Di Derrick Mwiti, Data Analyst

Nota dell’editore: Questo tutorial illustra come iniziare a prevedere serie temporali con modelli LSTM. I dati del mercato azionario sono un’ottima scelta per questo perché sono abbastanza regolari e ampiamente disponibili per tutti. Per favore, non prendetelo come un consiglio finanziario e non usatelo per fare qualche operazione per conto vostro.
In questo tutorial, costruiremo un modello di deep learning in Python che predice il comportamento futuro dei prezzi delle azioni. Assumiamo che il lettore abbia familiarità con i concetti di deep learning in Python, in particolare con la memoria a breve termine (Long Short-Term Memory).
Mentre prevedere il prezzo attuale di un’azione è una strada in salita, possiamo costruire un modello che preveda se il prezzo salirà o scenderà. I dati e il notebook utilizzati per questo tutorial possono essere trovati qui. È importante notare che ci sono sempre altri fattori che influenzano i prezzi delle azioni, come l’atmosfera politica e il mercato. Tuttavia, non ci concentreremo su questi fattori per questo tutorial.
Introduzione
Le LSTM sono molto potenti nei problemi di previsione delle sequenze perché sono in grado di memorizzare informazioni passate. Questo è importante nel nostro caso perché il prezzo precedente di un’azione è cruciale per prevedere il suo prezzo futuro.
Importiamo NumPy per il calcolo scientifico, Matplotlib per tracciare i grafici e Pandas per aiutare a caricare e manipolare i nostri set di dati.
Carico del dataset
Il prossimo passo è quello di caricare il nostro dataset di allenamento e selezionare le Open e Highcolonne che useremo nella nostra modellazione.
Controlliamo la testa del nostro dataset per darci un’idea del tipo di dataset con cui stiamo lavorando.
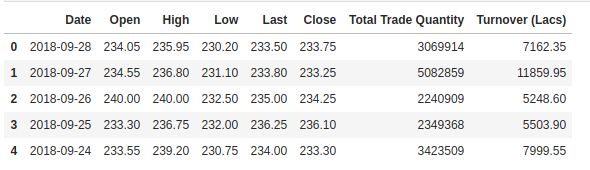
La colonna Open è il prezzo di partenza mentre la colonna Close è il prezzo finale di un’azione in un particolare giorno di trading. Le colonne High e Low rappresentano i prezzi più alti e più bassi per un certo giorno.
Feature Scaling
Da precedenti esperienze con modelli di deep learning, sappiamo che dobbiamo scalare i nostri dati per ottenere prestazioni ottimali. Nel nostro caso, useremo il MinMaxScaler di Scikit- Learn e scaleremo il nostro set di dati a numeri compresi tra zero e uno.
Creazione di dati con Timesteps
I LSTM si aspettano che i nostri dati siano in un formato specifico, solitamente un array 3D. Iniziamo creando dati in 60 timesteps e convertendoli in un array usando NumPy. Successivamente, convertiamo i dati in un array di dimensioni 3D con X_traincampioni, 60 timestamp, e una caratteristica ad ogni passo.
Costruire il LSTM
Per costruire il LSTM, dobbiamo importare un paio di moduli da Keras:
-
Sequentialper inizializzare la rete neurale -
Denseper aggiungere uno strato di rete neurale densamente connesso -
LSTMper aggiungere lo strato di Long Short-Term Memory -
Dropoutper aggiungere strati di dropout che prevengono l’overfitting
Aggiungiamo lo strato LSTM e successivamente aggiungiamo alcuni strati Dropout per prevenire l’overfitting. Aggiungiamo lo strato LSTM con i seguenti argomenti:
- 50 unità che è la dimensionalità dello spazio di output
-
return_sequences=Trueche determina se restituire l’ultimo output nella sequenza di output, o la sequenza completa -
input_shapecome forma del nostro set di allenamento.
Quando definiamo gli strati Dropout, specifichiamo 0,2, che significa che il 20% degli strati sarà abbandonato. In seguito, aggiungiamo lo strato Dense che specifica l’uscita di 1 unità. Dopo questo, compiliamo il nostro modello usando il popolare ottimizzatore adam e impostiamo la perdita come mean_squarred_error. Questo calcolerà la media degli errori al quadrato. Successivamente, adattiamo il modello per l’esecuzione su 100 epoche con una dimensione del batch di 32. Tenete a mente che, a seconda delle specifiche del vostro computer, questo potrebbe richiedere alcuni minuti per finire l’esecuzione.
Predicendo azioni future usando il set di prova
Prima di tutto abbiamo bisogno di importare il set di prova che useremo per fare le nostre previsioni.
Per prevedere i prezzi futuri delle azioni dobbiamo fare un paio di cose dopo aver caricato il test set:
- Mongiungere il training set e il test set sull’asse 0.
- Impostare il passo temporale a 60 (come visto in precedenza)
- Utilizzare
MinMaxScalerper trasformare il nuovo set di dati - Riflettere il set di dati come fatto in precedenza
Dopo aver fatto le previsioni usiamo inverse_transform per avere indietro i prezzi delle azioni in formato leggibile.
Plottare i risultati
Infine, usiamo Matplotlib per visualizzare il risultato del prezzo previsto delle azioni e il prezzo reale delle azioni.
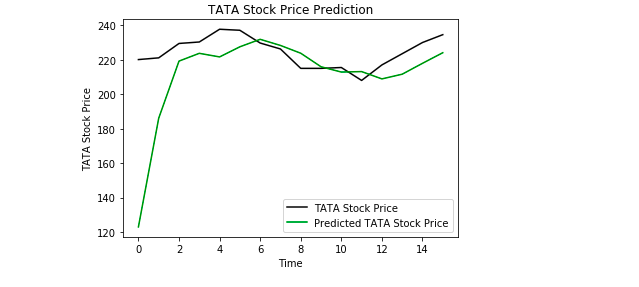
Dal grafico possiamo vedere che il prezzo reale delle azioni è salito mentre il nostro modello ha anche previsto che il prezzo delle azioni salirà. Questo mostra chiaramente quanto siano potenti gli LSTM per analizzare serie temporali e dati sequenziali.
Conclusione
Ci sono un paio di altre tecniche per prevedere i prezzi delle azioni come le medie mobili, la regressione lineare, K-Nearest Neighbours, ARIMA e Prophet. Queste sono tecniche che si possono testare da soli e confrontare le loro prestazioni con Keras LSTM. Se volete saperne di più su Keras e l’apprendimento profondo potete trovare i miei articoli su questo argomento qui e qui.
Discutete questo post su Reddit e Hacker News.
Bio: Derrick Mwiti è un analista di dati, uno scrittore e un mentore. È spinto a fornire grandi risultati in ogni compito, ed è un mentore di Lapid Leaders Africa.
Originale. Reposted with permission.
Related:
- Introduzione all’apprendimento profondo con Keras
- Introduzione a PyTorch per l’apprendimento profondo
- Il flusso di lavoro in 4 fasi di Keras