L’archiviazione dei file è una caratteristica importante richiesta in più processi attraverso vari tipi di applicazioni. L’esistenza di processi come Content Delivery Networks (CDNs), impostati attraverso opzioni cloud di terze parti come Amazon Web Services, e le opzioni di archiviazione locale dei file hanno sempre reso più facile costruire una tale caratteristica.
Tuttavia, il concetto di memorizzare i file direttamente in un database attraverso una singola chiamata API mi ha intrigato per un bel po’ di tempo. È qui che GridFS è entrato in scena per me.

GridFS – A Layman’s Understanding
MongoDB ha una specifica di driver per caricare e recuperare file da esso chiamato GridFS. GridFS permette di memorizzare e recuperare file, compresi quelli che superano il limite di dimensione del documento BSON di 16 MB.
GridFS fondamentalmente prende un file e lo suddivide in più pezzi che sono memorizzati come documenti individuali in due collezioni:
- la collezione
chunk(memorizza le parti del documento), e - la collezione
file(memorizza i conseguenti metadati aggiuntivi).
Ogni pezzo è limitato a 255 KB di dimensione. Questo significa che l’ultimo chunk è normalmente uguale o inferiore a 255 KB. Sembra piuttosto ordinato.
Quando leggi da GridFS, il driver riassembla tutti i chunk come necessario. Questo significa che potete leggere sezioni di un file secondo il vostro intervallo di query. Ad esempio ascoltando un segmento di un file audio o recuperando una sezione di un file video.
Nota: è preferibile usare GridFS per memorizzare file che normalmente superano il limite di dimensione di 16 MB. Per file più piccoli, si raccomanda di usare il formato BinData per memorizzare i file in singoli documenti.
Questo riassume come funziona GridFS in generale. È ora di immergere i piedi in un po’ di codice funzionante e vedere come implementare un sistema del genere.
Basta parlare, mostrami il codice
Stiamo usando Node.js con accesso a un’istanza cloud di MongoDB per la nostra configurazione. Puoi trovare il repository del codice per l’applicazione di esempio qui.
 tarique93102GitHub
tarique93102GitHub 
Ci concentreremo completamente sui segmenti di codice che riguardano le funzionalità di GridFS. Impareremo come impostarlo e usarlo per memorizzare file, recuperare file o un particolare file, e cancellare un particolare file. Cominciamo allora.
