A fájlok tárolása fontos funkció, amelyre a különböző típusú alkalmazások több folyamatában is szükség van. Az olyan folyamatok, mint a Content Delivery Networks (CDNs), a harmadik féltől származó felhő opciók, például az Amazon Web Services, és a helyi fájltárolási lehetőségek létezése mindig is megkönnyítette egy ilyen funkció létrehozását.
A fájlok egyetlen API-híváson keresztül történő közvetlen adatbázisba történő tárolásának koncepciója azonban már jó ideje izgatott. Itt jött számomra a képbe a GridFS.

GridFS – Egy laikus megértése
A MongoDB rendelkezik egy driver specifikációval a fájlok feltöltéséhez és lekérdezéséhez GridFS néven. A GridFS lehetővé teszi a fájlok tárolását és visszakeresését, beleértve a 16 MB-os BSON-dokumentum méretkorlátot meghaladó fájlokat is.
A GridFS alapvetően egy fájlt több darabra bont, amelyek önálló dokumentumként két gyűjteményben tárolódnak:
- a
chunkgyűjtemény (a dokumentumrészeket tárolja), és - a
filegyűjtemény (az ebből következő további metaadatokat tárolja).
Minden darab mérete 255 KB-ra van korlátozva. Ez azt jelenti, hogy az utolsó chunk általában vagy egyenlő, vagy kisebb, mint 255 KB. Elég jól hangzik.
