Filopbevaring er en vigtig funktion, der er nødvendig i flere processer på tværs af forskellige typer af applikationer. Eksistensen af processer som Content Delivery Networks (CDNs), der er oprettet via tredjeparts cloud-muligheder som Amazon Web Services og lokale filopbevaringsmuligheder har altid gjort det lettere at bygge en sådan funktion.
Men konceptet med at lagre filer direkte i en database via et enkelt API-kald havde fascineret mig i et stykke tid. Det var her, at GridFS kom ind i billedet for mig.

GridFS – A Layman’s Understanding
MongoDB har en driverspecifikation til at uploade og hente filer fra den kaldet GridFS. GridFS giver dig mulighed for at gemme og hente filer, herunder filer, der overstiger BSON-dokumentstørrelsesgrænsen på 16 MB.
GridFS tager grundlæggende en fil og deler den op i flere chunks, der gemmes som individuelle dokumenter i to samlinger:
-
chunksamlingenchunk(gemmer dokumentdelene) og - samlingen
file(gemmer de deraf følgende yderligere metadata).
Hver chunk er begrænset til en størrelse på 255 KB. Det betyder, at den sidste chunk normalt er enten lig med eller mindre end 255 KB. Det lyder ganske pænt.
Når du læser fra GridFS, samler driveren alle chunks igen efter behov. Det betyder, at du kan læse sektioner af en fil i overensstemmelse med dit forespørgselsområde. Som f.eks. at lytte til et segment af en lydfil eller hente et afsnit af en videofil.
Bemærk: Det er at foretrække at bruge GridFS til lagring af filer, der normalt overstiger størrelsesgrænsen på 16 MB. For mindre filer anbefales det at bruge BinData-formatet til at gemme filerne i enkeltdokumenter.
Dette opsummerer, hvordan GridFS fungerer generelt. Tid til at dyppe fødderne i noget arbejdskode og se, hvordan man implementerer et system som sådan.
Enough Talk, Show Me the Code
Vi bruger Node.js med adgang til en cloud-instans af MongoDB til vores opsætning. Du kan finde kodeoplaget for prøveapplikationen her.
 tarique93102102GitHub
tarique93102102GitHub 
Vi vil helt fokusere på de segmenter af koden, der vedrører funktionaliteterne i GridFS. Vi vil lære at opsætte den og bruge den til at gemme filer, hente filer eller en bestemt fil og slette en bestemt fil. Lad os så begynde.
