Le stockage de fichiers est une fonctionnalité importante requise dans de multiples processus à travers divers types d’applications. L’existence de processus comme Content Delivery Networks (CDNs), mis en place par des options cloud tierces comme Amazon Web Services, et des options de stockage de fichiers locales ont toujours facilité la construction d’une telle fonctionnalité.
Cependant, le concept de stockage de fichiers directement dans une base de données par le biais d’un appel API unique m’intriguait depuis un certain temps. C’est là que GridFS est entré en scène pour moi.

GridFS – A Layman’s Understanding
MongoDB a une spécification de pilote pour télécharger et récupérer des fichiers à partir de lui appelé GridFS. GridFS vous permet de stocker et de récupérer des fichiers, ce qui inclut ceux qui dépassent la limite de taille des documents BSON de 16 Mo.
GridFS prend essentiellement un fichier et le décompose en plusieurs chunks qui sont stockés comme des documents individuels dans deux collections :
- la collection
chunk(stocke les parties du document), et - la collection
file(stocke les métadonnées supplémentaires conséquentes).
Chaque chunk est limité à 255 Ko en taille. Cela signifie que le dernier chunk est normalement soit égal, soit inférieur à 255 Ko. Cela semble plutôt soigné.
Lorsque vous lisez depuis GridFS, le pilote réassemble tous les chunks selon les besoins. Cela signifie que vous pouvez lire des sections d’un fichier en fonction de votre plage de requête. Comme l’écoute d’un segment d’un fichier audio ou la récupération d’une section d’un fichier vidéo.
Note : Il est préférable d’utiliser GridFS pour stocker des fichiers dépassant normalement la limite de taille de 16 Mo. Pour les fichiers plus petits, il est recommandé d’utiliser le format BinData pour stocker les fichiers dans des documents uniques.
Ceci résume le fonctionnement de GridFS en général. Il est temps de plonger nos pieds dans du code fonctionnel et de voir comment mettre en œuvre un système en tant que tel.
Assez parlé, montrez-moi le code
Nous utilisons Node.js avec un accès à une instance cloud de MongoDB pour notre configuration. Vous pouvez trouver le dépôt de code pour l’application exemple ici.
 tarique93102GitHub
tarique93102GitHub 
Nous nous concentrerons complètement sur les segments du code qui concernent les fonctionnalités de GridFS. Nous allons apprendre à le configurer et à l’utiliser pour stocker des fichiers, récupérer des fichiers ou un fichier particulier, et supprimer un fichier particulier. Commençons alors.