A GridFS-ből történő olvasáskor az illesztőprogram szükség szerint újra összerakja az összes darabot. Ez azt jelenti, hogy a lekérdezési tartománynak megfelelően olvashatod a fájl egyes szakaszait. Például egy hangfájl egy szegmensének meghallgatása vagy egy videofájl egy szakaszának lehívása.
Megjegyzés: A GridFS használata előnyösebb a 16 MB-os méretkorlátot általában meghaladó fájlok tárolására. Kisebb fájlok esetén ajánlott a BinData formátum használata a fájlok egyes dokumentumokban történő tárolásához.
Ez összefoglalja a GridFS általános működését. Ideje belemártani a lábunkat néhány működő kódba, és megnézni, hogyan lehet egy ilyen rendszert megvalósítani.
Elég a beszédből, mutasd meg a kódot
A beállításunkhoz Node.js-t használunk a MongoDB egy felhőpéldányához való hozzáféréssel. A mintaalkalmazás kódtárát itt találod.
 tarique93102GitHub
tarique93102GitHub 
Teljesen a GridFS funkcionalitásához kapcsolódó kódrészletekre fogunk koncentrálni. Megtanuljuk, hogyan kell beállítani és használni fájlok tárolására, fájlok vagy egy adott fájl visszakeresésére és egy adott fájl törlésére. Akkor kezdjük el.