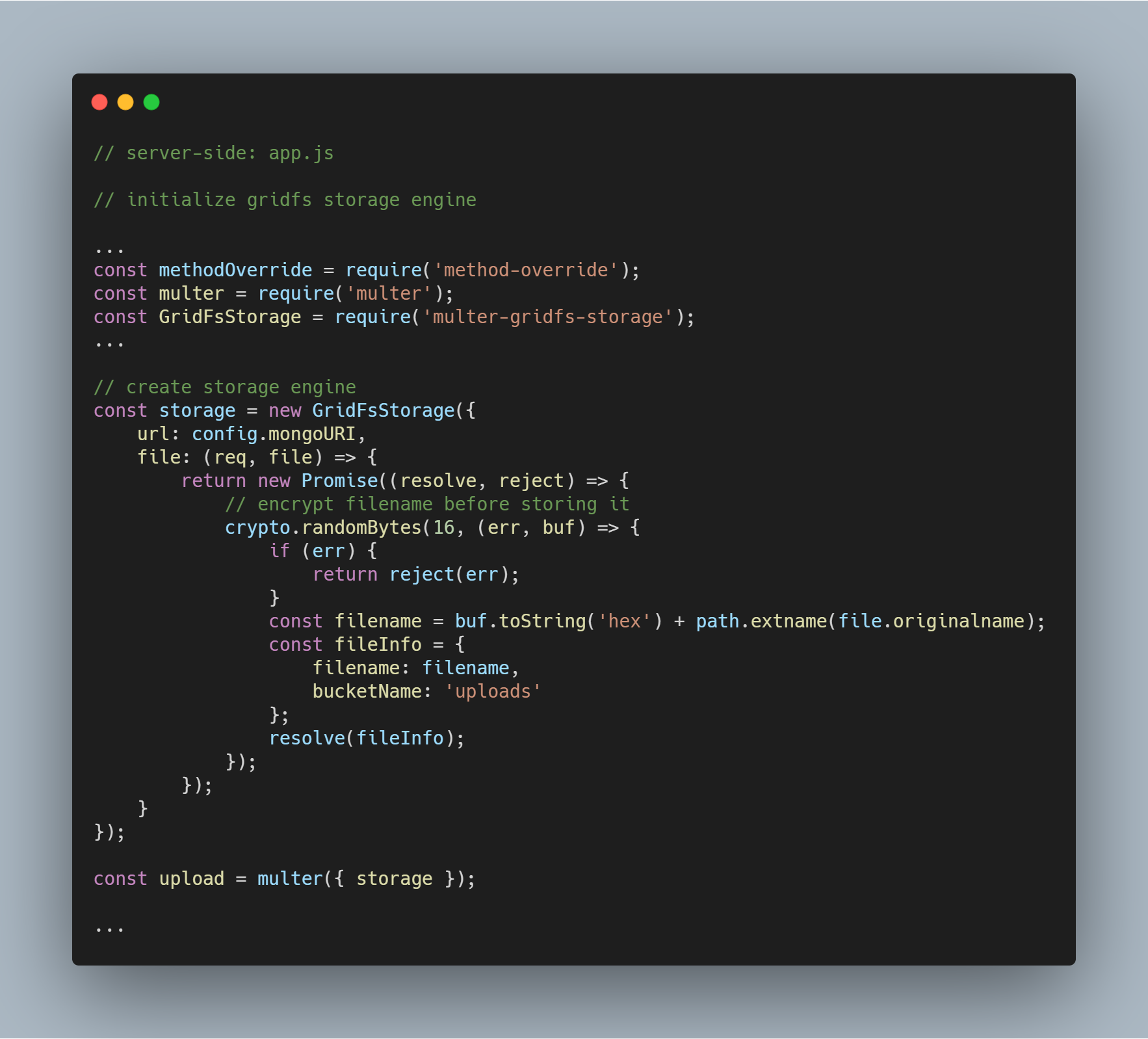
Initialisér lagermotoren
De pakker, der er nødvendige for at initialisere motoren, er multer-gridfs-storage og multer. Vi bruger også method-override middleware til at aktivere sletteoperationen for filer. npm-modulet crypto bruges til at kryptere filnavne ved lagring og læsning fra databasen.
Når lagringsmotoren ved hjælp af GridFS er initialiseret, skal du blot kalde den ved hjælp af multer middleware. Den sendes derefter videre til den respektive rute, der udfører de forskellige filopbevaringsoperationer.
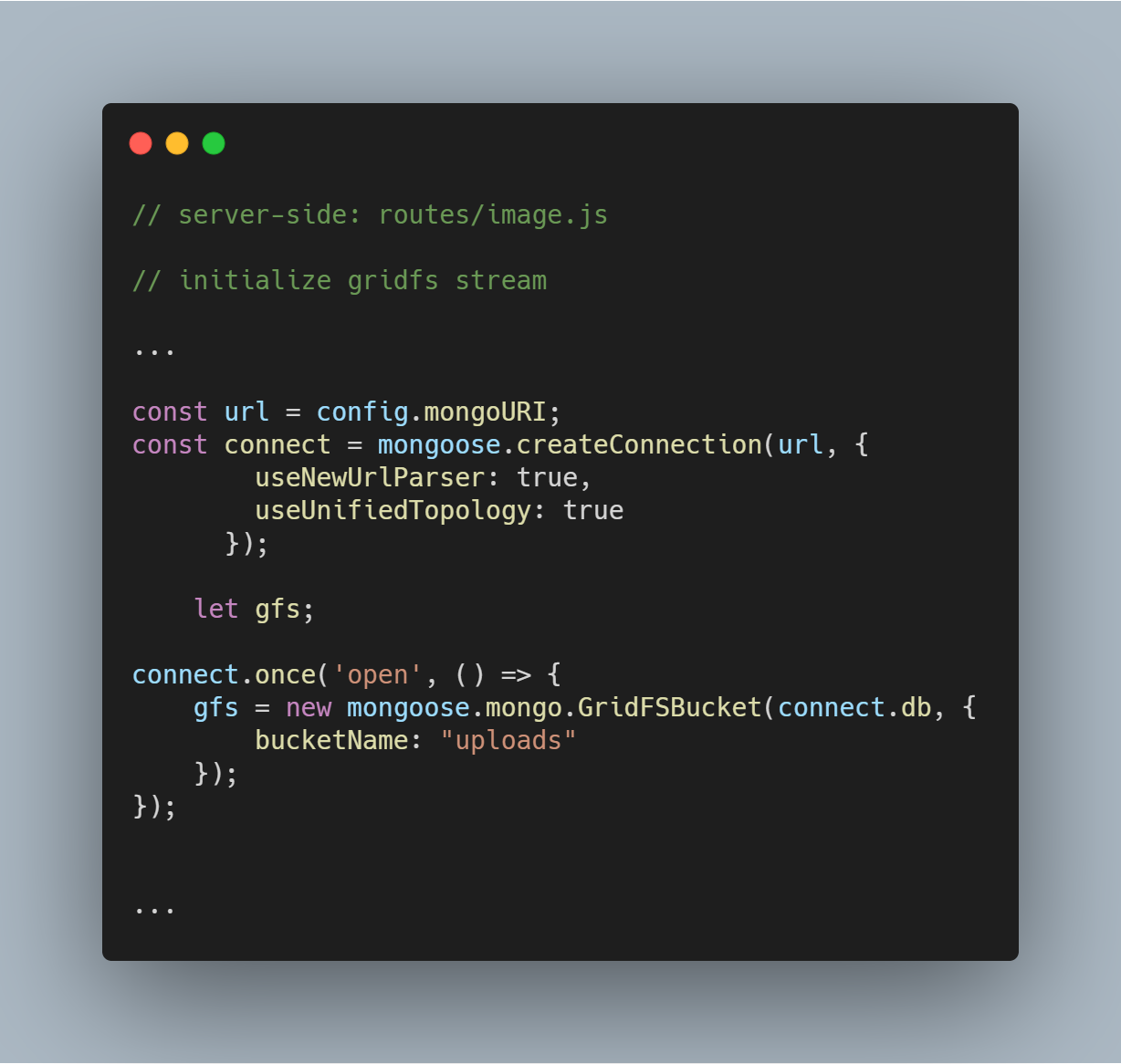
Initialisér GridFS-stream
Vi initialiserer en GridFS-stream som vist i nedenstående kode. Strømmen er nødvendig for at læse filerne fra databasen og også for at hjælpe med at gengive et billede til en browser, når det er nødvendigt.
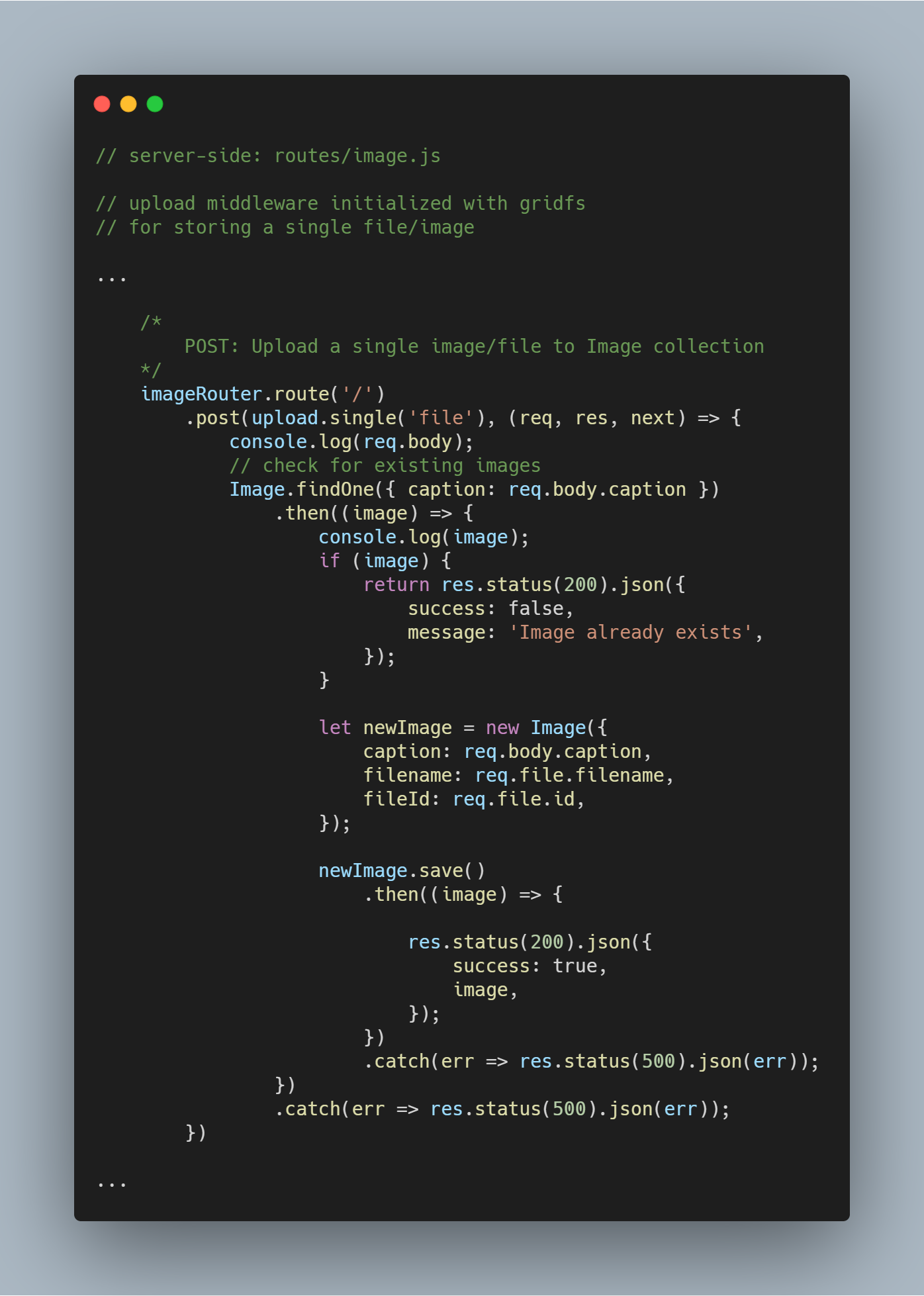
Opload en enkelt fil eller et enkelt billede
Vi genbruger den upload-middleware, vi havde oprettet tidligere.