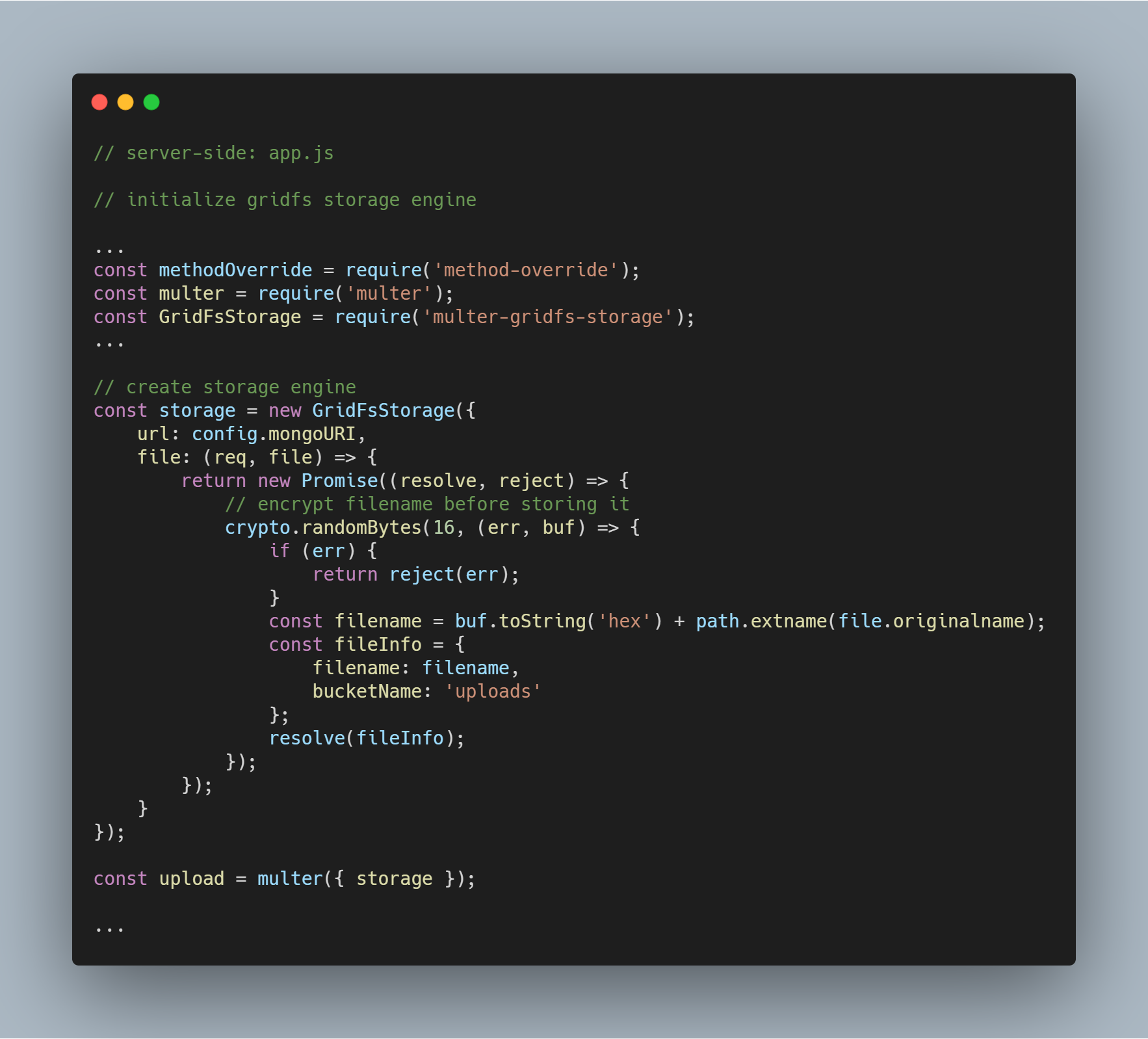
Initialiser le moteur de stockage
Les paquets nécessaires pour initialiser le moteur sont multer-gridfs-storage et multer. Nous utilisons également le middleware method-override pour activer l’opération de suppression des fichiers. Le module npm crypto est utilisé pour crypter les noms de fichiers lors de leur stockage et de leur lecture depuis la base de données.
Une fois que le moteur de stockage utilisant GridFS est initialisé, il suffit de l’appeler en utilisant le middleware multer. Il est ensuite passé à la route respective exécutant les diverses opérations de stockage de fichiers.
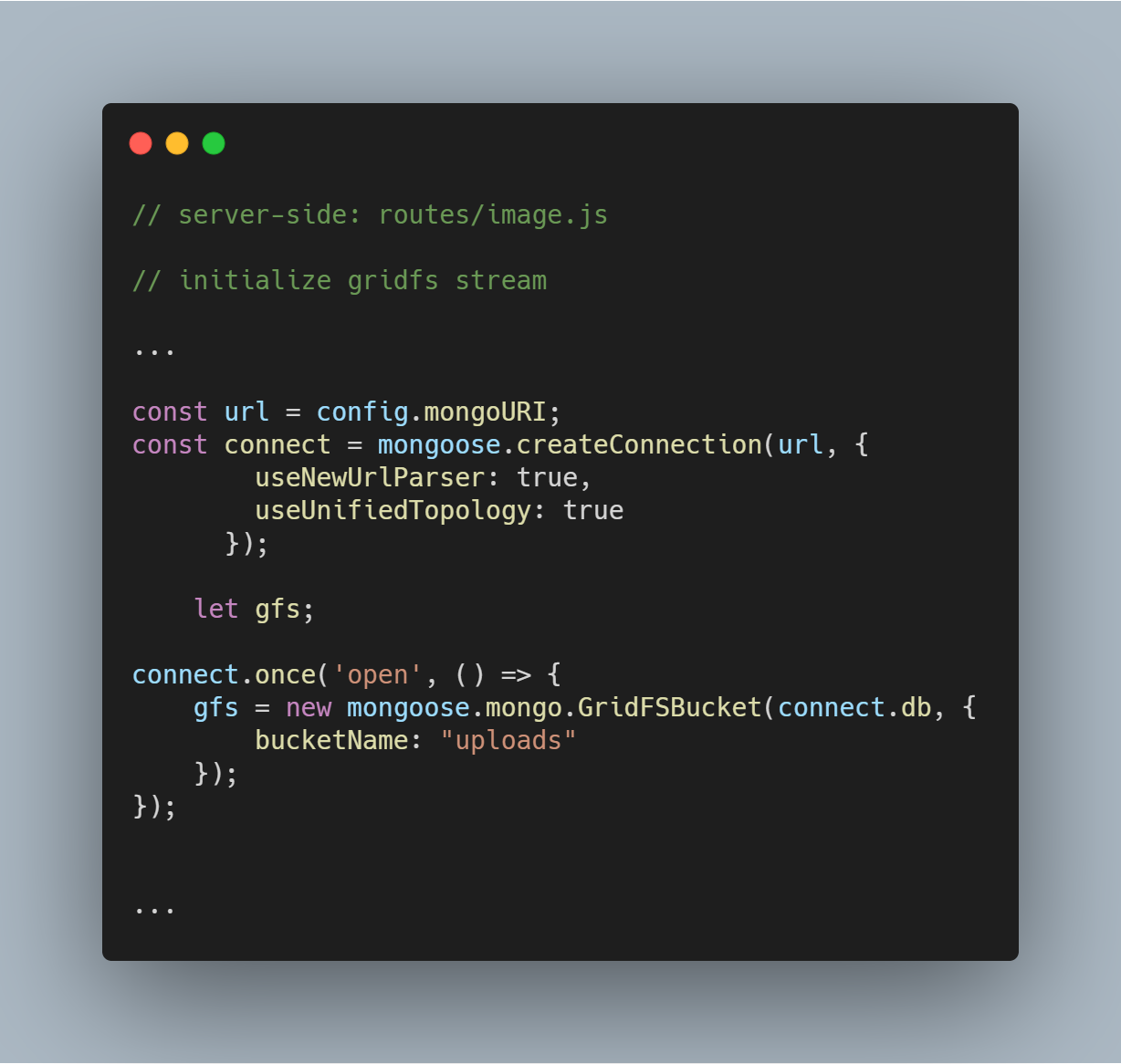
Initialiser le flux GridFS
Nous initialisons un flux GridFS comme vu dans le code ci-dessous. Le flux est nécessaire pour lire les fichiers de la base de données et aussi pour aider à rendre une image à un navigateur lorsque cela est nécessaire.
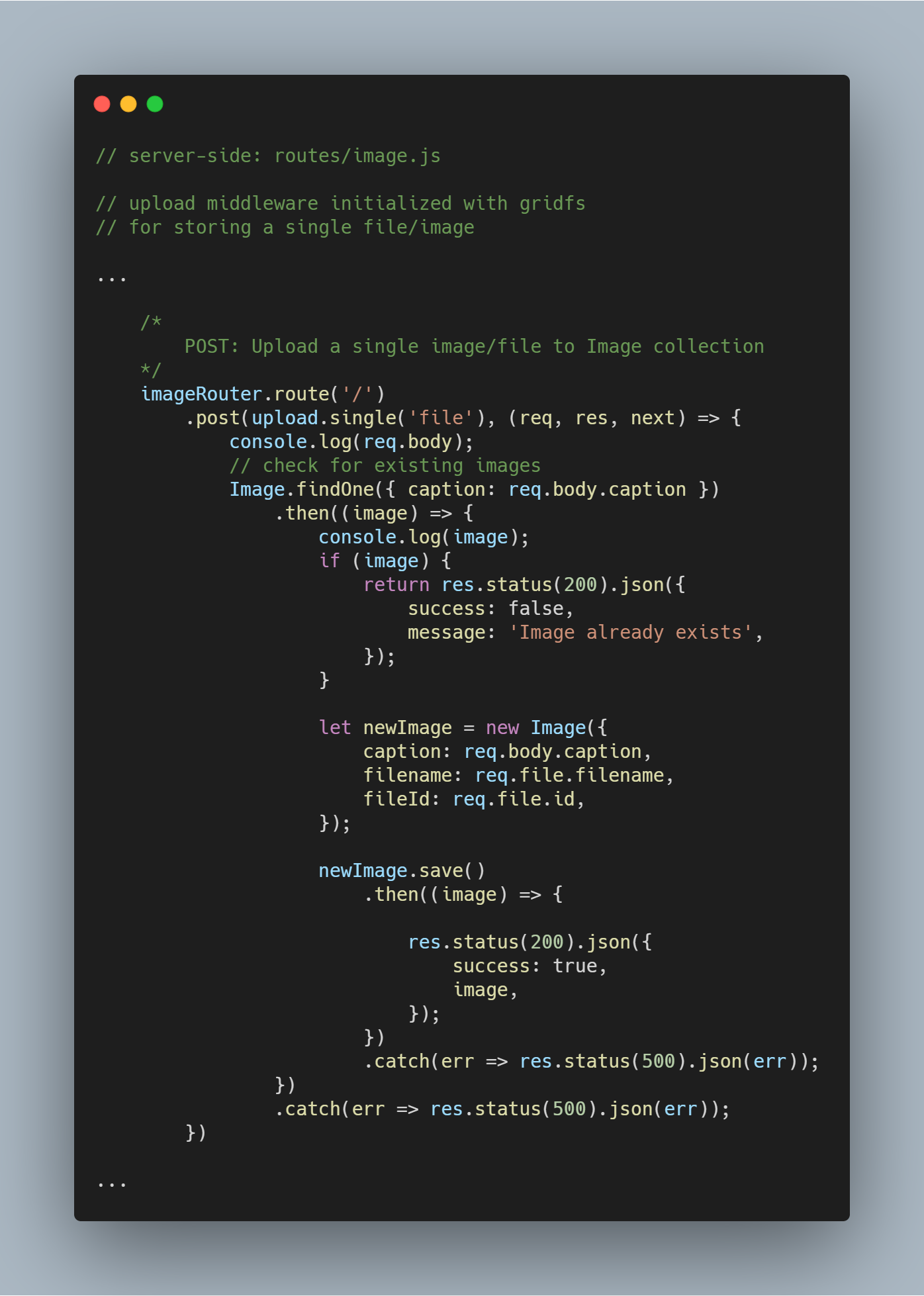
Transférer un seul fichier ou une seule image
Nous réutilisons le middleware de téléchargement que nous avions créé précédemment.
