Af Derrick Mwiti, dataanalytiker

Redaktørens note: Denne vejledning illustrerer, hvordan du kommer i gang med at forudsige tidsserier med LSTM-modeller. Aktiemarkedsdata er et godt valg til dette, fordi de er ret regelmæssige og bredt tilgængelige for alle. Du må ikke tage dette som finansiel rådgivning eller bruge det til at foretage dine egne handler.
I denne tutorial vil vi opbygge en Python deep learning-model, der vil forudsige den fremtidige adfærd for aktiekurser. Vi antager, at læseren er bekendt med begreberne for deep learning i Python, især Long Short-Term Memory.
Mens forudsigelse af den faktiske pris på en aktie er en op ad bakke, kan vi bygge en model, der vil forudsige, om prisen vil gå op eller ned. De data og den notesbog, der er brugt til denne vejledning, kan findes her. Det er vigtigt at bemærke, at der altid er andre faktorer, der påvirker aktiernes priser, f.eks. den politiske stemning og markedet. Vi vil dog ikke fokusere på disse faktorer i denne tutorial.
Indledning
LSTM’er er meget kraftfulde i sekvensforudsigelsesproblemer, fordi de er i stand til at lagre tidligere oplysninger. Dette er vigtigt i vores tilfælde, fordi den tidligere pris på en aktie er afgørende for forudsigelsen af dens fremtidige pris.
Vi starter med at importere NumPy til videnskabelig beregning, Matplotlib til plotning af grafer og Pandas til at hjælpe med at indlæse og manipulere vores datasæt.
Indlæsning af datasættet
Det næste skridt er at indlæse vores træningsdatasæt og vælge de Open og Highkolonner, som vi vil bruge i vores modellering.
Vi kontrollerer hovedet af vores datasæt for at give os et indblik i den slags datasæt, vi arbejder med.
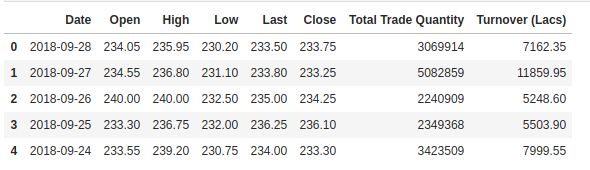
Kolonnen Open er startprisen, mens kolonnen Close er den endelige pris på en aktie på en bestemt handelsdag. Kolonnerne High og Low repræsenterer den højeste og laveste pris for en bestemt dag.
Skalering af egenskaber
Fra tidligere erfaringer med deep learning-modeller ved vi, at vi er nødt til at skalere vores data for at opnå optimal ydeevne. I vores tilfælde vil vi bruge Scikit- Learns MinMaxScaler og skalere vores datasæt til tal mellem nul og et.
Skabelse af data med tidsskridt
LSTM’er forventer, at vores data er i et bestemt format, normalt et 3D-array. Vi starter med at oprette data i 60 timesteps og konverterer dem til et array ved hjælp af NumPy. Dernæst konverterer vi dataene til et array med 3D-dimensionen med X_train prøver, 60 tidsstempler og en funktion på hvert trin.
Opbygning af LSTM
For at kunne opbygge LSTM’en skal vi importere et par moduler fra Keras:
-
Sequentialtil initialisering af det neurale netværk -
Densetil tilføjelse af et tæt forbundet neuralt netværkslag -
LSTMtil tilføjelse af laget Long Short-Term Memory -
Dropouttil tilføjelse af dropout-lag, der forhindrer overfitting
Vi tilføjer LSTM-laget og tilføjer senere et par Dropout lag for at forhindre overfitting. Vi tilføjer LSTM-laget med følgende argumenter:
- 50 enheder, som er dimensionaliteten af outputrummet
-
return_sequences=True, som bestemmer, om vi skal returnere det sidste output i outputsekvensen eller den fulde sekvens -
input_shapesom formen på vores træningssæt.
Når vi definerer Dropout-lagene, angiver vi 0,2, hvilket betyder, at 20 % af lagene vil blive droppet. Derefter tilføjer vi Dense-laget, som angiver output på 1 enhed. Herefter kompilerer vi vores model ved hjælp af den populære adam optimizer og indstiller tabet som mean_squarred_error. Dette vil beregne gennemsnittet af de kvadrerede fejl. Dernæst tilpasser vi modellen til at køre på 100 epochs med en batchstørrelse på 32. Husk, at afhængigt af specifikationerne på din computer kan det tage et par minutter at køre færdig.
Forudsigelse af fremtidige aktier ved hjælp af testsæt
Først skal vi importere det testsæt, som vi skal bruge til at lave vores forudsigelser på.
For at forudsige fremtidige aktiekurser skal vi gøre et par ting efter indlæsning af testsættet:
- Sammenlægning af træningssættet og testsættet på 0-aksen.
- Sæt tidstrinnet som 60 (som set tidligere)
- Brug
MinMaxScalertil at transformere det nye datasæt - Opnå omformning af datasættet som gjort tidligere
Når vi har lavet forudsigelserne, bruger vi inverse_transform til at få aktiekurserne tilbage i et normalt læsbart format.
Plotte resultaterne
Endeligt bruger vi Matplotlib til at visualisere resultatet af den forudsagte aktiekurs og den reelle aktiekurs.
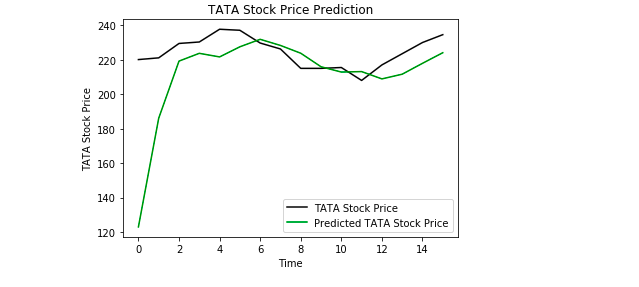
Fra plottet kan vi se, at den reelle aktiekurs gik op, mens vores model også forudsagde, at aktiekursen vil gå op. Dette viser tydeligt, hvor stærke LSTM’er er til analyse af tidsserier og sekventielle data.
Slutning
Der findes et par andre teknikker til forudsigelse af aktiekurser såsom glidende gennemsnit, lineær regression, K-Nearest Neighbours, ARIMA og Prophet. Disse er teknikker, som man kan teste på egen hånd og sammenligne deres ydeevne med Keras LSTM. Hvis du ønsker at lære mere om Keras og deep learning, kan du finde mine artikler om det her og her.
Diskuter dette indlæg på Reddit og Hacker News.
Bio: Derrick Mwiti er en dataanalytiker, en forfatter og en mentor. Han er drevet af at levere gode resultater i hver eneste opgave og er mentor hos Lapid Leaders Africa.
Original. Reposted with permission.
Relateret:
- Introduktion til Deep Learning med Keras
- Introduktion til PyTorch til Deep Learning
- The Keras 4 Step Workflow