Bemærk: Navnet file bruges som en parameter i upload.single(), da vi har nøglen med et lignende navn, der bærer den fil, der sendes fra klienten.
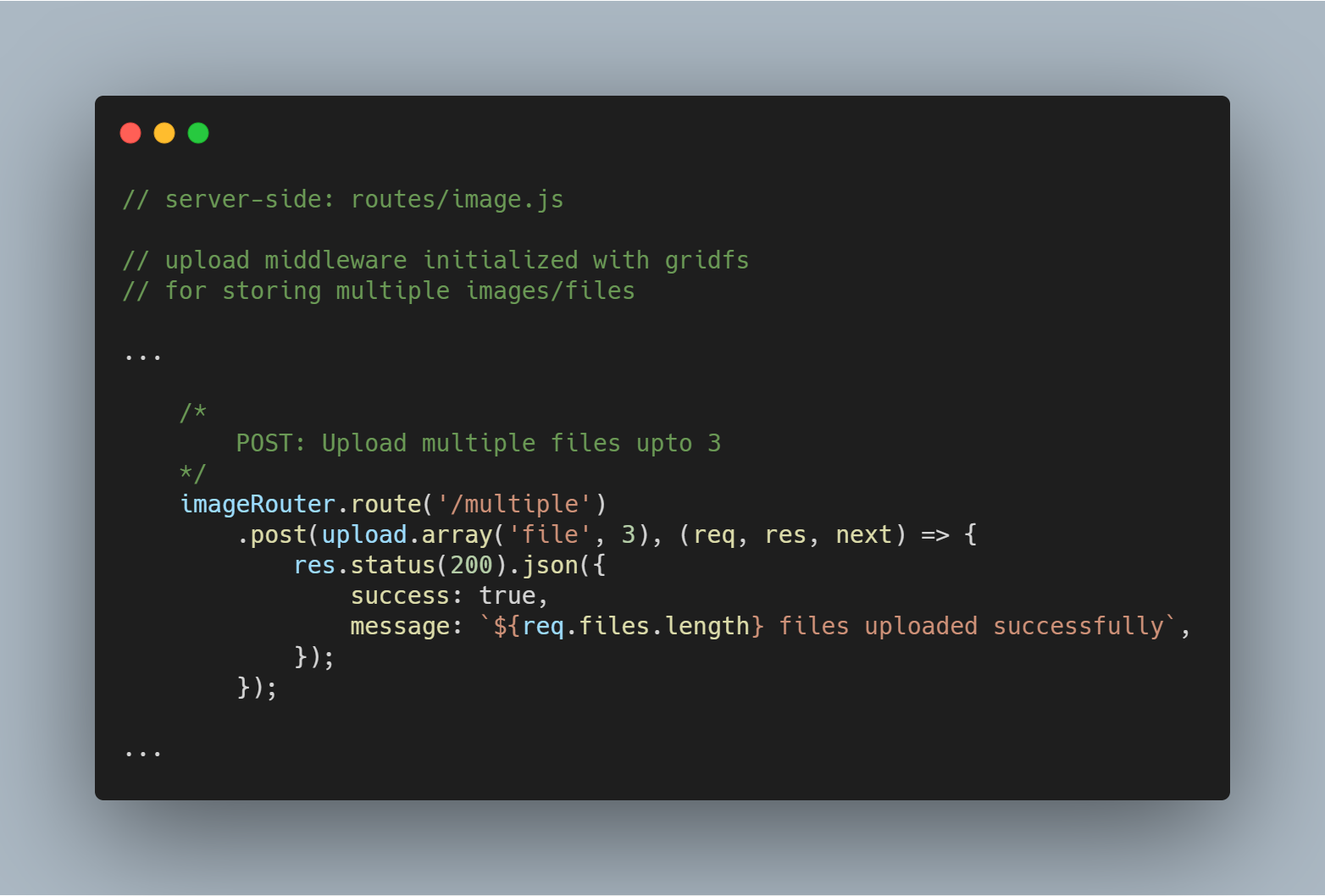
Opload flere filer eller billeder
Vi kan også uploade flere filer på én gang. I stedet for upload.single() skal vi blot bruge upload.multiple(<number of files>).
