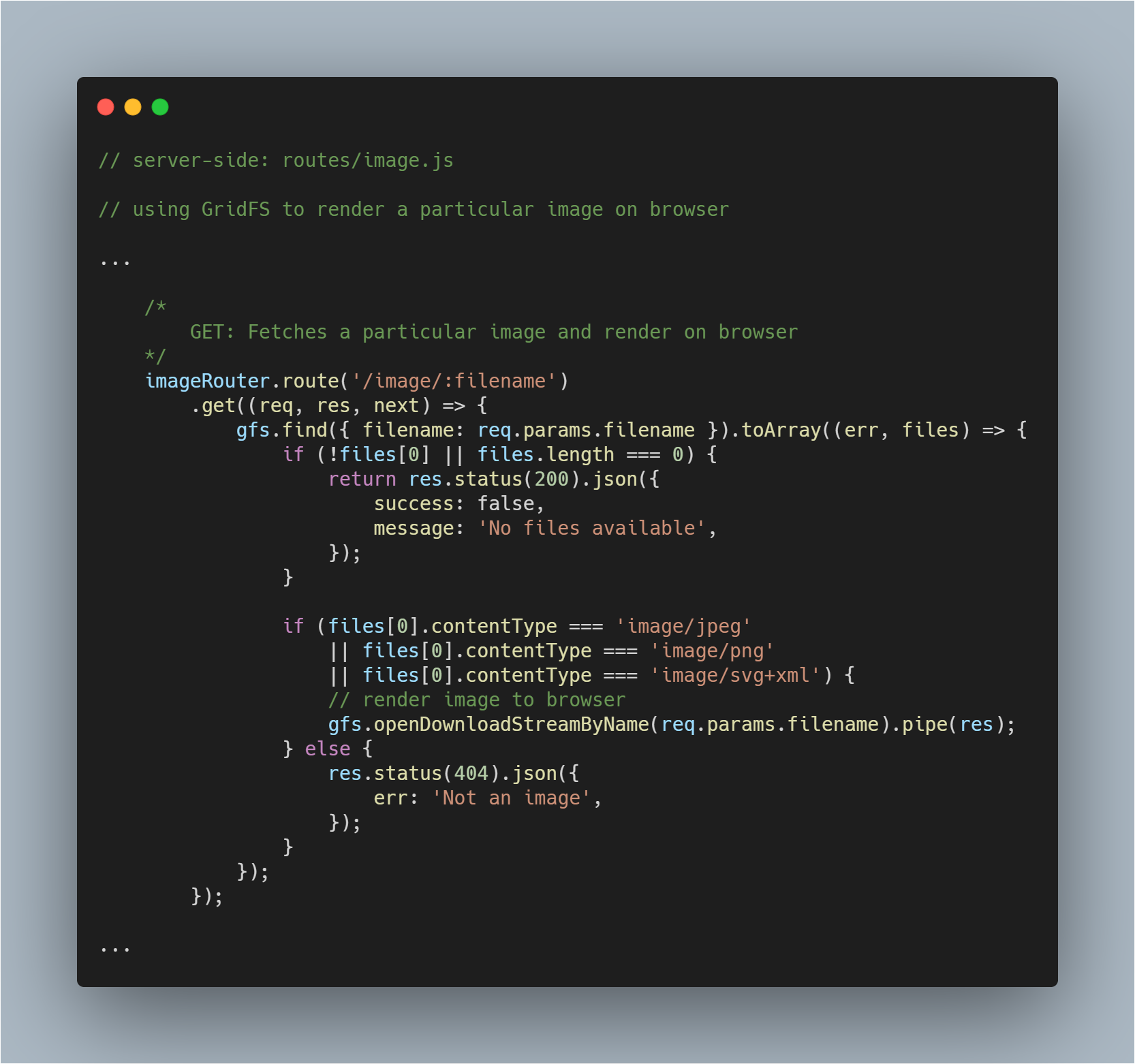
Render a Fetched Image to Browser
To jest nieco bardziej skomplikowana część, ponieważ musisz nie tylko pobrać plik z bazy danych, ale także wyrenderować go jako obraz w odpowiedniej przeglądarce. My pobieramy plik normalnie. Bez zmian w tym procesie.
Następnie z pomocą metody openDownloadStreamByName() na strumieniu gfs, możemy łatwo wyrenderować obraz, ponieważ zwraca ona czytelny strumień. Zrobiwszy to, możemy użyć JavaScriptowego pipe() do strumieniowania odpowiedzi.