A tárolómotor inicializálása
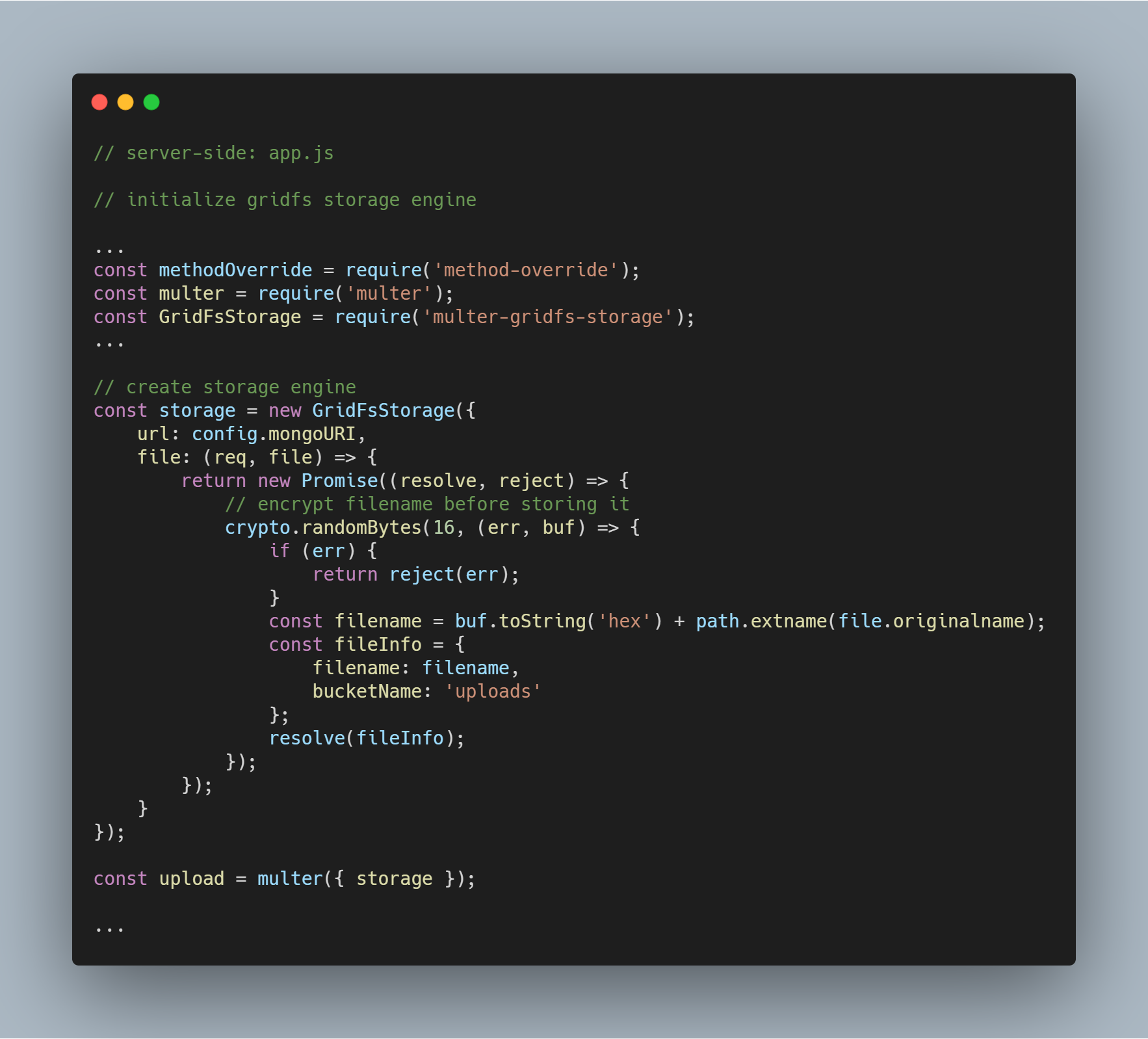
A motor inicializálásához szükséges csomagok a multer-gridfs-storage és a multer. A method-override middleware-t is használjuk a fájlok törlési műveletének engedélyezéséhez. Az npm crypto modult használjuk a fájlnevek titkosítására a tároláskor és az adatbázisból való olvasáskor.
Amikor a GridFS-t használó tárolómotor inicializálva van, csak meg kell hívnunk a multer middleware segítségével. Ezt követően átadjuk a megfelelő útvonalnak, amely végrehajtja a különböző fájltárolási műveleteket.
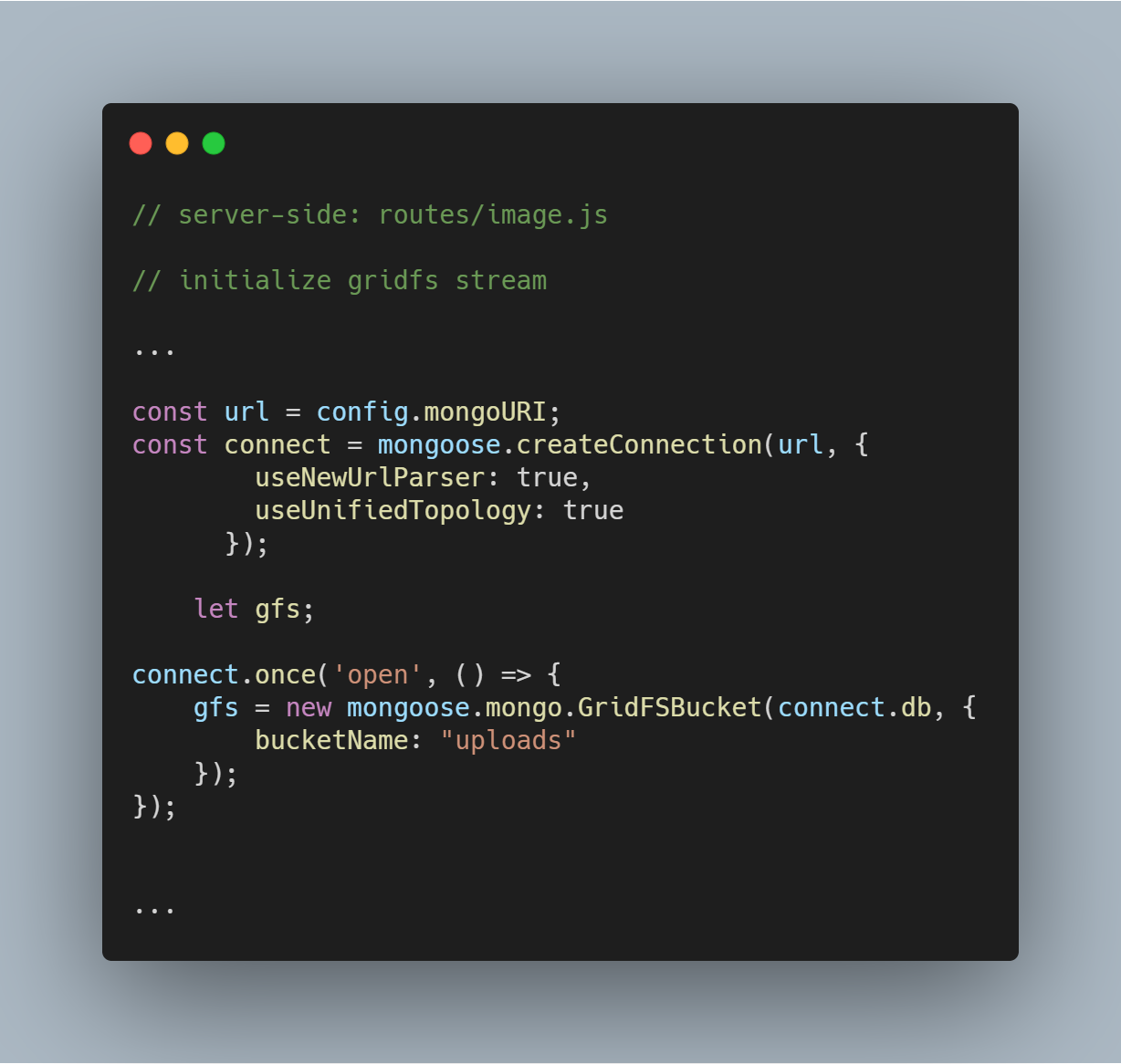
GridFS stream inicializálása
A GridFS streamet az alábbi kódban látható módon inicializáljuk. A streamre azért van szükség, hogy beolvassuk a fájlokat az adatbázisból, valamint azért, hogy szükség esetén segítsen a képet megjeleníteni a böngészőben.
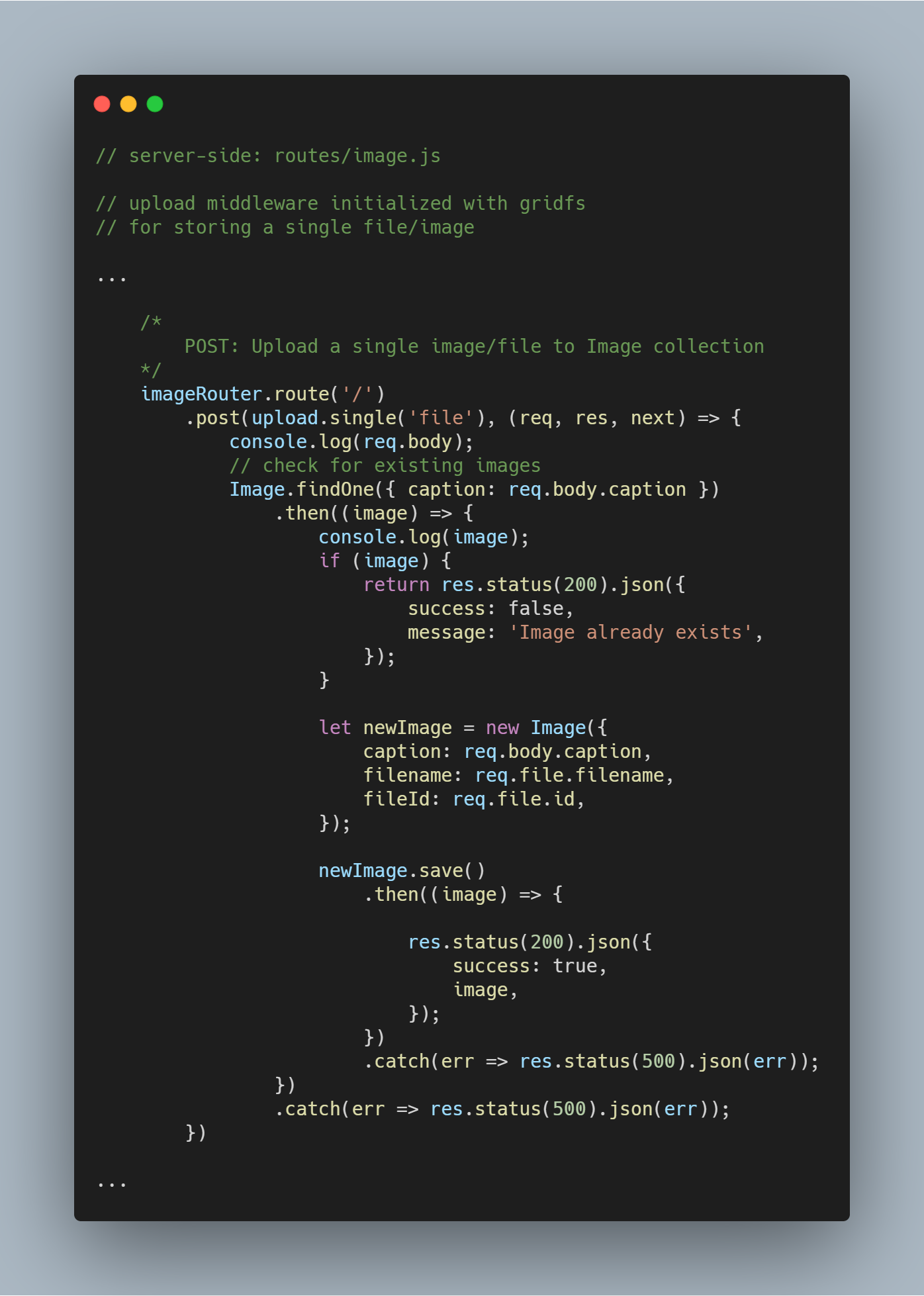
Egyetlen fájl vagy kép feltöltése
Újra felhasználjuk a korábban létrehozott feltöltési middleware-t.