Bemærk: Antallet af uploadede filer kan være mindre end det definerede antal filer.
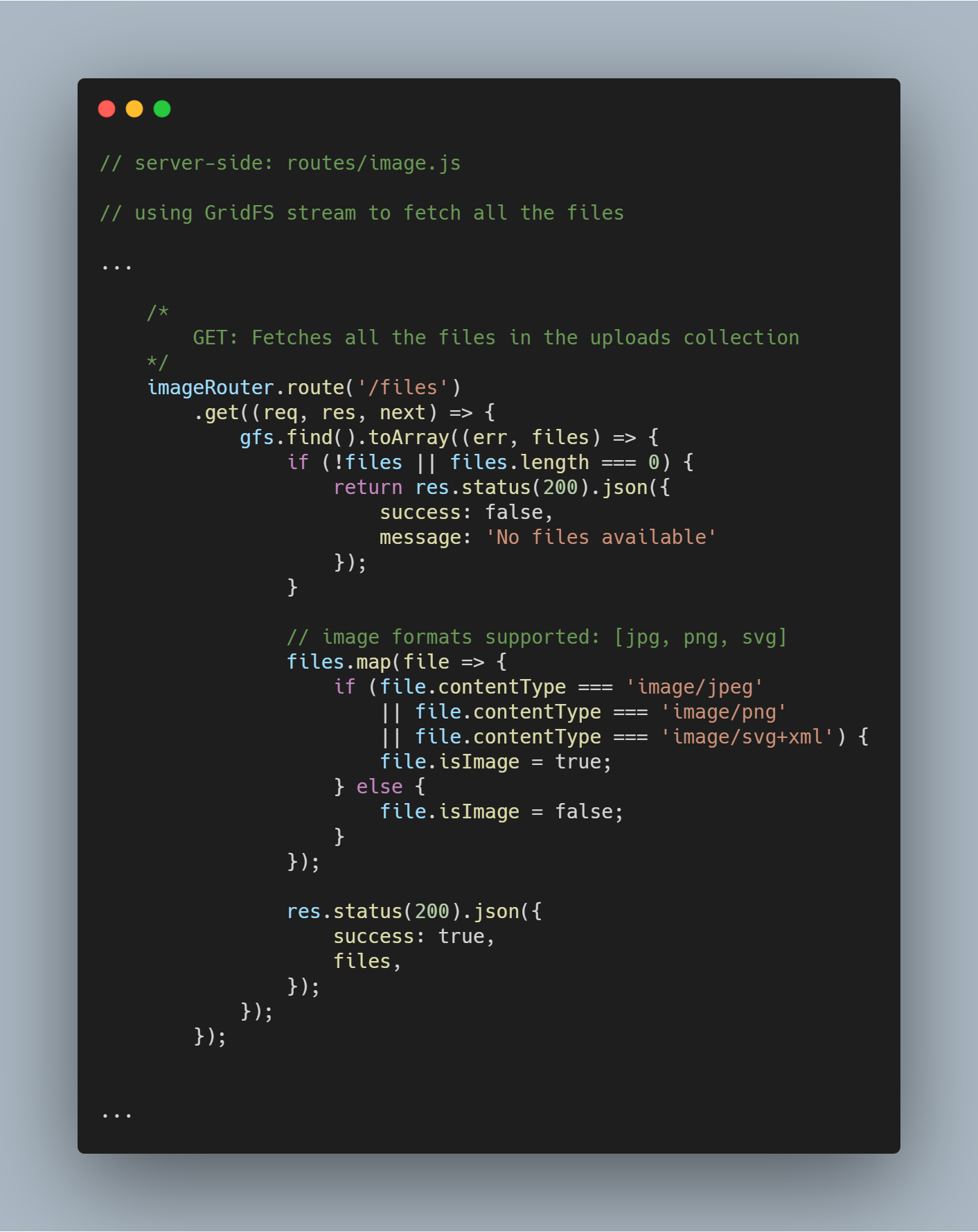
Hent alle filer fra databasen
Ved hjælp af den initialiserede stream kan vi hente alle filer i den pågældende database ved hjælp af gfs.find().toArray(...). Når filerne er hentet, mapper vi det til et array og sender svaret.