Note : Le nom file est utilisé comme paramètre dans upload.single() puisque nous avons la clé avec un nom similaire portant le fichier envoyé par le client.
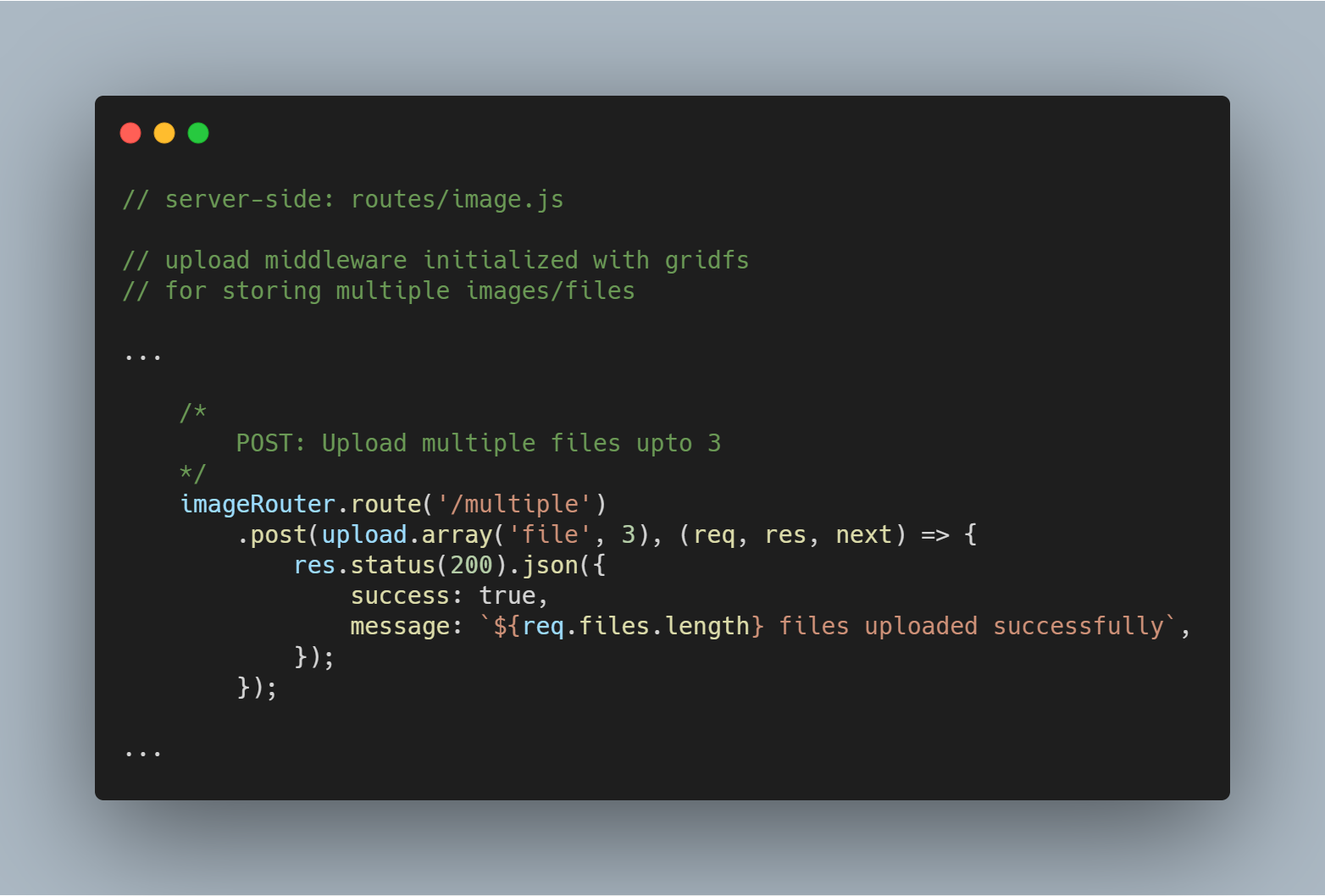
Télécharger plusieurs fichiers ou images
Nous pouvons également télécharger plusieurs fichiers à la fois. Au lieu de upload.single(), nous devons simplement utiliser upload.multiple(<number of files>).
