Par Derrick Mwiti, analyste de données

Note de la rédaction : Ce tutoriel illustre comment commencer à prévoir des séries temporelles avec des modèles LSTM. Les données boursières sont un excellent choix pour cela car elles sont assez régulières et largement disponibles pour tout le monde. S’il vous plaît, ne prenez pas cela comme un conseil financier ou ne l’utilisez pas pour faire vos propres transactions.
Dans ce tutoriel, nous allons construire un modèle d’apprentissage profond Python qui va prédire le comportement futur des prix des actions. Nous supposons que le lecteur est familier avec les concepts d’apprentissage profond en Python, en particulier la mémoire à long terme.
Bien que la prédiction du prix réel d’une action soit une ascension difficile, nous pouvons construire un modèle qui prédit si le prix va monter ou descendre. Les données et le carnet de notes utilisés pour ce tutoriel peuvent être trouvés ici. Il est important de noter qu’il y a toujours d’autres facteurs qui affectent le prix des actions, comme l’atmosphère politique et le marché. Cependant, nous ne nous concentrerons pas sur ces facteurs pour ce tutoriel.
Introduction
Les LSTM sont très puissants dans les problèmes de prédiction de séquence car ils sont capables de stocker des informations passées. Ceci est important dans notre cas, car le prix précédent d’une action est crucial pour prédire son prix futur.
Nous commencerons par importer NumPy pour le calcul scientifique, Matplotlib pour tracer des graphiques, et Pandas pour aider à charger et à manipuler nos ensembles de données.
Chargement du jeu de données
La prochaine étape consiste à charger notre jeu de données d’entraînement et à sélectionner les Open et Highcolonnes que nous utiliserons dans notre modélisation.
Nous vérifions la tête de notre ensemble de données pour nous donner un aperçu du type d’ensemble de données avec lequel nous travaillons.
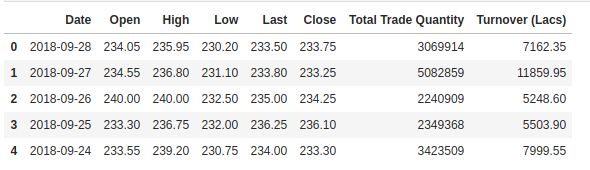
La colonne Open est le prix de départ tandis que la colonne Close est le prix final d’une action sur un jour de négociation particulier. Les colonnes High et Low représentent les prix les plus élevés et les plus bas pour un jour donné.
Mise à l’échelle des caractéristiques
D’après nos expériences précédentes avec les modèles d’apprentissage profond, nous savons que nous devons mettre nos données à l’échelle pour obtenir des performances optimales. Dans notre cas, nous utiliserons le MinMaxScaler de Scikit- Learn et mettrons à l’échelle notre ensemble de données à des nombres compris entre zéro et un.
Création de données avec des timesteps
Les LSTM attendent de nos données qu’elles soient dans un format spécifique, généralement un tableau 3D. Nous commençons par créer des données en 60 timesteps et les convertir en tableau à l’aide de NumPy. Ensuite, nous convertissons les données en un tableau de dimension 3D avec X_train échantillons, 60 horodatages, et une caractéristique à chaque étape.
Construction du LSTM
Pour construire le LSTM, nous devons importer quelques modules de Keras :
-
Sequentialpour initialiser le réseau neuronal -
Densepour ajouter une couche de réseau neuronal densément connectée -
LSTMpour ajouter la couche de mémoire à long court terme -
Dropoutpour ajouter des couches d’abandon qui empêchent l’ajustement excessif
Nous ajoutons la couche LSTM et ajoutons plus tard quelques couches Dropout pour empêcher l’ajustement excessif. Nous ajoutons la couche LSTM avec les arguments suivants :
- 50 unités qui est la dimensionnalité de l’espace de sortie
-
return_sequences=Truequi détermine s’il faut retourner la dernière sortie dans la séquence de sortie, ou la séquence complète -
input_shapecomme forme de notre ensemble d’entraînement.
Lors de la définition des couches Dropout, nous spécifions 0,2, ce qui signifie que 20% des couches seront abandonnées. Par la suite, nous ajoutons la couche Dense qui spécifie la sortie de 1 unité. Après cela, nous compilons notre modèle en utilisant l’optimiseur populaire adam et définissons la perte comme étant la mean_squarred_error. Cela permettra de calculer la moyenne des erreurs quadratiques. Ensuite, nous ajustons le modèle pour qu’il fonctionne sur 100 époques avec une taille de lot de 32. Gardez à l’esprit que, selon les spécifications de votre ordinateur, cela peut prendre quelques minutes pour finir de s’exécuter.
Prédire les actions futures en utilisant l’ensemble de test
D’abord, nous devons importer l’ensemble de test que nous utiliserons pour faire nos prédictions sur.
Pour prédire les futurs prix des actions, nous devons faire quelques choses après avoir chargé l’ensemble de test :
- Fusionner l’ensemble d’entraînement et l’ensemble de test sur l’axe 0.
- Fixer le pas de temps à 60 (comme vu précédemment)
- Utiliser
MinMaxScalerpour transformer le nouvel ensemble de données - Réorganiser l’ensemble de données comme fait précédemment
Après avoir fait les prédictions, nous utilisons inverse_transform pour récupérer les prix des actions dans un format lisible normal.
Placage des résultats
Enfin, nous utilisons Matplotlib pour visualiser le résultat du prix prédit de l’action et le prix réel de l’action.
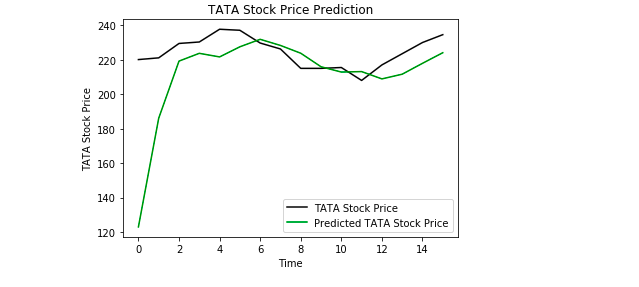
D’après le graphique, nous pouvons voir que le prix réel de l’action a augmenté alors que notre modèle a également prédit que le prix de l’action va augmenter. Cela montre clairement la puissance des LSTM pour l’analyse des séries temporelles et des données séquentielles.
Conclusion
Il existe quelques autres techniques de prédiction du prix des actions telles que les moyennes mobiles, la régression linéaire, les K-Proches Voisins, l’ARIMA et Prophet. Ce sont des techniques que l’on peut tester soi-même et comparer leurs performances avec le LSTM de Keras. Si vous souhaitez en savoir plus sur Keras et l’apprentissage profond, vous pouvez trouver mes articles à ce sujet ici et ici.
Discutez de ce post sur Reddit et Hacker News.
Bio : Derrick Mwiti est un analyste de données, un écrivain et un mentor. Il est motivé par l’obtention d’excellents résultats dans chaque tâche, et est un mentor chez Lapid Leaders Africa.
Original. Reposé avec permission.
Related:
- Introduction à l’apprentissage profond avec Keras
- Introduction à PyTorch pour l’apprentissage profond
- Le flux de travail en 4 étapes de Keras
.