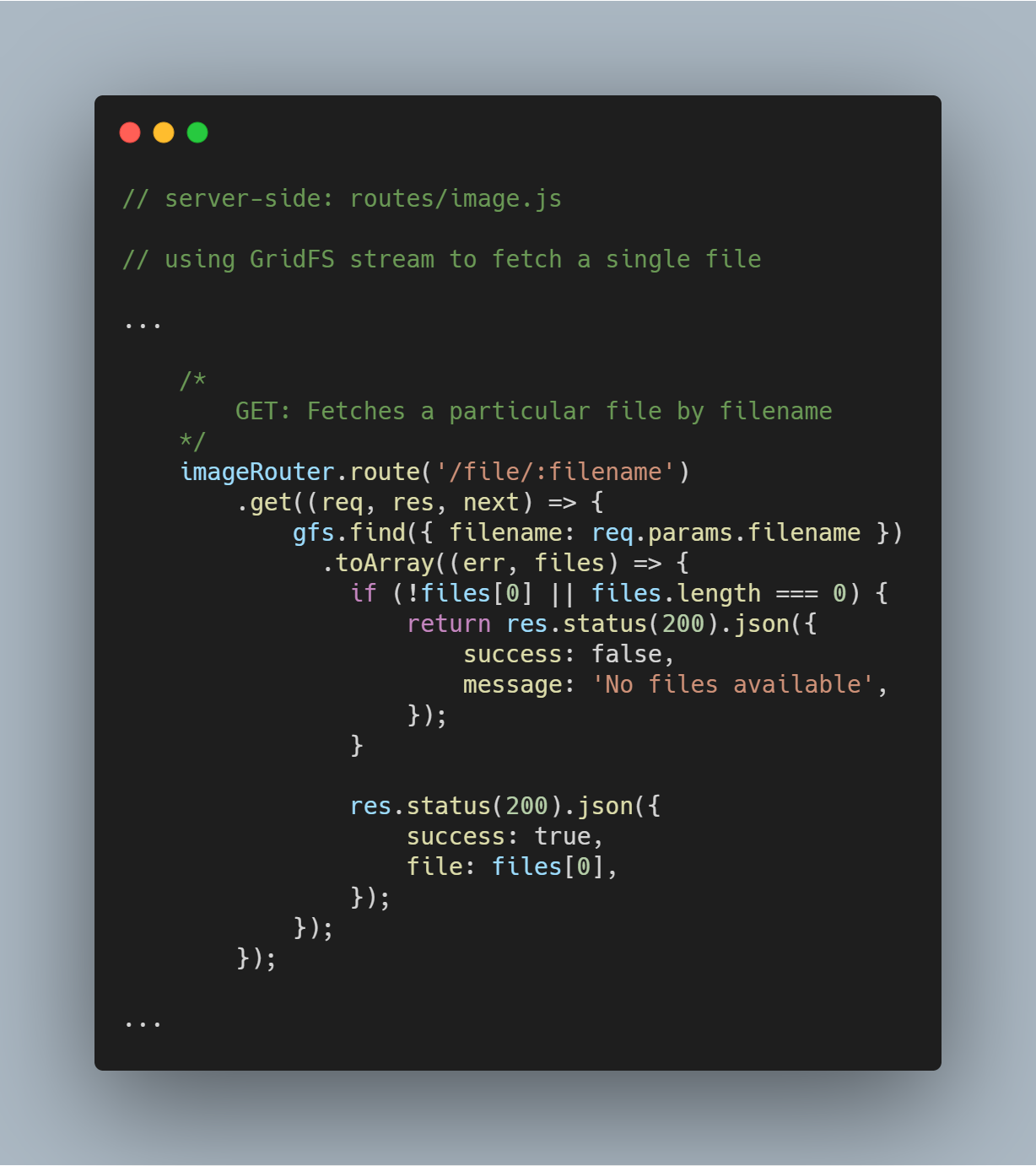
Henter en enkelt fil ved filnavn
Det er super enkelt at forespørge GridFS efter en enkelt fil baseret på en specifik attribut som filename. Ved hjælp af GridFS-strømmen kan du forespørge databasen via funktionen gfs.find({<add query here>}).