Note : Le nombre de fichiers téléchargés peut être inférieur au nombre défini de fichiers.
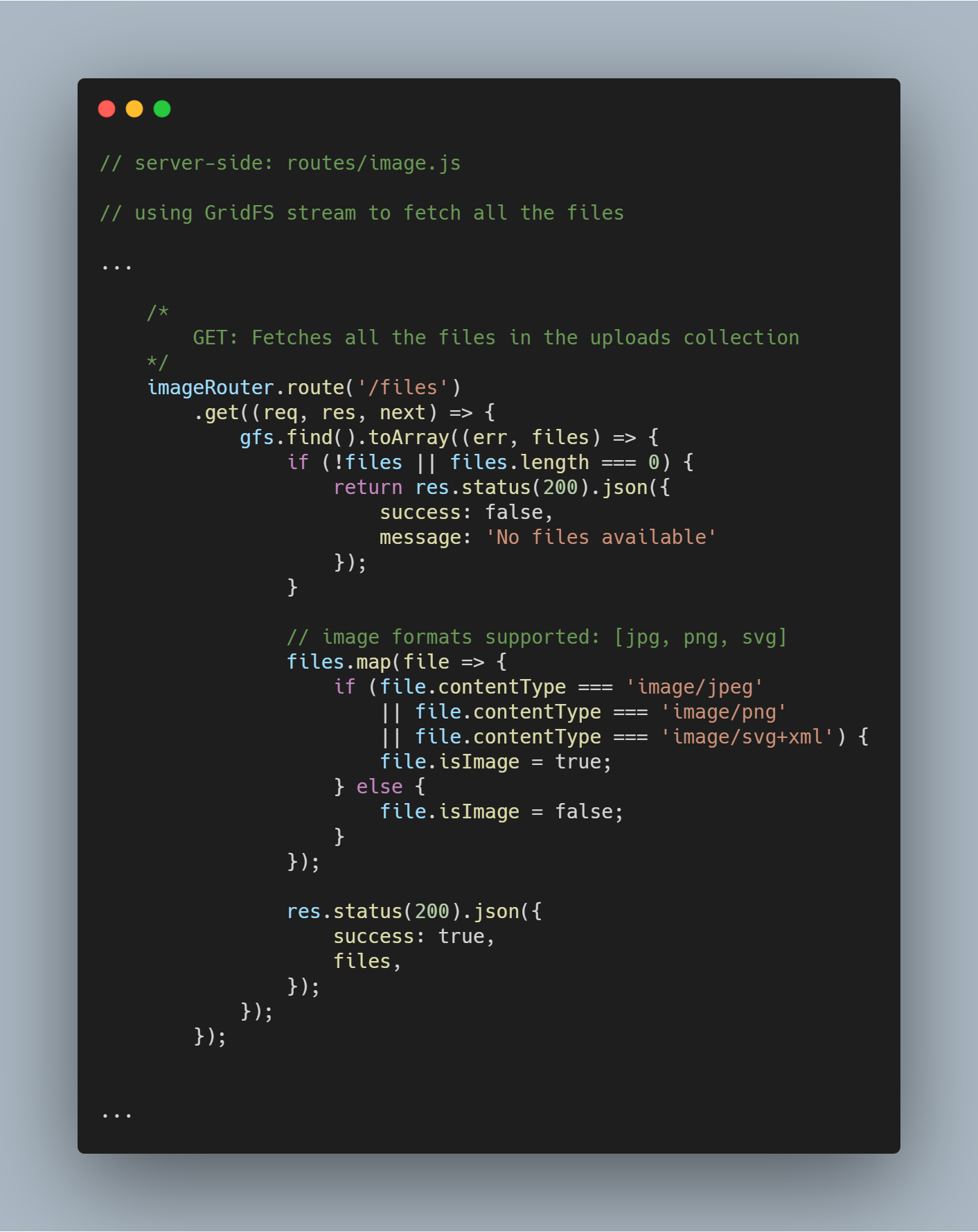
Récupérer tous les fichiers de la base de données
En utilisant le flux initialisé, nous pouvons récupérer tous les fichiers dans la base de données particulière en utilisant gfs.find().toArray(...). Une fois les fichiers obtenus, nous le mappons à un tableau et expédions la réponse.