Megjegyzés: A file nevet használjuk paraméterként a upload.single()-ben, mivel a kliens által küldött fájlt hordozó, hasonló nevű kulcsunk van.
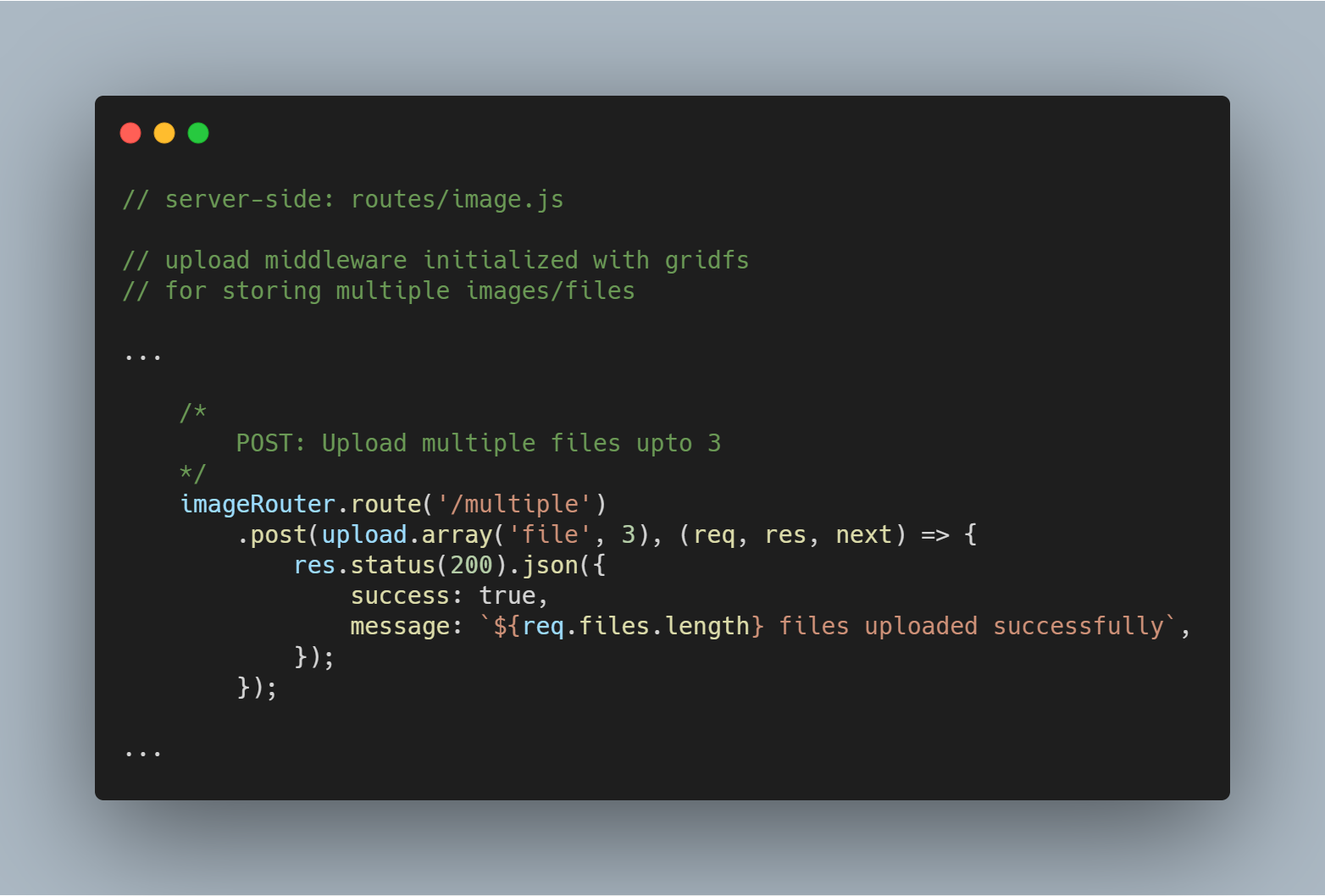
Másik fájl vagy kép feltöltése
Másik fájlt vagy képet is feltölthetjük egyszerre. A upload.single() helyett egyszerűen a upload.multiple(<number of files>) értéket kell használnunk.