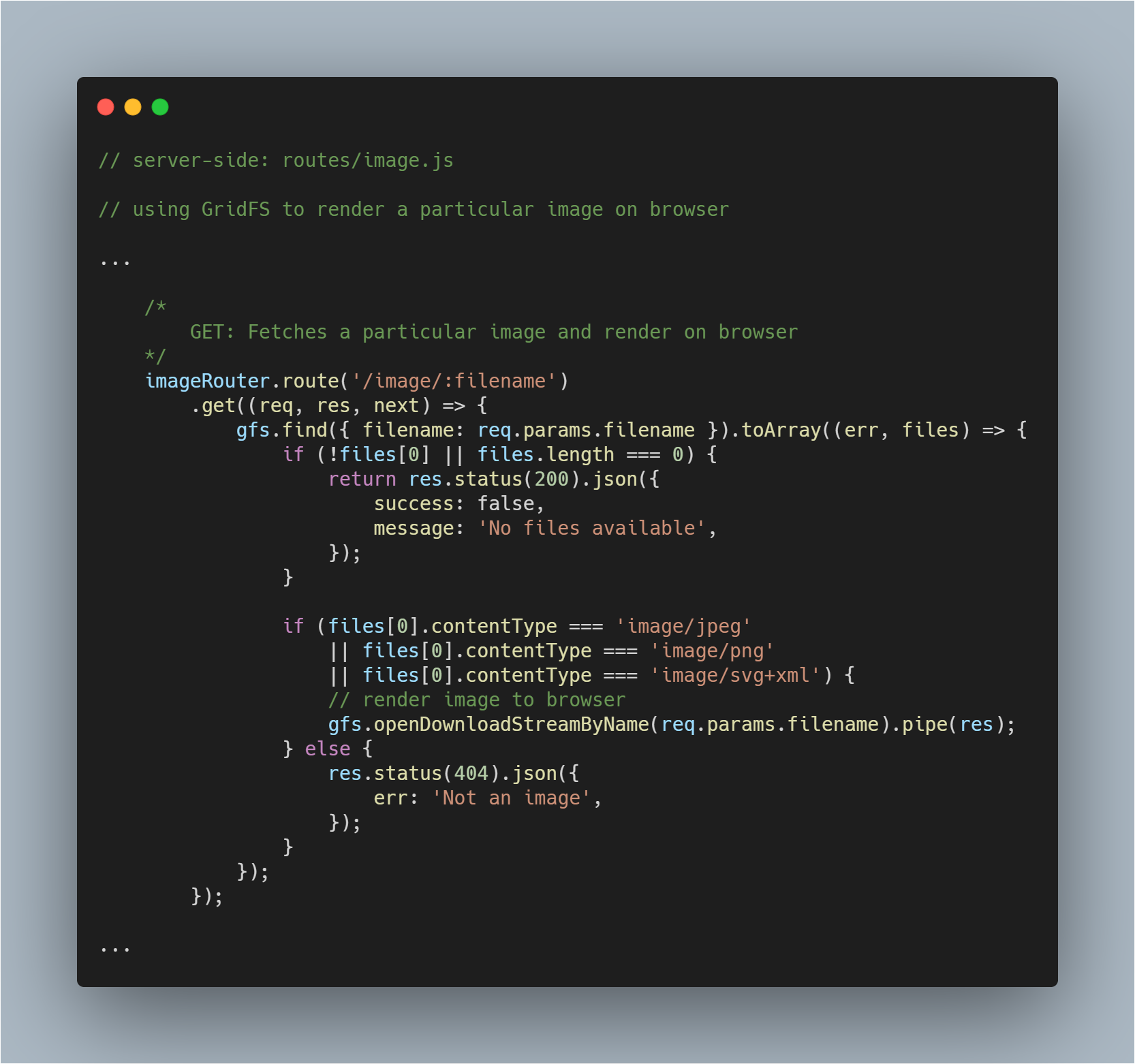
Render et hentet billede til browseren
Dette er en lidt vanskeligere del, da du ikke kun skal hente en fil fra databasen, men også skal rendere den som et billede i den pågældende browser. Vi henter filen normalt. Ingen ændring i den proces.
Dernæst kan vi ved hjælp af metoden openDownloadStreamByName() på gfs stream nemt gengive et billede, da den returnerer en læsbar stream. Når det er gjort, kan vi bruge JavaScript’s pipe() til at streame svaret.