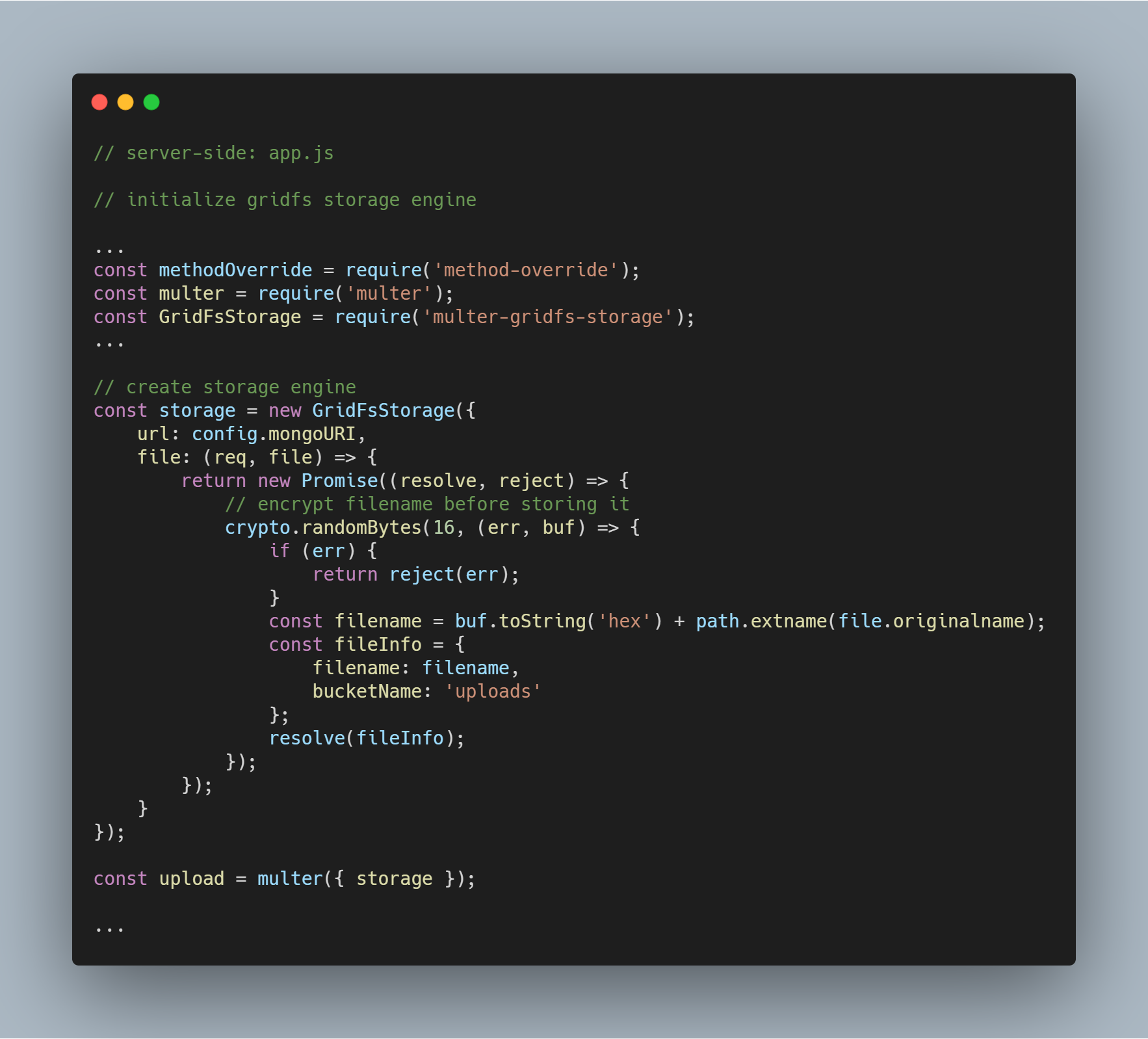
Inizializzare il motore di archiviazione
I pacchetti necessari per inizializzare il motore sono multer-gridfs-storage e multer. Usiamo anche il middleware method-override per abilitare l’operazione di cancellazione dei file. Il modulo npm crypto viene utilizzato per crittografare i nomi dei file quando vengono memorizzati e letti dal database.
Una volta inizializzato il motore di memorizzazione che utilizza GridFS, è sufficiente chiamarlo utilizzando il middleware multer. Viene poi passato al rispettivo percorso che esegue le varie operazioni di memorizzazione dei file.
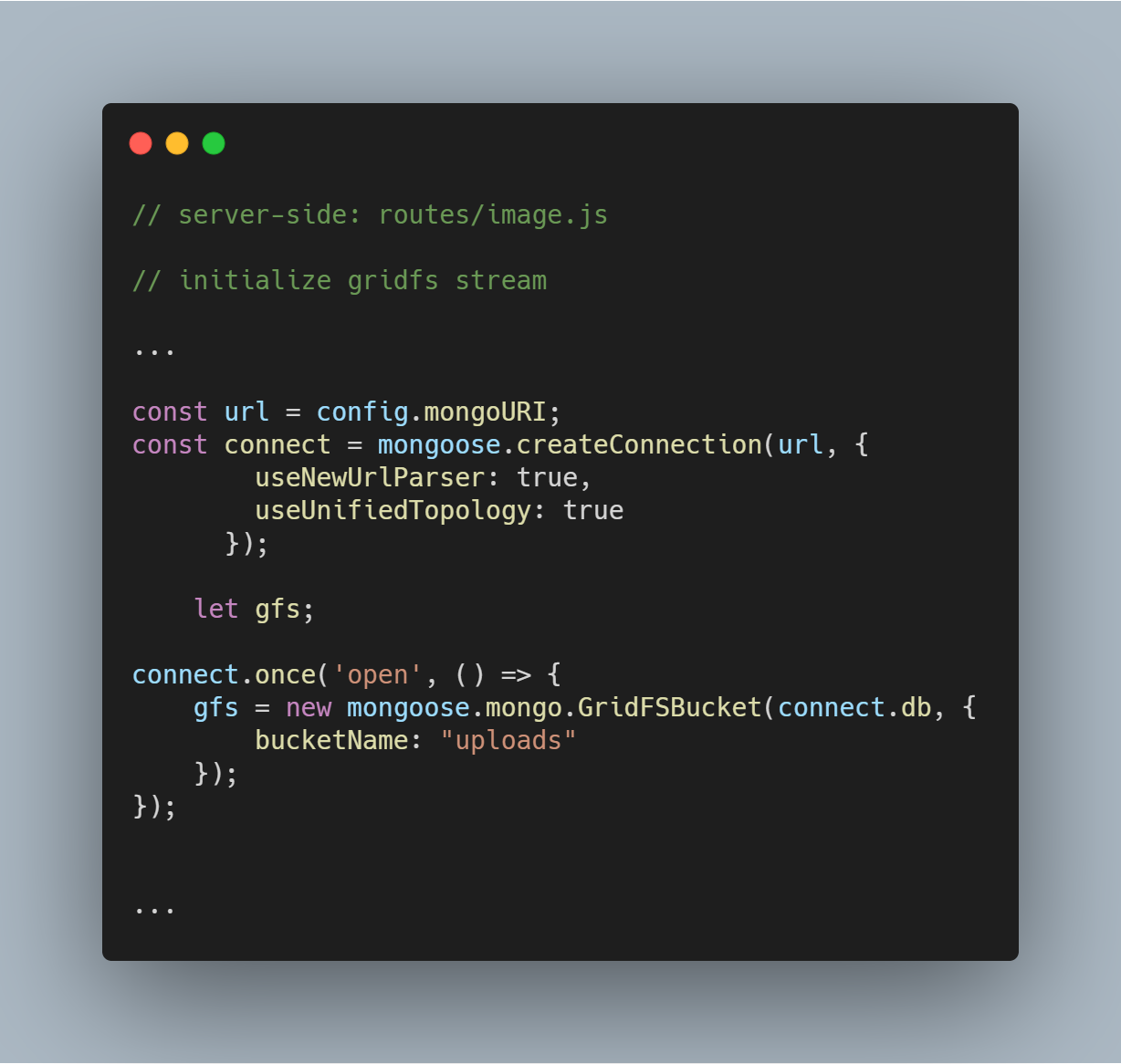
Inizializzare GridFS Stream
Inizializziamo uno stream GridFS come visto nel codice qui sotto. Il flusso è necessario per leggere i file dal database e anche per aiutare a rendere un’immagine al browser quando necessario.
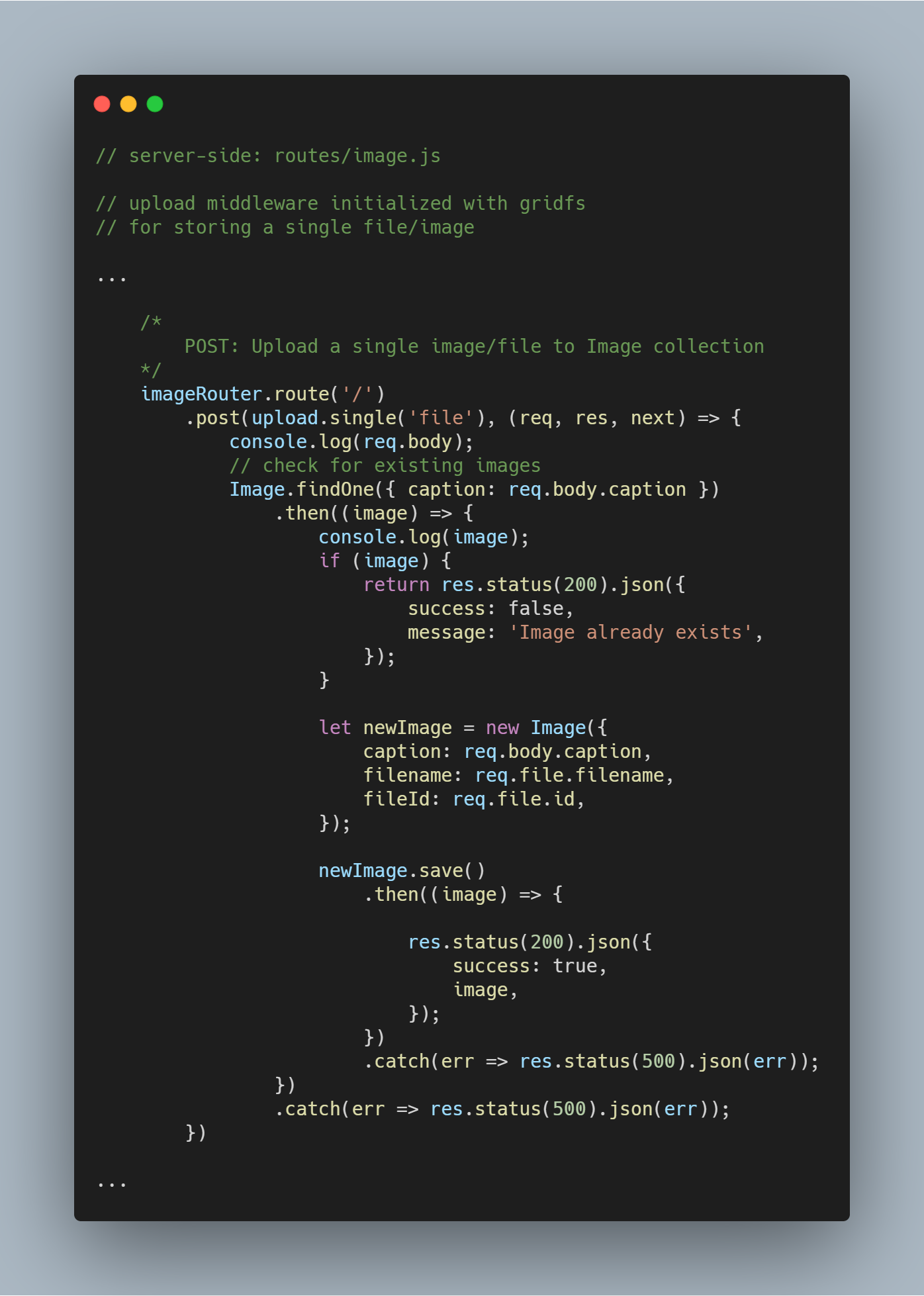
Carica un singolo file o immagine
Riutilizziamo il middleware di upload che avevamo creato in precedenza.
