El almacenamiento de archivos es una característica importante requerida en múltiples procesos a través de varios tipos de aplicaciones. La existencia de procesos como Content Delivery Networks (CDNs), establecidos a través de opciones de terceros en la nube como Amazon Web Services, y las opciones de almacenamiento de archivos locales siempre han facilitado la construcción de dicha característica.
Sin embargo, el concepto de almacenar archivos directamente en una base de datos a través de una única llamada a la API me había intrigado durante bastante tiempo. Ahí es donde GridFS entró en escena para mí.

GridFS – A Layman’s Understanding
MongoDB tiene una especificación de controlador para cargar y recuperar archivos de él llamado GridFS. GridFS permite almacenar y recuperar archivos, lo que incluye aquellos que exceden el límite de tamaño de los documentos BSON de 16 MB.
GridFS básicamente toma un archivo y lo divide en múltiples trozos que se almacenan como documentos individuales en dos colecciones:
- la colección
chunk(almacena las partes del documento), y - la colección
file(almacena los consiguientes metadatos adicionales).
Cada trozo está limitado a 255 KB de tamaño. Esto significa que el último chunk es normalmente igual o inferior a 255 KB. Suena bastante bien.
Cuando se lee desde GridFS, el controlador reensambla todos los chunks según sea necesario. Esto significa que usted puede leer secciones de un archivo según su rango de consulta. Por ejemplo, escuchar un segmento de un archivo de audio o recuperar una sección de un archivo de vídeo.
Nota: Es preferible utilizar GridFS para almacenar archivos que normalmente superan el límite de tamaño de 16 MB. Para archivos más pequeños, se recomienda utilizar el formato BinData para almacenar los archivos en documentos individuales.