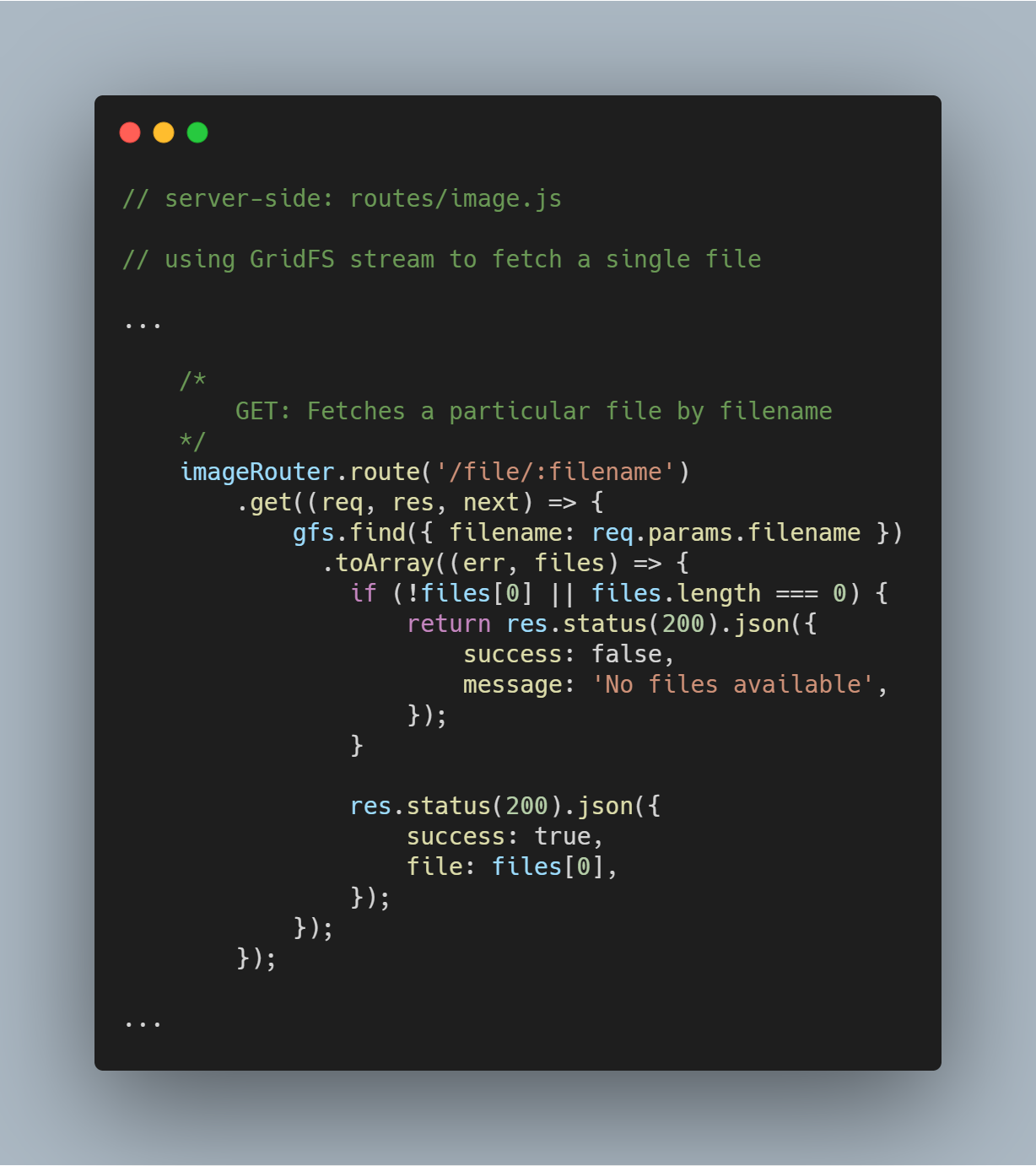
Fetch a Single File By Filename
Il est super simple d’interroger GridFS pour un fichier unique basé sur un attribut spécifique comme filename. En utilisant le flux GridFS, vous pouvez interroger la base de données à travers la fonction gfs.find({<add query here>}).