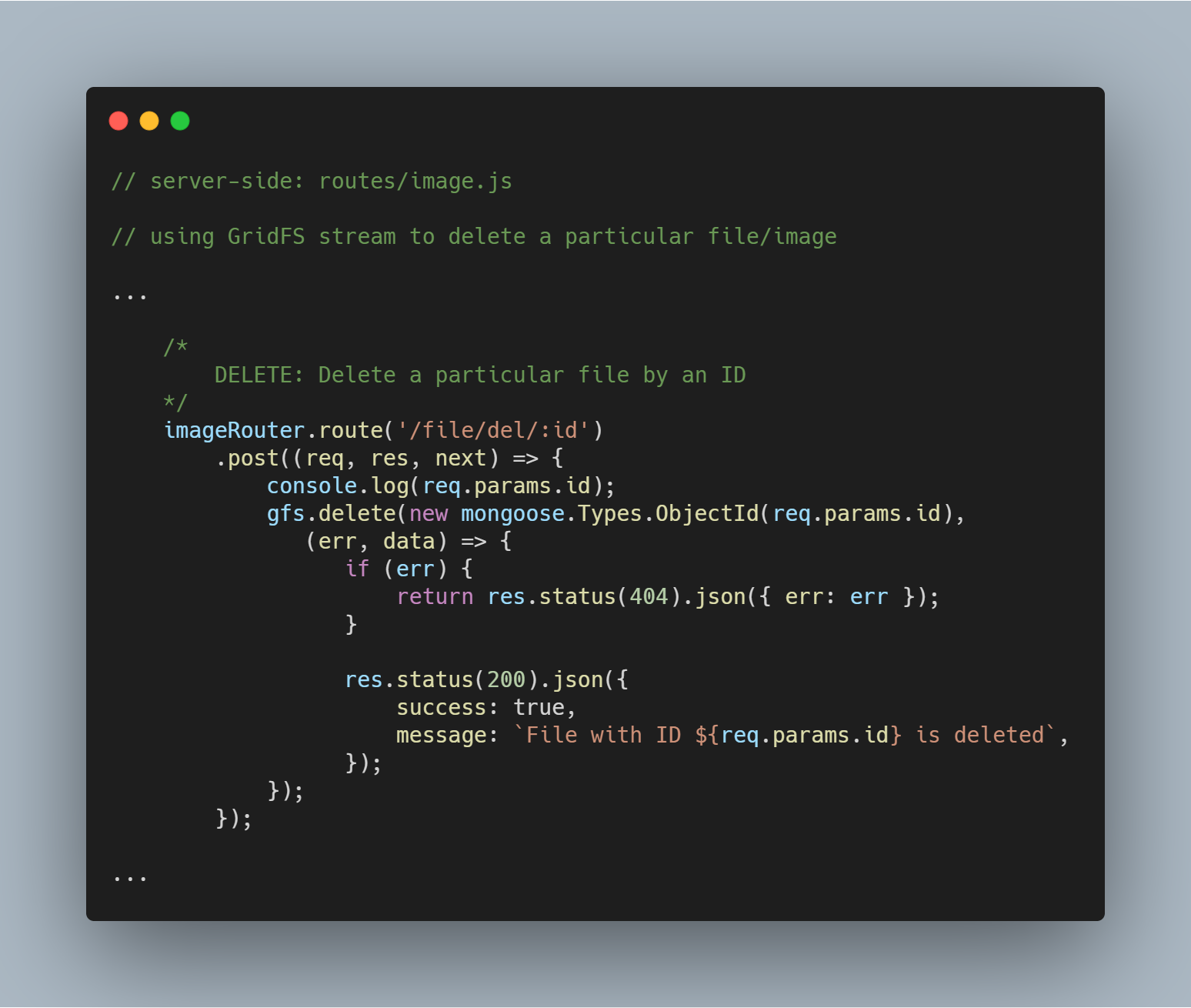
Delete a Particular File by Id
Usuwanie pliku jest równie proste. Używamy metody strumienia delete() z parametrem _id do zapytania i usunięcia danego pliku.
To są główne funkcjonalności oferowane przez projekt silnika pamięci masowej. Wykorzystałem omówione funkcje GridFS do stworzenia prostej aplikacji do przesyłania obrazów. Możesz zagłębić się w kod w repozytorium.
Wnioski
Zajęło mi trochę czasu i sporo walki, aby zrozumieć jak wykorzystać GridFS w osobistym projekcie. Z tego powodu chciałem się upewnić, że przynajmniej jedna osoba nie będzie musiała inwestować tyle samo czasu.
Powiedziawszy to, zalecam używanie GridFS z ostrożnością. Nie jest to srebrna kula na wszystkie problemy związane z przechowywaniem plików. Mimo to, jest to fajna specyfikacja, o której warto wiedzieć i być świadomym.