Nota: Il nome file è usato come parametro in upload.single() poiché abbiamo la chiave con un nome simile che trasporta il file inviato dal client.
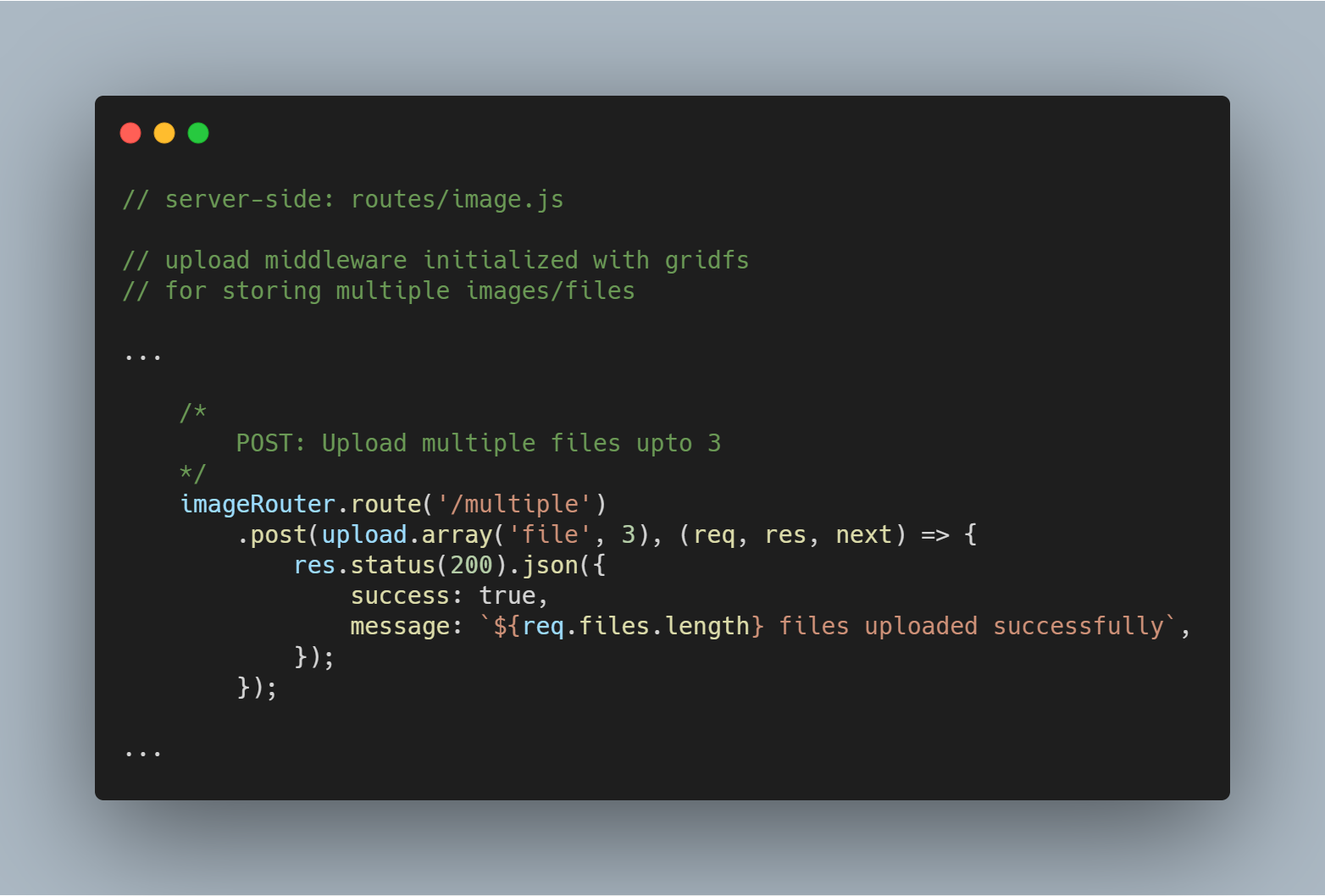
Scaricare più file o immagini
Possiamo anche caricare più file contemporaneamente. Invece di upload.single(), dobbiamo semplicemente usare upload.multiple(<number of files>).