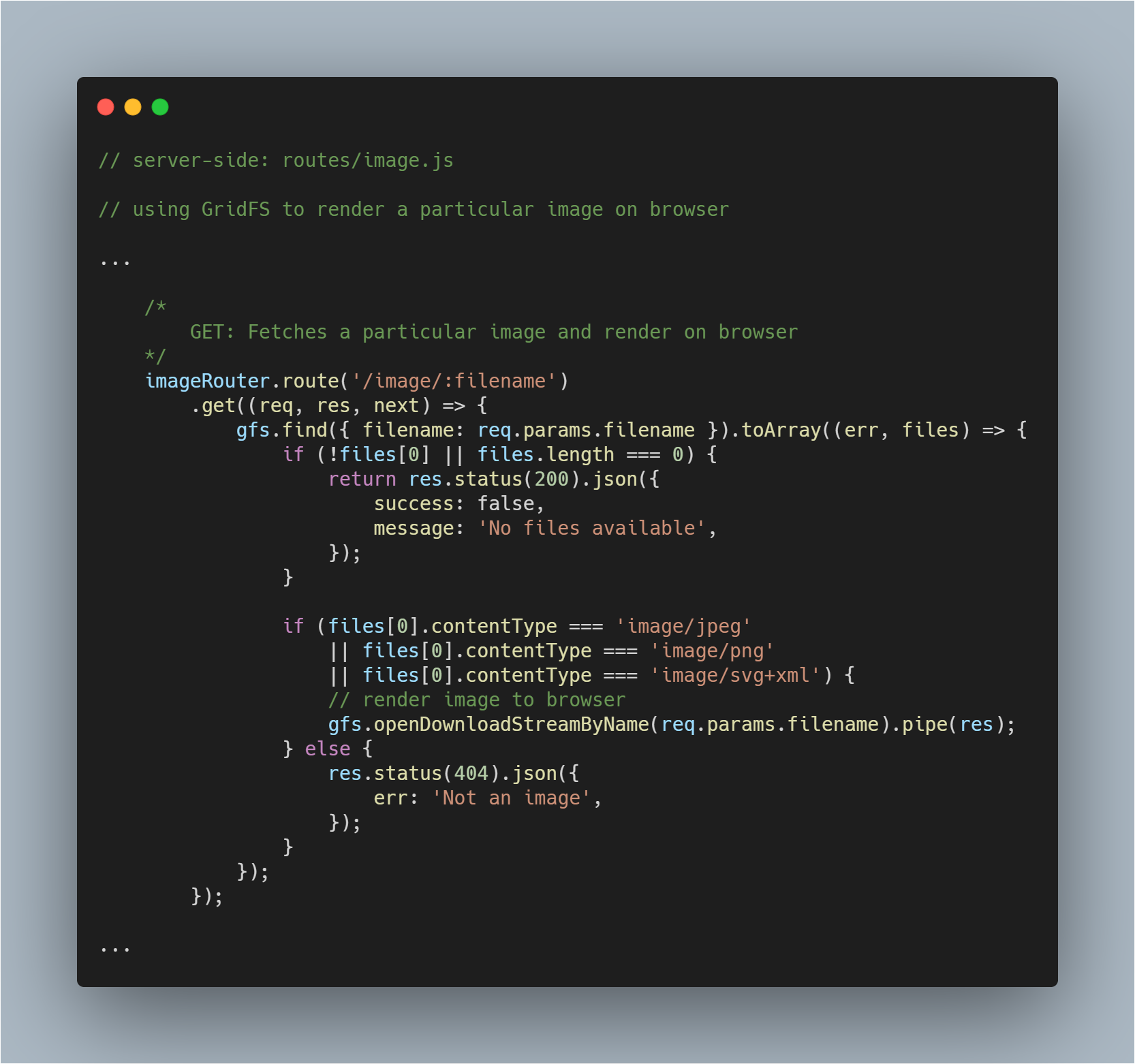
Rendre une image extraite au navigateur
C’est une partie un peu plus délicate puisque vous devez non seulement extraire un fichier de la base de données mais aussi le rendre en tant qu’image sur le navigateur respectif. Nous récupérons le fichier normalement. Aucun changement dans ce processus.
Puis avec l’aide de la méthode openDownloadStreamByName() sur gfs stream, nous pouvons facilement rendre une image car elle renvoie un flux lisible. Cela fait, nous pouvons utiliser la méthode pipe() de JavaScript pour streamer la réponse.