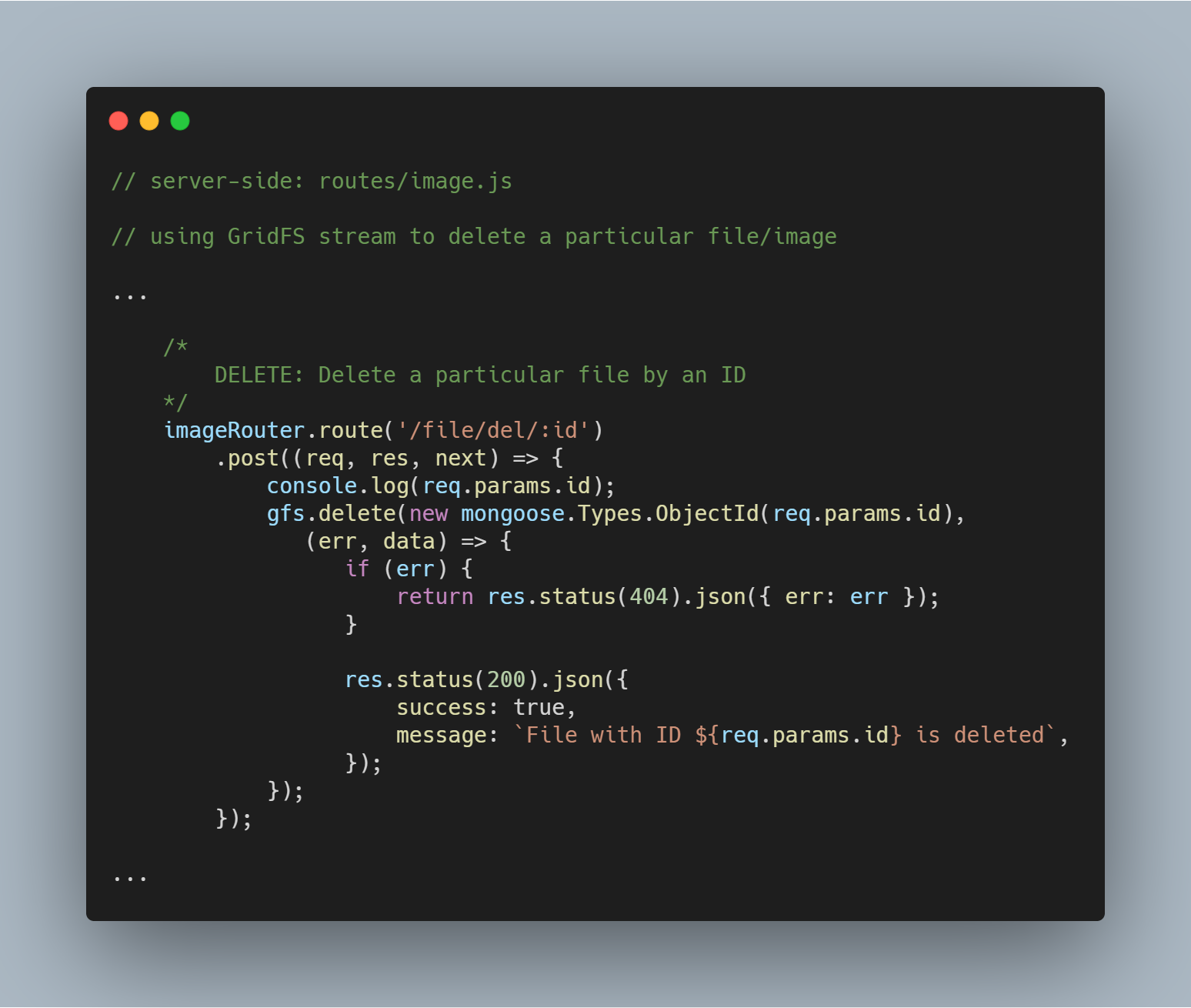
Slet en bestemt fil efter Id
Det er lige så ligetil at slette en fil. Vi bruger stream-metoden delete() med parameteren _id til at forespørge og slette den pågældende fil.
Dette er de vigtigste funktionaliteter, som storage engine-designet tilbyder. Jeg havde udnyttet de GridFS-funktioner, der blev diskuteret, til at oprette et simpelt program til upload af billeder. Du kan dykke dybere ned i koden i respository.
Slutning
Det tog mig noget tid og en ordentlig mængde kamp at forstå, hvordan jeg kunne gøre brug af GridFS til et personligt projekt. På grund af dette ønskede jeg at sikre mig, at mindst én anden person ikke skulle investere den samme mængde tid.
Når det er sagt, vil jeg anbefale, at man bruger GridFS med forsigtighed. Det er ikke en sølvkugle til alle dine filopbevaringsproblemer. Alligevel er det en smart specifikation at kende og være opmærksom på.