Nota: Il numero di file caricati può essere inferiore al numero definito di file.
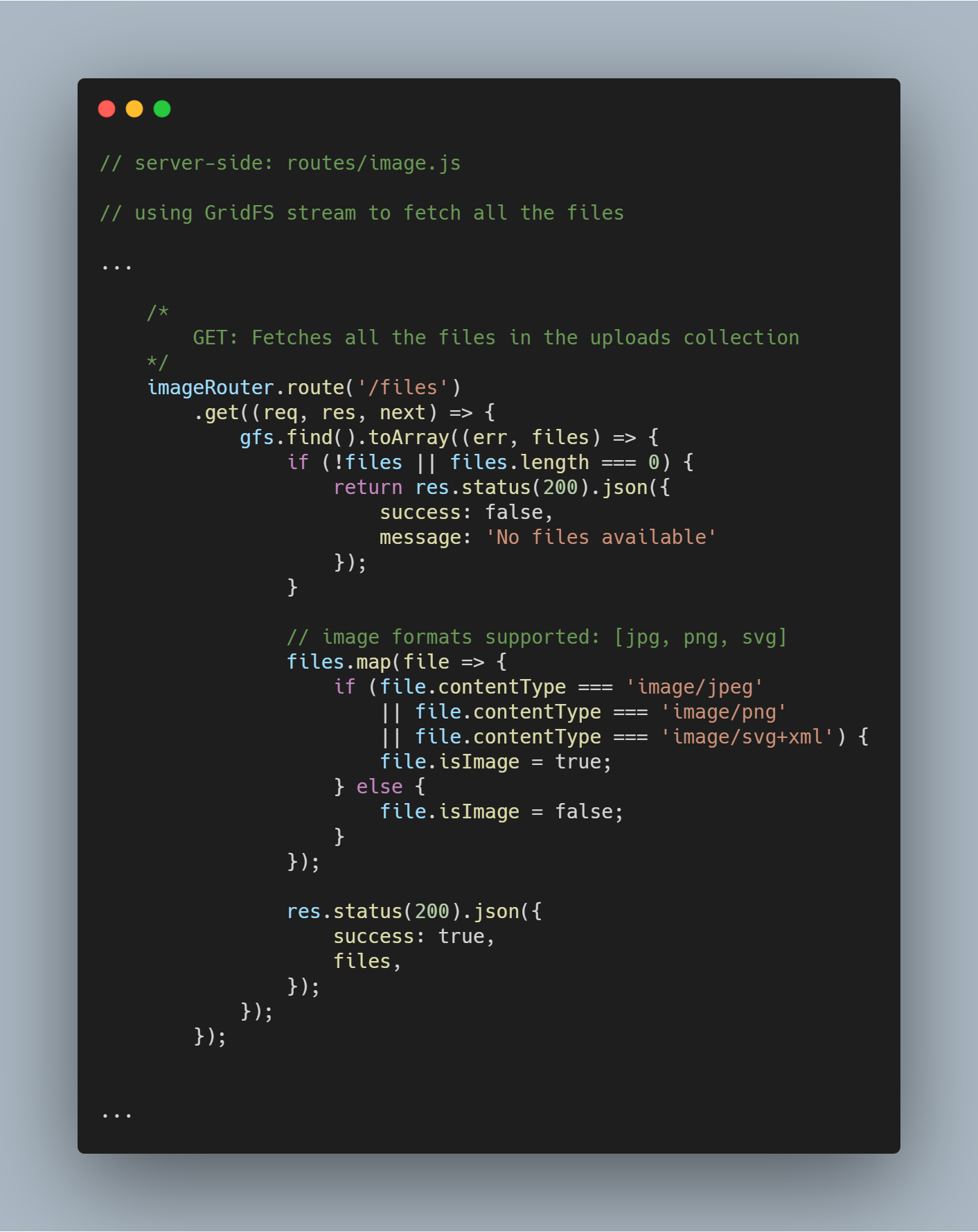
Fetch all Files From Database
Utilizzando lo stream inizializzato possiamo recuperare tutti i file nel particolare database usando gfs.find().toArray(...). Una volta ottenuti i file li mappiamo in un array e spediamo la risposta.
