By Derrick Mwiti, Data Analyst

Editor’s note: Ten poradnik ilustruje, jak zacząć prognozować szeregi czasowe za pomocą modeli LSTM. Dane giełdowe są świetnym wyborem do tego celu, ponieważ są dość regularne i szeroko dostępne dla każdego. Proszę nie traktować tego jako porady finansowej ani nie używać do zawierania własnych transakcji.
W tym tutorialu zbudujemy w Pythonie model głębokiego uczenia, który będzie przewidywał przyszłe zachowanie cen akcji. Zakładamy, że czytelnik jest zaznajomiony z koncepcjami głębokiego uczenia w Pythonie, w szczególności z Long Short-Term Memory.
Choć przewidywanie rzeczywistej ceny akcji jest trudne, możemy zbudować model, który będzie przewidywał, czy cena wzrośnie, czy spadnie. Dane i notatnik wykorzystane w tym tutorialu można znaleźć tutaj. Ważne jest, aby pamiętać, że zawsze istnieją inne czynniki, które wpływają na ceny akcji, takie jak atmosfera polityczna i rynek. Nie będziemy się jednak skupiać na tych czynnikach w tym tutorialu.
Wprowadzenie
LSTMy są bardzo potężne w problemach przewidywania sekwencji, ponieważ są w stanie przechowywać informacje z przeszłości. Jest to ważne w naszym przypadku, ponieważ poprzednia cena akcji jest kluczowa w przewidywaniu jej przyszłej ceny.
Zaczniemy od zaimportowania NumPy do obliczeń naukowych, Matplotlib do tworzenia wykresów i Pandas do pomocy w ładowaniu i manipulowaniu naszymi zbiorami danych.
Wczytywanie zbioru danych
Następnym krokiem jest wczytanie naszego szkoleniowego zbioru danych i wybranie kolumn Open i High, których będziemy używać w naszym modelowaniu.
Sprawdzamy nagłówek naszego zbioru danych, aby dać nam wgląd w rodzaj zbioru danych, z którym pracujemy.
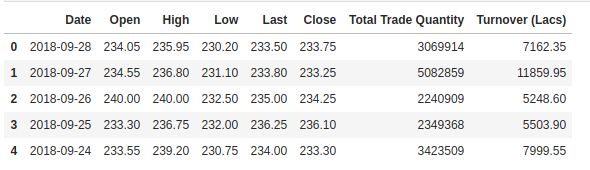
Kolumna Open jest ceną początkową, podczas gdy kolumna Close jest ceną końcową akcji w danym dniu handlowym. Kolumny High i Low reprezentują najwyższą i najniższą cenę w danym dniu.
Skalowanie funkcji
Z poprzednich doświadczeń z modelami głębokiego uczenia wiemy, że musimy skalować nasze dane, aby uzyskać optymalną wydajność. W naszym przypadku, użyjemy Scikit- Learn’s MinMaxScaler i przeskalujemy nasz zbiór danych do liczb pomiędzy zero a jeden.
Tworzenie danych z krokami czasowymi
LSTM oczekują, że nasze dane będą w określonym formacie, zazwyczaj tablicy 3D. Zaczniemy od utworzenia danych w 60 krokach czasowych i przekonwertowania ich na tablicę przy użyciu NumPy. Następnie konwertujemy dane do tablicy o wymiarze 3D z X_train próbkami, 60 znacznikami czasu i jedną cechą na każdym kroku.
Budujemy LSTM
Aby zbudować LSTM, musimy zaimportować kilka modułów z Keras:
-
Sequentialdo inicjalizacji sieci neuronowej -
Densedo dodawania warstwy gęsto połączonej sieci neuronowej -
LSTMdo dodawania warstwy pamięci długookresowej -
Dropoutdo dodawania warstw dropout, które zapobiegają przepasowaniu
Dodajemy warstwę LSTM, a później dodajemy kilka warstw Dropout, aby zapobiec przepasowaniu. Warstwę LSTM dodajemy z następującymi argumentami:
- 50 jednostek, czyli wymiarowość przestrzeni wyjściowej
-
return_sequences=True, która określa, czy zwracać ostatnie wyjście w sekwencji wyjściowej, czy pełną sekwencję -
input_shapejako kształt naszego zbioru treningowego.
Przy definiowaniu warstw Dropout podajemy wartość 0.2, co oznacza, że 20% warstw zostanie opuszczonych. Następnie dodajemy warstwę Dense, która określa wyjście 1 jednostki. Następnie kompilujemy nasz model za pomocą popularnego optymalizatora adam i ustawiamy stratę jako mean_squarred_error. Pozwoli to obliczyć średnią kwadratów błędów. Następnie dopasowujemy model tak, aby działał na 100 epokach z rozmiarem partii 32. Należy pamiętać, że w zależności od specyfikacji komputera, może to potrwać kilka minut, aby zakończyć działanie.
Predicting Future Stock using the Test Set
Najpierw musimy zaimportować zestaw testowy, którego będziemy używać do tworzenia naszych przewidywań.
Aby przewidzieć przyszłe ceny akcji, musimy zrobić kilka rzeczy po załadowaniu zbioru testowego:
- Połącz zbiór treningowy i testowy na osi 0.
- Ustaw krok czasowy na 60 (tak jak poprzednio)
- Użyj
MinMaxScalerdo przekształcenia nowego zbioru danych - Przekształć zbiór danych tak jak poprzednio
Po wykonaniu predykcji użyjemy inverse_transform, aby uzyskać z powrotem ceny akcji w normalnym czytelnym formacie.
Plotting the Results
Wreszcie, używamy Matplotlib do wizualizacji wyniku przewidywanej ceny akcji i rzeczywistej ceny akcji.
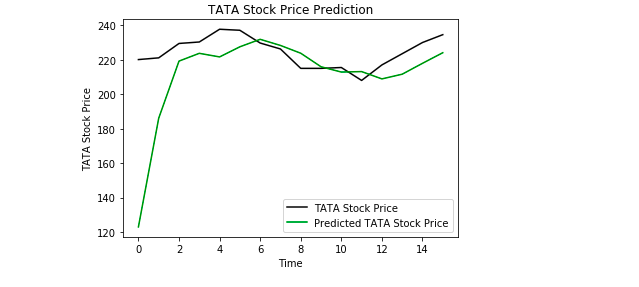
Z wykresu możemy zobaczyć, że rzeczywista cena akcji poszła w górę, podczas gdy nasz model również przewidział, że cena akcji pójdzie w górę. To wyraźnie pokazuje, jak potężne są LSTM do analizy szeregów czasowych i danych sekwencyjnych.
Wnioski
Istnieje kilka innych technik przewidywania cen akcji, takich jak średnie ruchome, regresja liniowa, K-Nearest Neighbours, ARIMA i Prorok. Są to techniki, które można przetestować na własną rękę i porównać ich wydajność z Keras LSTM. Jeśli chcesz dowiedzieć się więcej o Keras i głębokim uczeniu, możesz znaleźć moje artykuły na ten temat tutaj i tutaj.
Dyskutuj o tym poście na Reddit i Hacker News.
Bio: Derrick Mwiti jest analitykiem danych, pisarzem i mentorem. Jest napędzany przez dostarczanie świetnych wyników w każdym zadaniu i jest mentorem w Lapid Leaders Africa.
Original. Reposted with permission.
Related:
- Introduction to Deep Learning with Keras
- Introduction to PyTorch for Deep Learning
- The Keras 4 Step Workflow
.