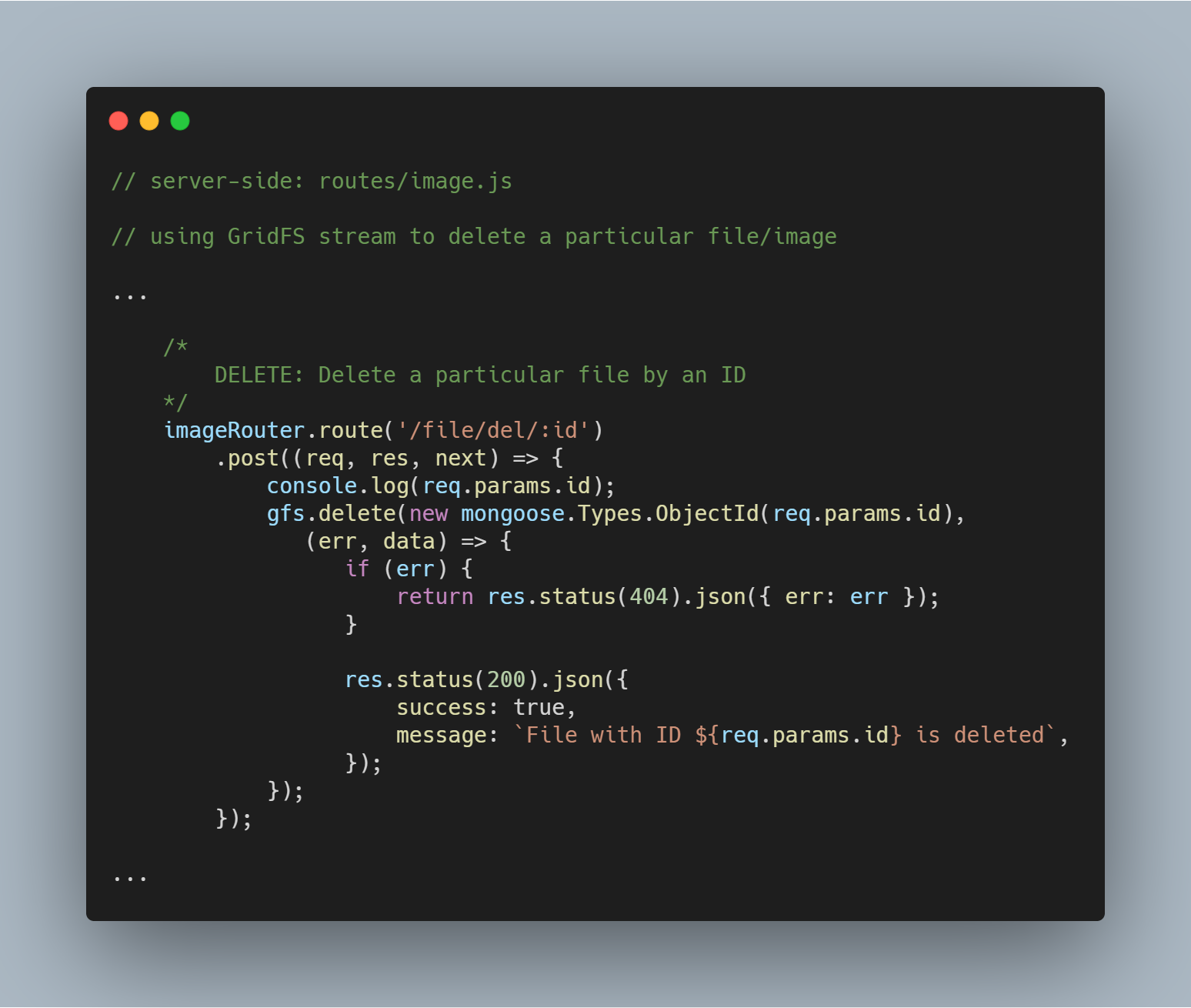
Supprimer un fichier particulier par Id
Supprimer un fichier est tout aussi simple. Nous utilisons la méthode stream delete() avec le paramètre _id pour interroger et supprimer le fichier concerné.
Ce sont les principales fonctionnalités offertes par la conception du moteur de stockage. J’avais exploité les fonctionnalités de GridFS discutées pour créer une application simple de téléchargement d’images. Vous pouvez approfondir le code dans le respository.
Conclusion
Il m’a fallu un certain temps et une quantité décente de lutte pour comprendre comment faire usage de GridFS pour un projet personnel. À cause de cela, je voulais m’assurer qu’au moins une autre personne n’avait pas à investir la même quantité de temps.
Ayant dit cela, je recommanderais d’utiliser GridFS avec prudence. Ce n’est pas une solution miracle à tous vos problèmes de stockage de fichiers. Pourtant, c’est une spécification nifty à connaître et à être conscient.