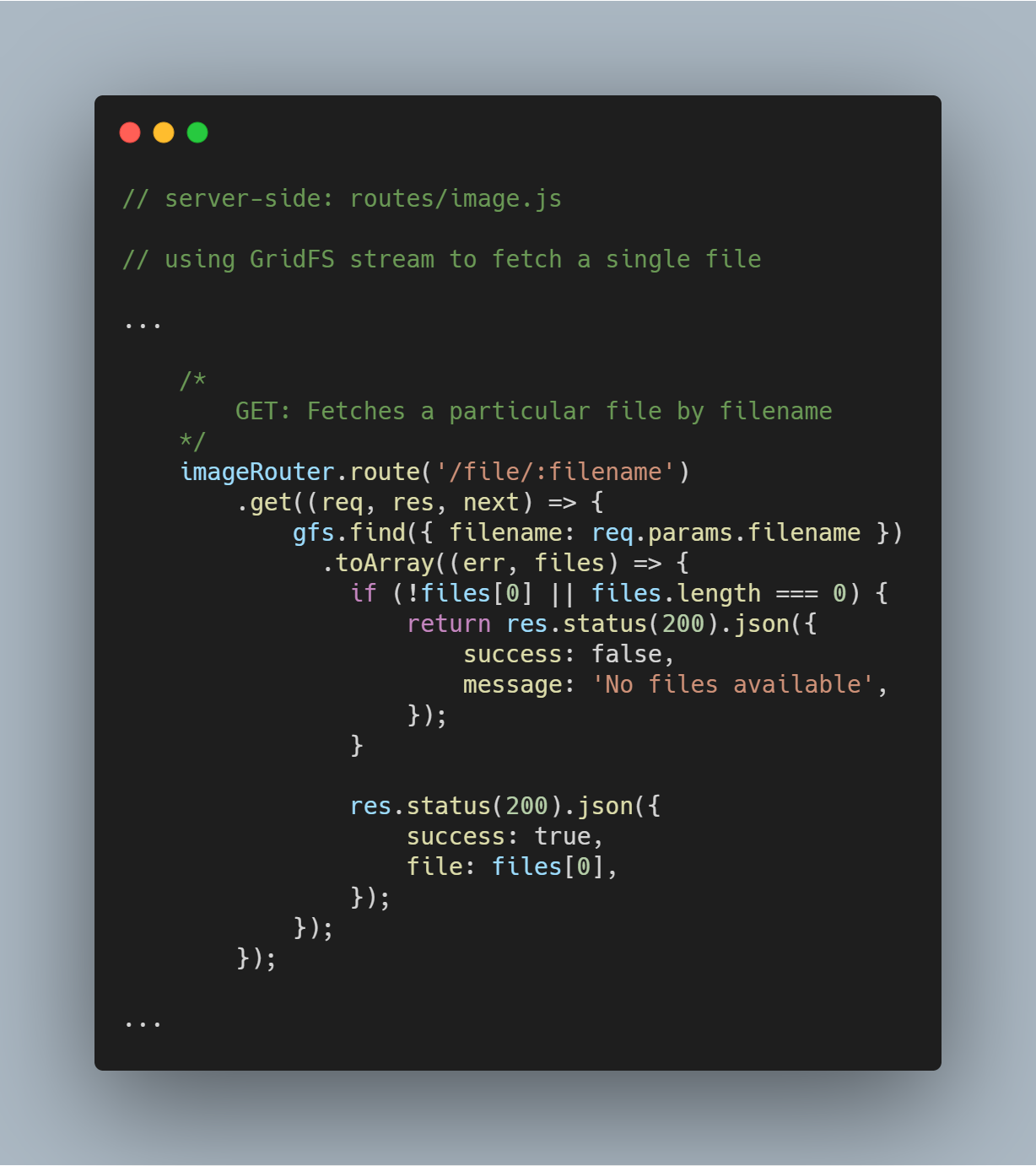
Fetch di un singolo file per nome del file
È super semplice interrogare GridFS per un singolo file basato su un attributo specifico come filename. Usando il flusso GridFS, puoi interrogare il database attraverso la funzione gfs.find({<add query here>}).
