Por Derrick Mwiti, analista de datos

Nota del editor: Este tutorial ilustra cómo empezar a predecir series temporales con modelos LSTM. Los datos del mercado de valores son una gran elección para esto porque son bastante regulares y están ampliamente disponibles para todos. Por favor, no tomes esto como un consejo financiero o lo utilices para hacer tus propias operaciones.
En este tutorial, vamos a construir un modelo de aprendizaje profundo en Python que predecirá el comportamiento futuro de los precios de las acciones. Asumimos que el lector está familiarizado con los conceptos de aprendizaje profundo en Python, especialmente con la memoria a largo plazo.
Si bien predecir el precio real de una acción es una cuesta arriba, podemos construir un modelo que prediga si el precio subirá o bajará. Los datos y el cuaderno utilizados para este tutorial se pueden encontrar aquí. Es importante señalar que siempre hay otros factores que afectan a los precios de las acciones, como el ambiente político y el mercado. Sin embargo, no nos centraremos en esos factores para este tutorial.
Introducción
LSTMs son muy potentes en problemas de predicción de secuencias porque son capaces de almacenar información pasada. Esto es importante en nuestro caso porque el precio anterior de una acción es crucial para predecir su precio futuro.
Empezaremos importando NumPy para el cálculo científico, Matplotlib para trazar gráficos y Pandas para ayudar a cargar y manipular nuestros conjuntos de datos.
Carga del conjunto de datos
El siguiente paso es cargar nuestro conjunto de datos de entrenamiento y seleccionar las columnas Open y High que utilizaremos en nuestro modelado.
Revisamos la cabecera de nuestro conjunto de datos para darnos una idea del tipo de conjunto de datos con el que estamos trabajando.
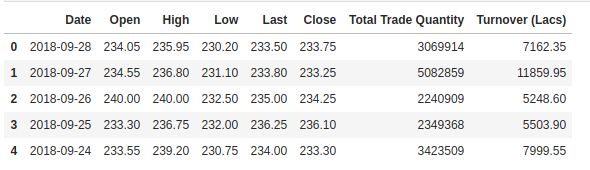
La columna Open es el precio inicial mientras que la columna Close es el precio final de una acción en un día de negociación concreto. Las columnas High y Low representan los precios más altos y más bajos de un determinado día.
Escalado de características
Desde la experiencia previa con modelos de aprendizaje profundo, sabemos que tenemos que escalar nuestros datos para obtener un rendimiento óptimo. En nuestro caso, utilizaremos MinMaxScaler de Scikit- Learn y escalaremos nuestro conjunto de datos a números entre cero y uno.
Creación de datos con Timesteps
LSTMs esperan que nuestros datos estén en un formato específico, normalmente un array 3D. Comenzamos creando los datos en 60 timesteps y convirtiéndolos en un array usando NumPy. A continuación, convertimos los datos en un array de dimensión 3D con X_train muestras, 60 marcas de tiempo y una característica en cada paso.
Construyendo el LSTM
Para construir el LSTM, necesitamos importar un par de módulos de Keras:
-
Sequentialpara inicializar la red neuronal -
Densepara añadir una capa de red neuronal densamente conectada -
LSTMpara añadir la capa de Memoria Larga a Corto Plazo -
Dropoutpara añadir capas de abandono que eviten el overfitting
Añadimos la capa LSTM y posteriormente añadimos unas cuantas capas Dropout para evitar el overfitting. Añadimos la capa LSTM con los siguientes argumentos:
- 50 unidades que es la dimensionalidad del espacio de salida
-
return_sequences=Trueque determina si se devuelve la última salida en la secuencia de salida, o la secuencia completa -
input_shapecomo la forma de nuestro conjunto de entrenamiento.
Al definir las capas Dropout, especificamos 0,2, lo que significa que el 20% de las capas se eliminarán. A continuación, añadimos la capa Dense que especifica la salida de 1 unidad. Después de esto, compilamos nuestro modelo utilizando el popular optimizador adam y establecemos la pérdida como mean_squarred_error. Esto calculará la media de los errores al cuadrado. A continuación, ajustamos el modelo para que se ejecute en 100 épocas con un tamaño de lote de 32. Tenga en cuenta que, dependiendo de las especificaciones de su ordenador, esto podría tomar unos minutos para terminar de ejecutar.
Predicción de acciones futuras utilizando el conjunto de prueba
Primero tenemos que importar el conjunto de prueba que vamos a utilizar para hacer nuestras predicciones en.
Para predecir los precios futuros de las acciones necesitamos hacer un par de cosas después de cargar el conjunto de prueba:
- Fusionar el conjunto de entrenamiento y el conjunto de prueba en el eje 0.
- Configurar el paso de tiempo en 60 (como se ha visto anteriormente)
- Utilizar
MinMaxScalerpara transformar el nuevo conjunto de datos - Dar forma al conjunto de datos como se ha hecho anteriormente
Después de hacer las predicciones utilizamos inverse_transformpara recuperar los precios de las acciones en formato legible normal.
Planificación de los resultados
Por último, utilizamos Matplotlib para visualizar el resultado del precio de las acciones predicho y el precio de las acciones reales.
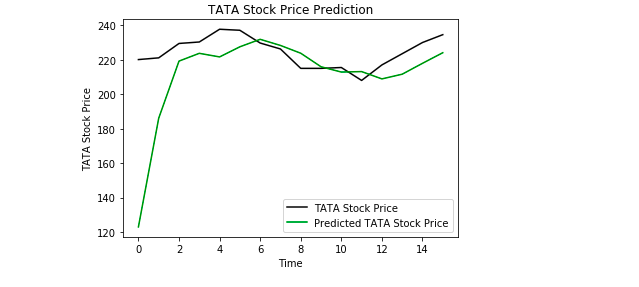
Del gráfico podemos ver que el precio de las acciones reales subió mientras que nuestro modelo también predijo que el precio de las acciones subiría. Esto muestra claramente lo potentes que son las LSTM para analizar series temporales y datos secuenciales.
Conclusión
Hay un par de técnicas más de predicción de los precios de las acciones, como las medias móviles, la regresión lineal, K-Nearest Neighbours, ARIMA y Prophet. Estas son técnicas que uno puede probar por sí mismo y comparar su rendimiento con el LSTM de Keras. Si quieres aprender más sobre Keras y el aprendizaje profundo puedes encontrar mis artículos al respecto aquí y aquí.
Discute este post en Reddit y Hacker News.
Bio: Derrick Mwiti es un analista de datos, un escritor y un mentor. Le motiva ofrecer grandes resultados en cada tarea, y es mentor en Lapid Leaders Africa.
Original. Reposted with permission.
Related:
- Introducción al Aprendizaje Profundo con Keras
- Introducción a PyTorch para el Aprendizaje Profundo
- The Keras 4 Step Workflow