Figyelem: A feltöltött fájlok száma lehet kevesebb, mint a meghatározott fájlok száma.
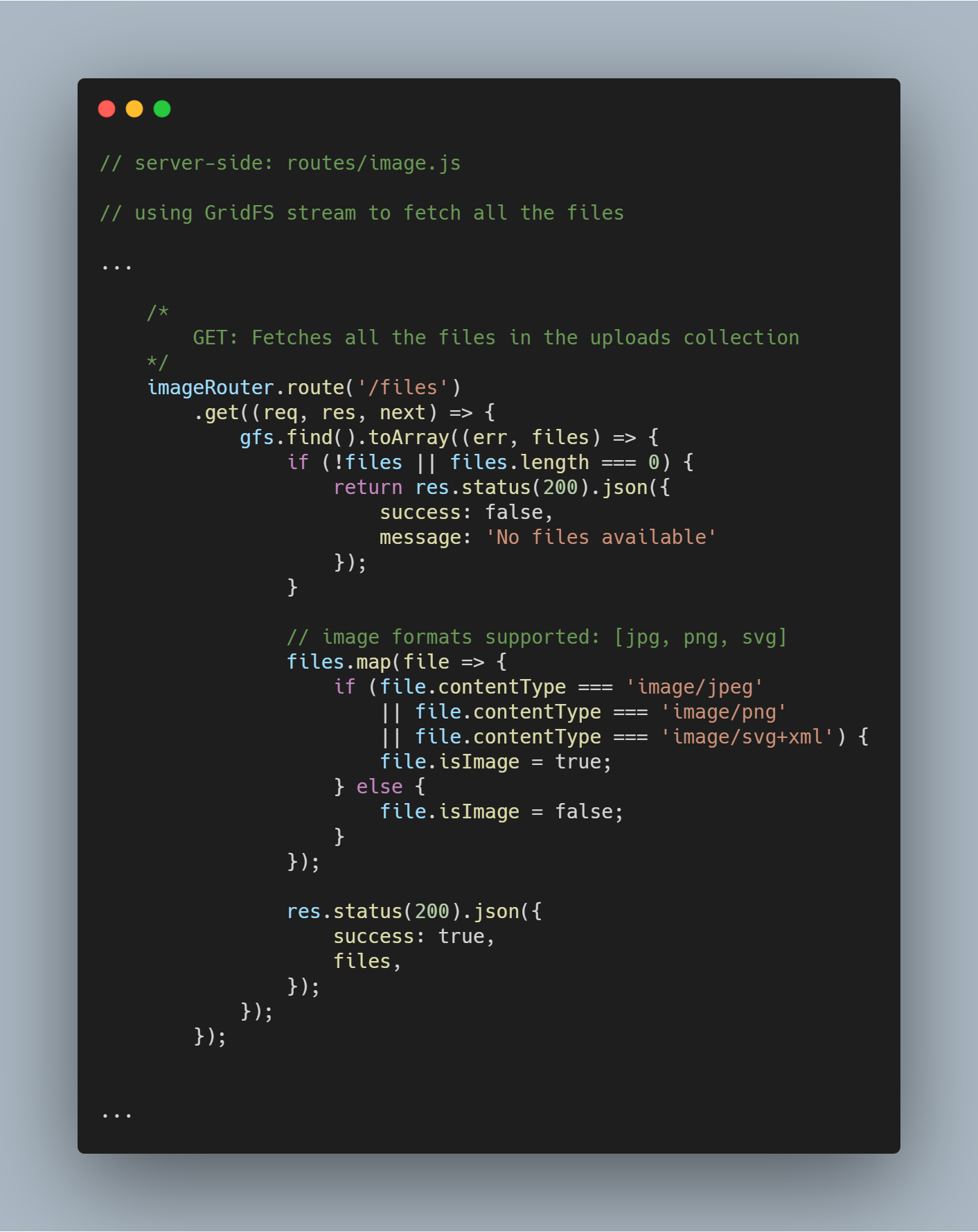
Az összes fájl lekérése az adatbázisból
Az inicializált folyamot használva a gfs.find().toArray(...) segítségével lekérhetjük az adott adatbázisban lévő összes fájlt. Miután megkaptuk a fájlokat, leképezzük egy tömbre, és elküldjük a választ.