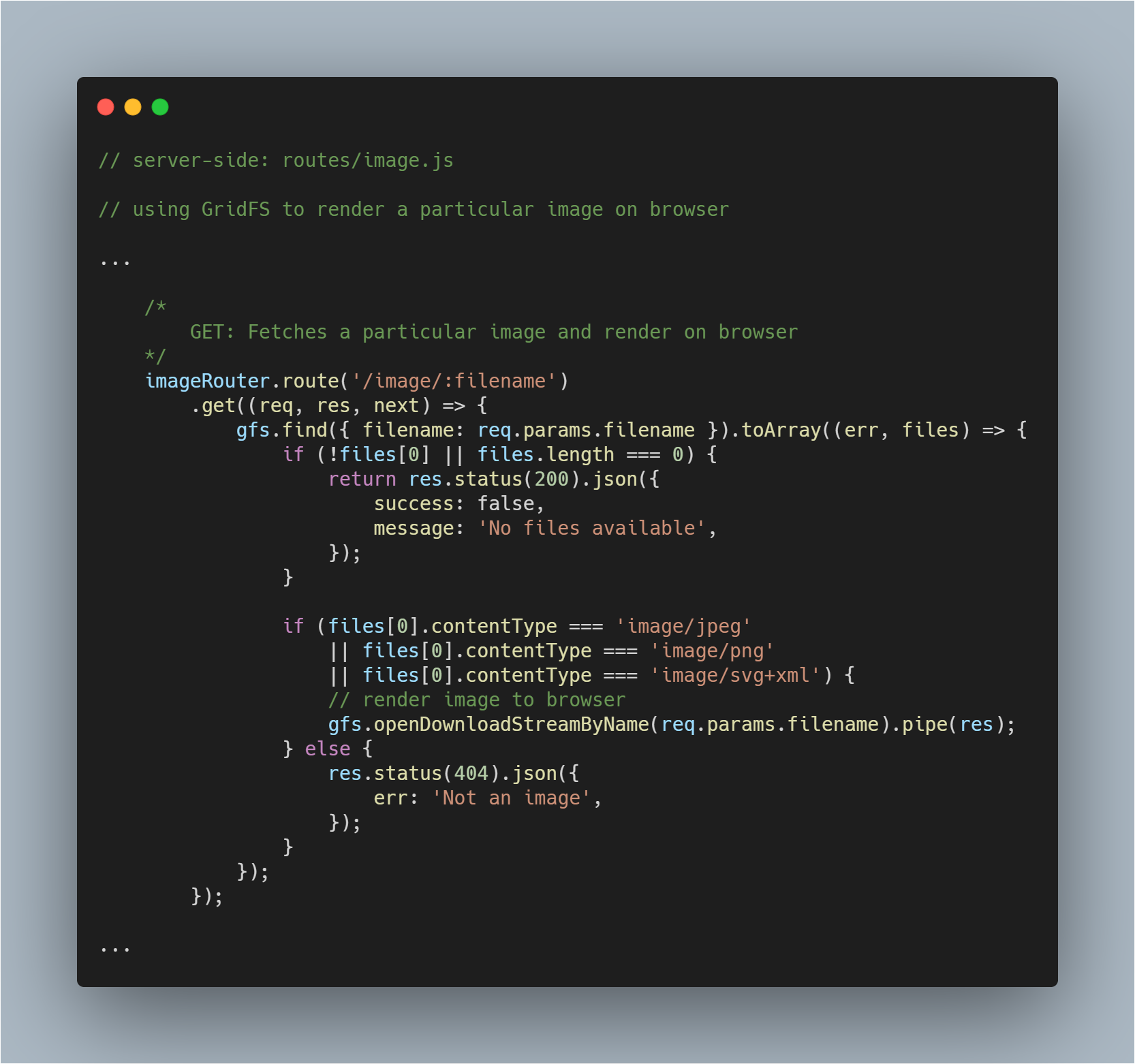
Renderizzare un’immagine recuperata nel browser
Questa è una parte leggermente più complicata poiché non devi solo recuperare un file dal database ma anche renderlo come immagine nel rispettivo browser. Noi recuperiamo il file normalmente. Nessun cambiamento in quel processo.
Poi con l’aiuto del metodo openDownloadStreamByName() su gfs stream, possiamo facilmente renderizzare un’immagine poiché restituisce un flusso leggibile. Fatto questo, possiamo usare il metodo pipe() di JavaScript per trasmettere la risposta.