Esto resume cómo funciona GridFS en general. Es hora de sumergir nuestros pies en algún código de trabajo y ver cómo implementar un sistema como tal.
Basta de hablar, muéstrame el código
Estamos usando Node.js con acceso a una instancia en la nube de MongoDB para nuestra configuración. Puedes encontrar el repositorio de código para la aplicación de ejemplo aquí.
 tarique93102GitHub
tarique93102GitHub 
Nos centraremos completamente en los segmentos del código que se relacionan con las funcionalidades de GridFS. Aprenderemos a configurarlo y a utilizarlo para almacenar archivos, recuperar archivos o un archivo en particular y eliminar un archivo en particular. Empecemos entonces.
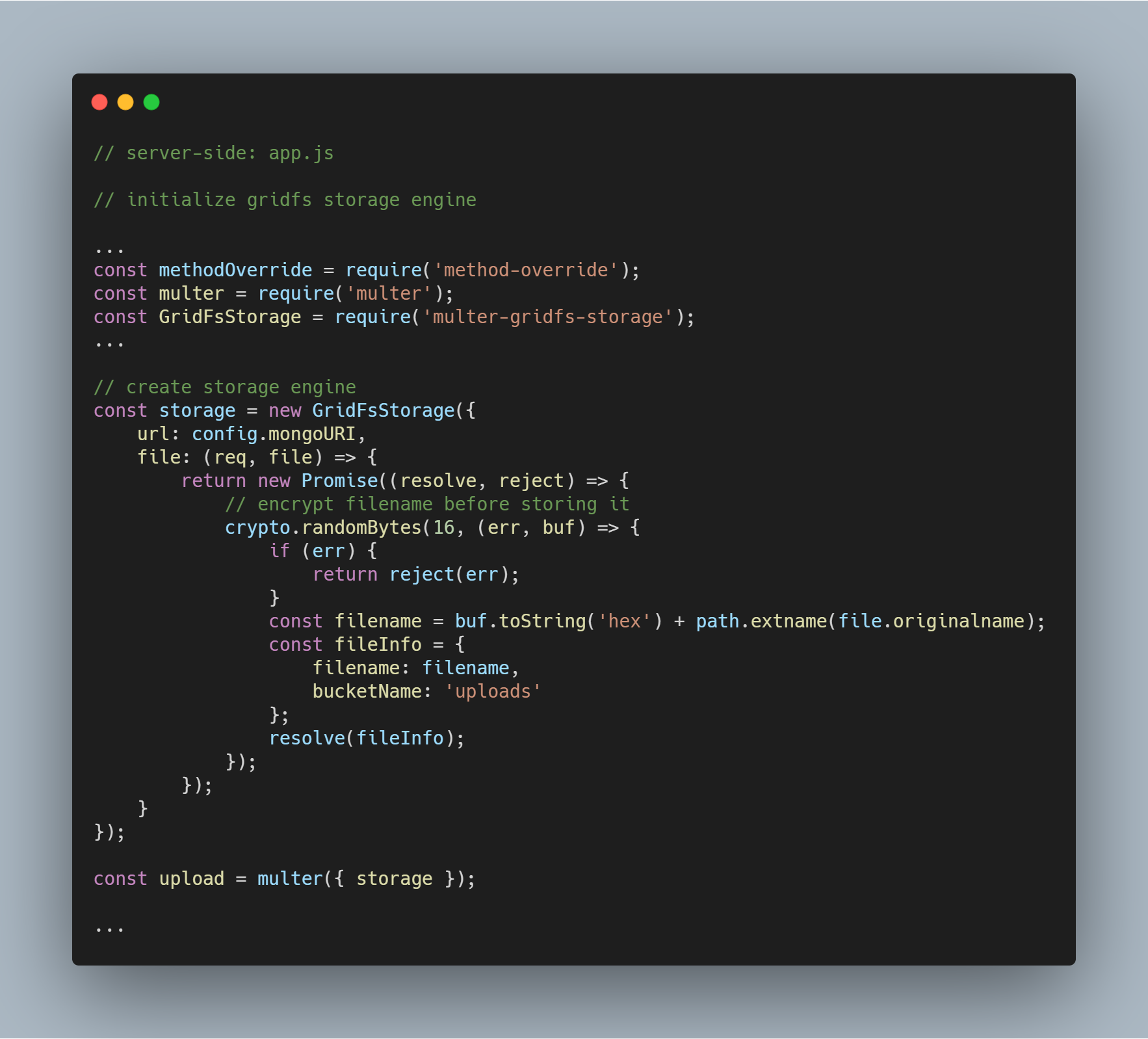
Inicializar el motor de almacenamiento
Los paquetes necesarios para inicializar el motor son multer-gridfs-storage y multer. También utilizamos el middleware method-override para habilitar la operación de borrado de archivos. El módulo npm crypto se utiliza para encriptar los nombres de los archivos al ser almacenados y leídos desde la base de datos.
Una vez inicializado el motor de almacenamiento que utiliza GridFS, sólo hay que llamarlo utilizando el middleware multer. Luego se pasa a la ruta respectiva que ejecuta las diversas operaciones de almacenamiento de archivos.
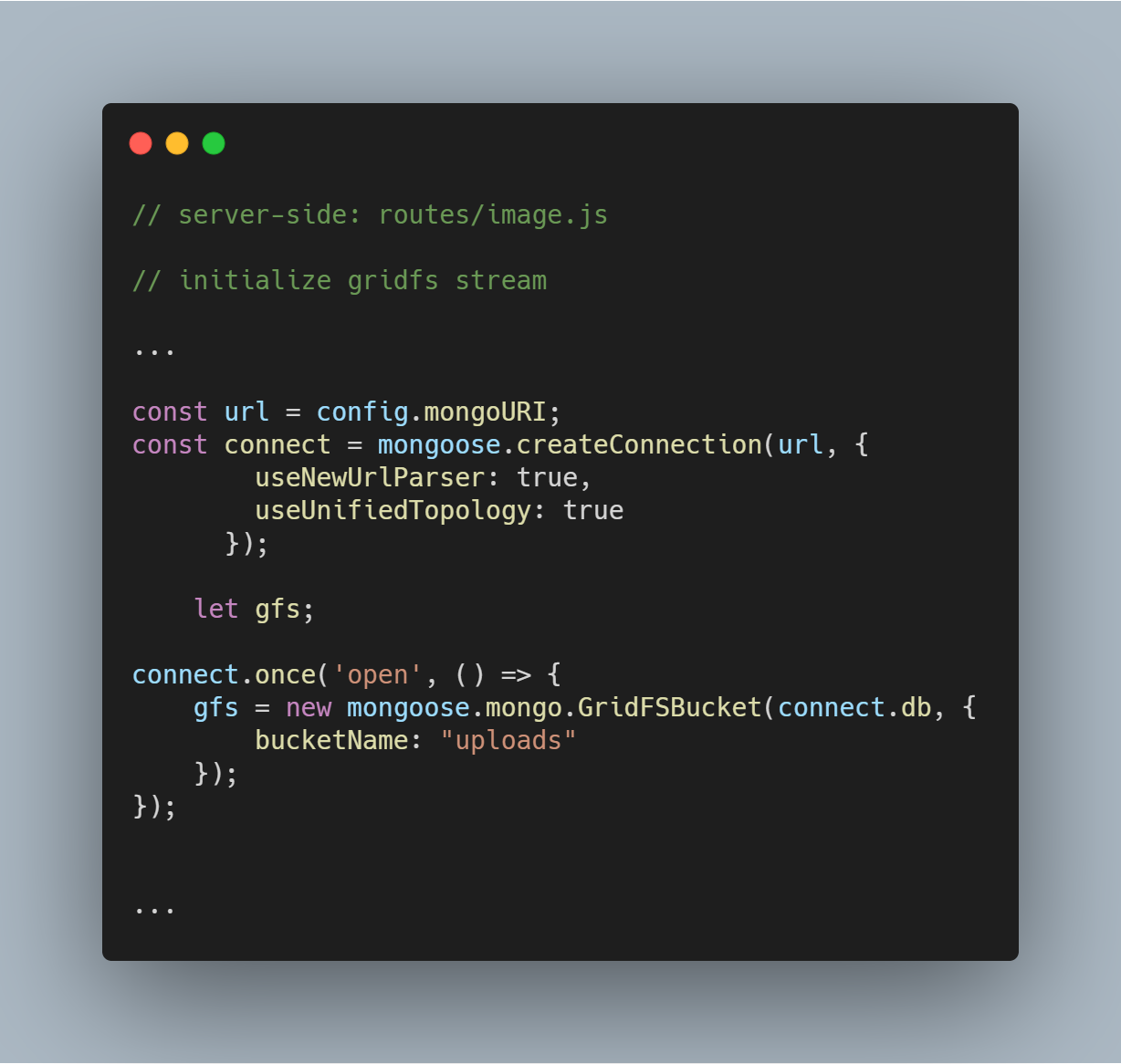
Inicializar GridFS Stream
Inicializamos un stream de GridFS como se ve en el código siguiente. El stream es necesario para leer los archivos de la base de datos y también para ayudar a renderizar una imagen a un navegador cuando sea necesario.