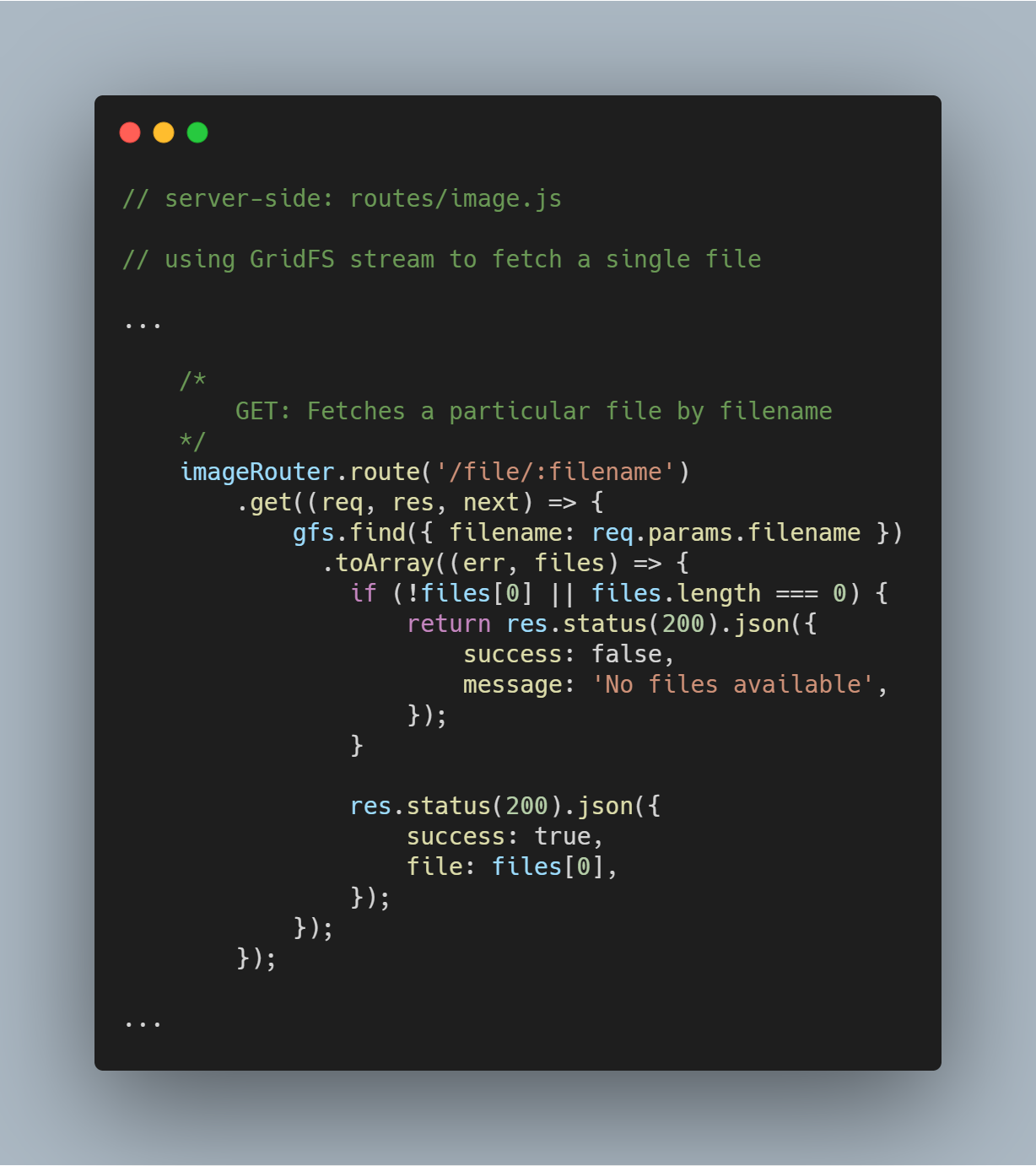
Egyetlen fájl lekérdezése fájlnév alapján
Szuper egyszerű lekérdezni a GridFS-t egyetlen fájlra egy adott attribútum alapján, például filename. A GridFS stream segítségével a gfs.find({<add query here>}) függvényen keresztül lekérdezhetjük az adatbázist.