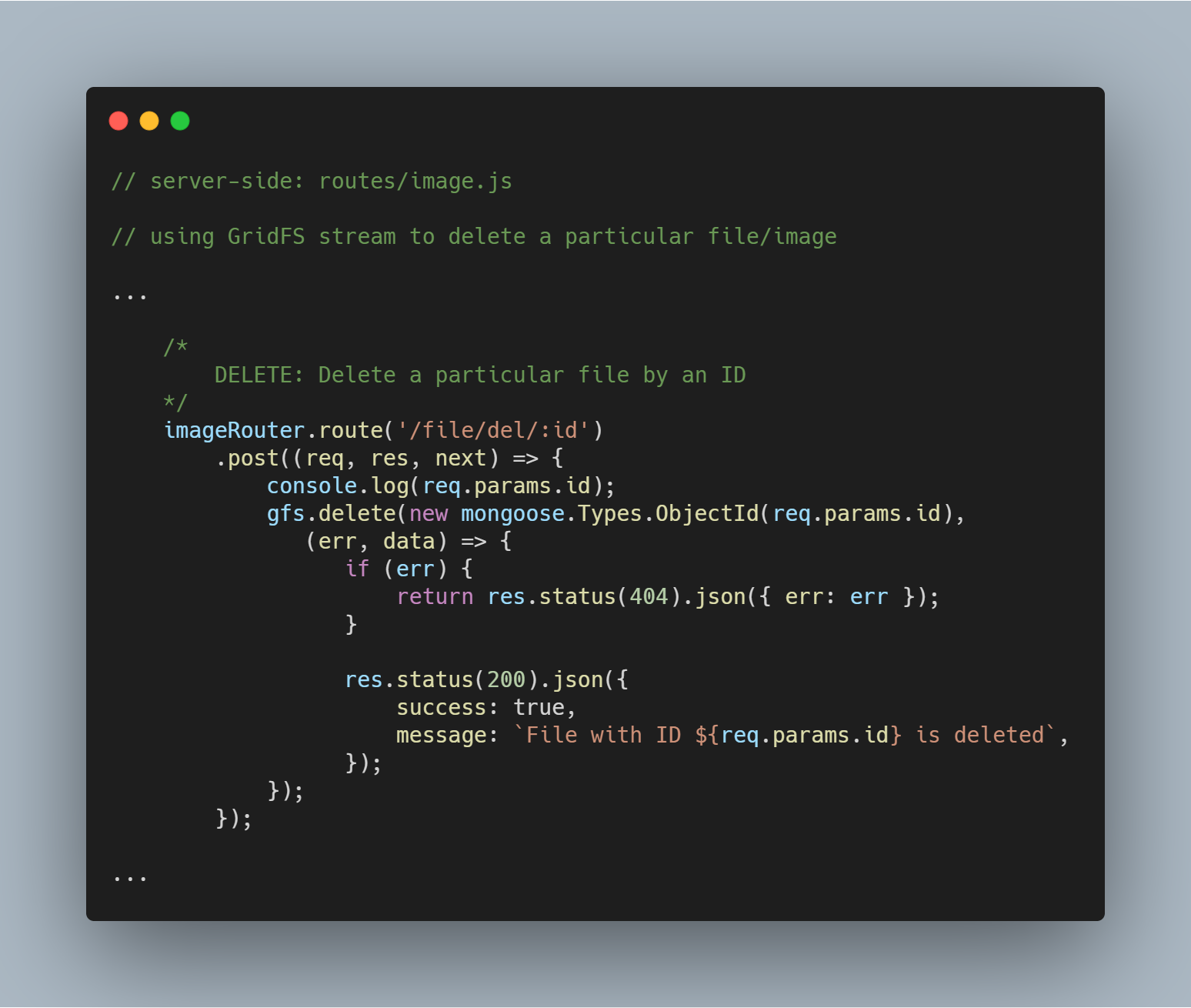
Eliminare un particolare file per Id
Eliminare un file è altrettanto semplice. Usiamo il metodo stream delete() con il parametro _id per interrogare ed eliminare il file in questione.
Queste sono le principali funzionalità offerte dal design dello storage engine. Ho sfruttato le caratteristiche di GridFS discusse per creare una semplice applicazione di caricamento delle immagini. Potete approfondire il codice nel respository.
Conclusione
Mi ci è voluto del tempo e una discreta quantità di fatica per capire come utilizzare GridFS per un progetto personale. A causa di questo, volevo assicurarmi che almeno un’altra persona non dovesse investire la stessa quantità di tempo.
Detto questo, raccomanderei di usare GridFS con cautela. Non è una pallottola d’argento per tutti i vostri problemi di archiviazione dei file. Tuttavia, è una specifica elegante da conoscere e di cui essere consapevoli.