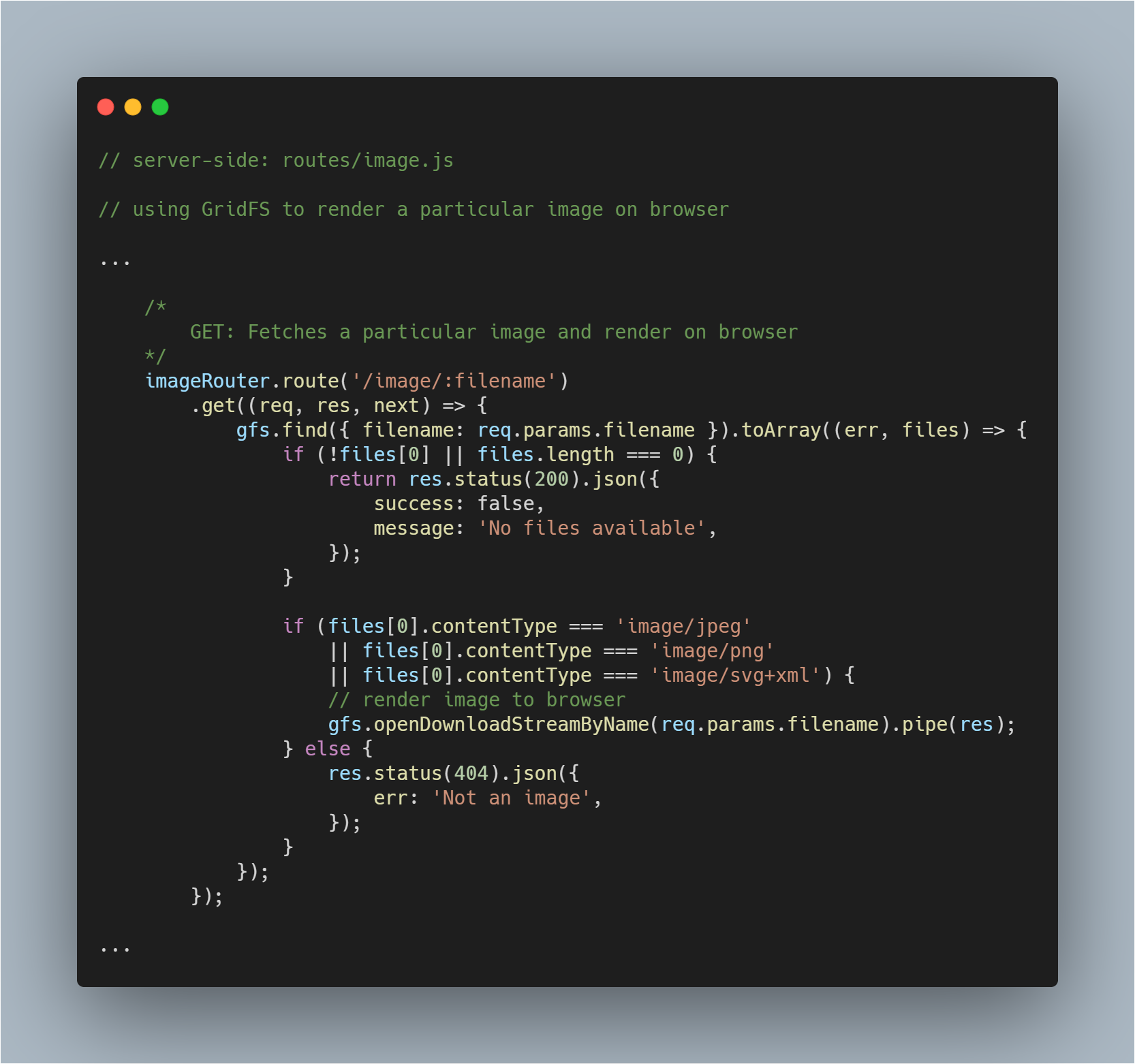
Rendering a Fetched Image to Browser
Ez egy kicsit trükkösebb rész, mivel nem csak le kell hívnunk egy fájlt az adatbázisból, hanem képként is kell megjelenítenünk az adott böngészőben. Normálisan lekérjük a fájlt. Ebben a folyamatban nincs változás.
Ezután a gfs stream openDownloadStreamByName() metódusának segítségével könnyedén megjeleníthetünk egy képet, mivel az egy olvasható streamet ad vissza. Miután ez megtörtént, a JavaScript pipe() segítségével streamelhetjük a választ.
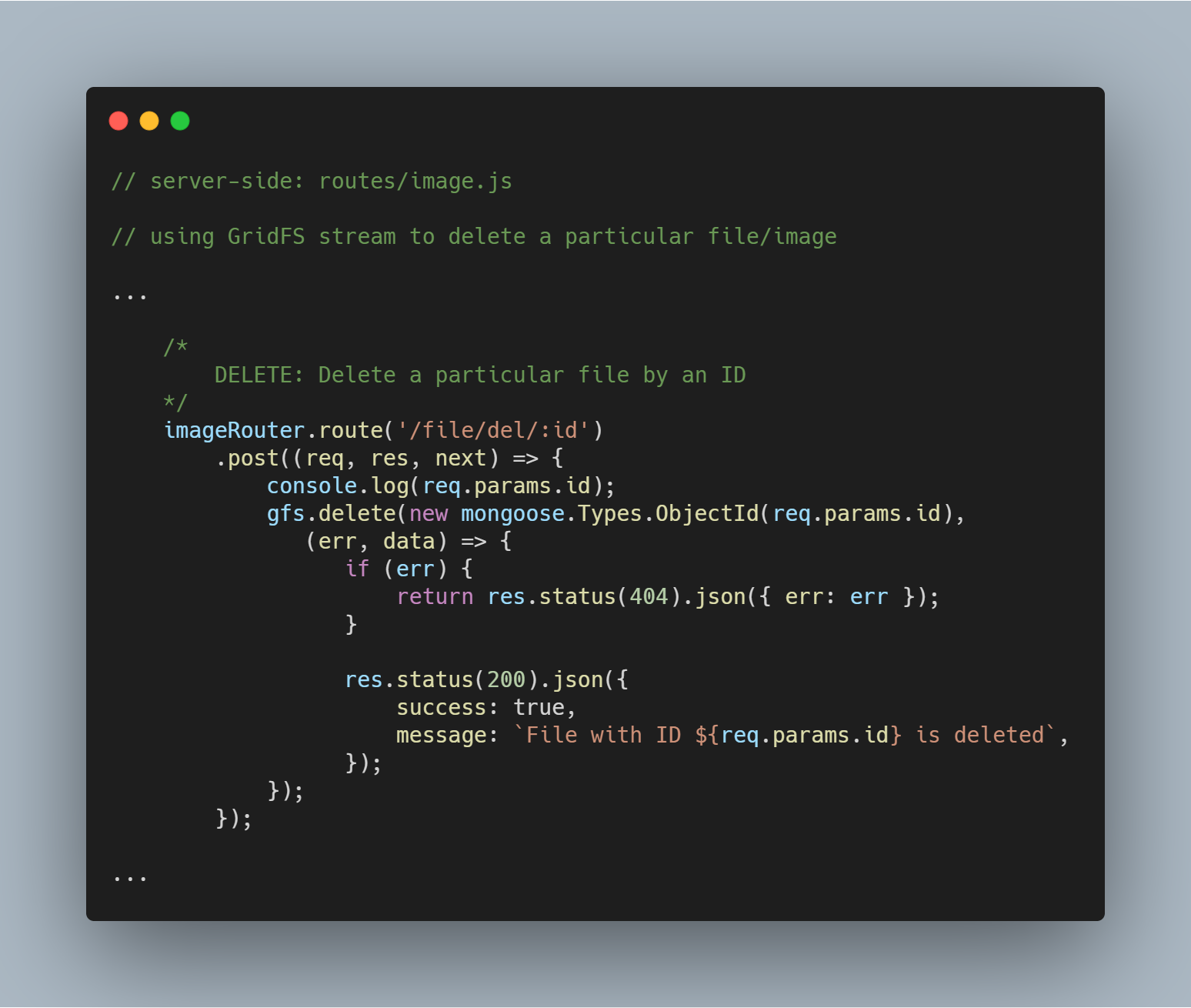
Delete a Particular File by Id
A fájl törlése ugyanilyen egyszerű. A delete() stream metódust delete() használjuk _id paraméterrel az érintett fájl lekérdezéséhez és törléséhez.
Ezek a főbb funkciók, amelyeket a storage engine tervezése kínál. A tárgyalt GridFS funkciókat egy egyszerű képfeltöltő alkalmazás létrehozásához használtam ki. A kódban mélyebben el lehet mélyedni a reszorpozícióban.
Következtetés
Egy kis időbe és tisztességes küzdelembe került, mire megértettem, hogyan lehet a GridFS-t egy személyes projektben felhasználni. Emiatt szerettem volna biztosítani, hogy legalább egy másik személynek ne kelljen ugyanannyi időt befektetnie.
Azt mondtam, hogy a GridFS használatát csak óvatosan ajánlom. Ez nem egy ezüstgolyó az összes fájltárolási problémádra. Mégis, ez egy ügyes specifikáció, amit érdemes ismerni és tisztában lenni vele.