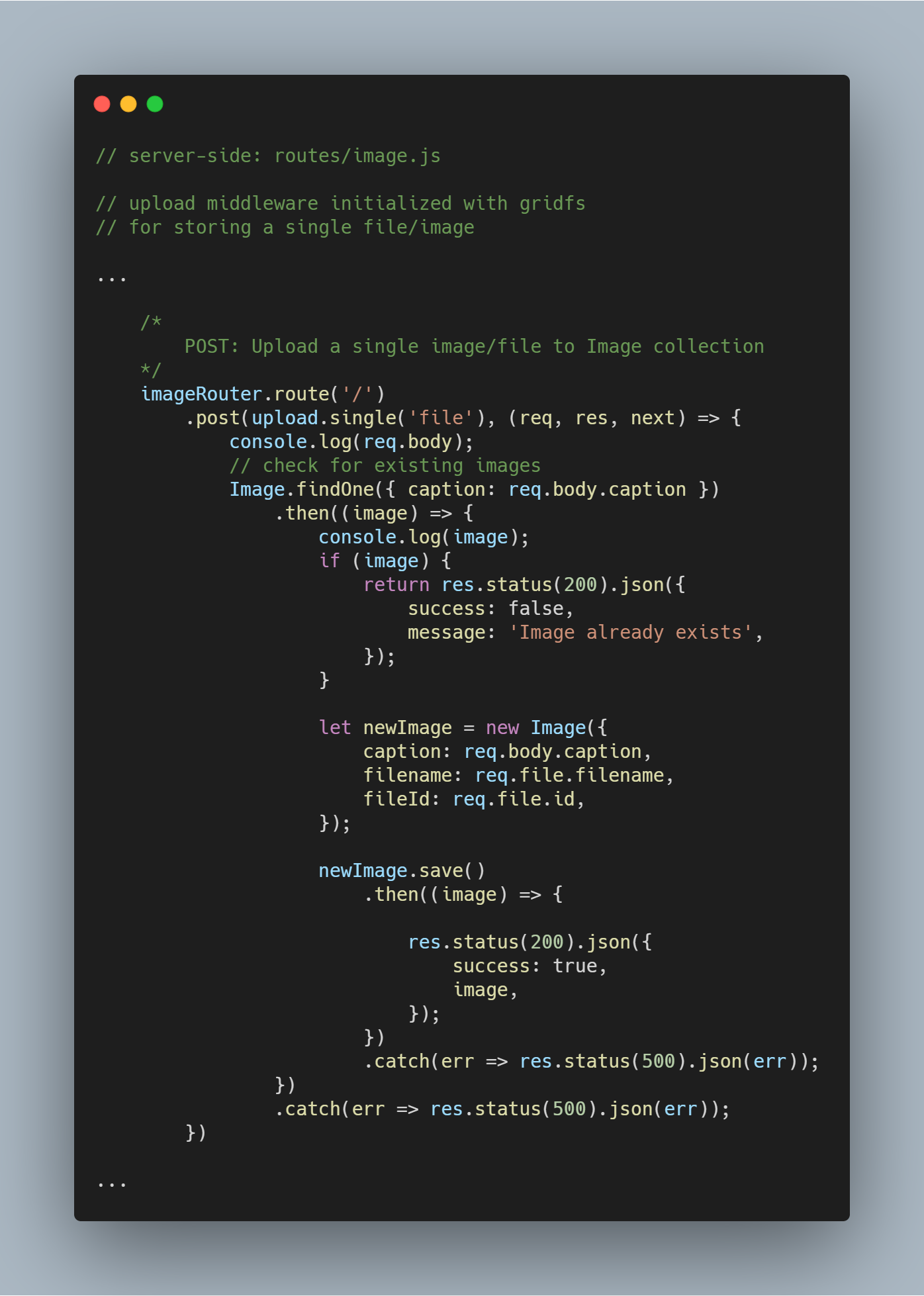
Subir un solo archivo o imagen
Reutilizamos el middleware de subida que habíamos creado anteriormente.
Nota: El nombre file se utiliza como parámetro en upload.single() ya que tenemos la clave con un nombre similar que lleva el archivo que se envía desde el cliente.
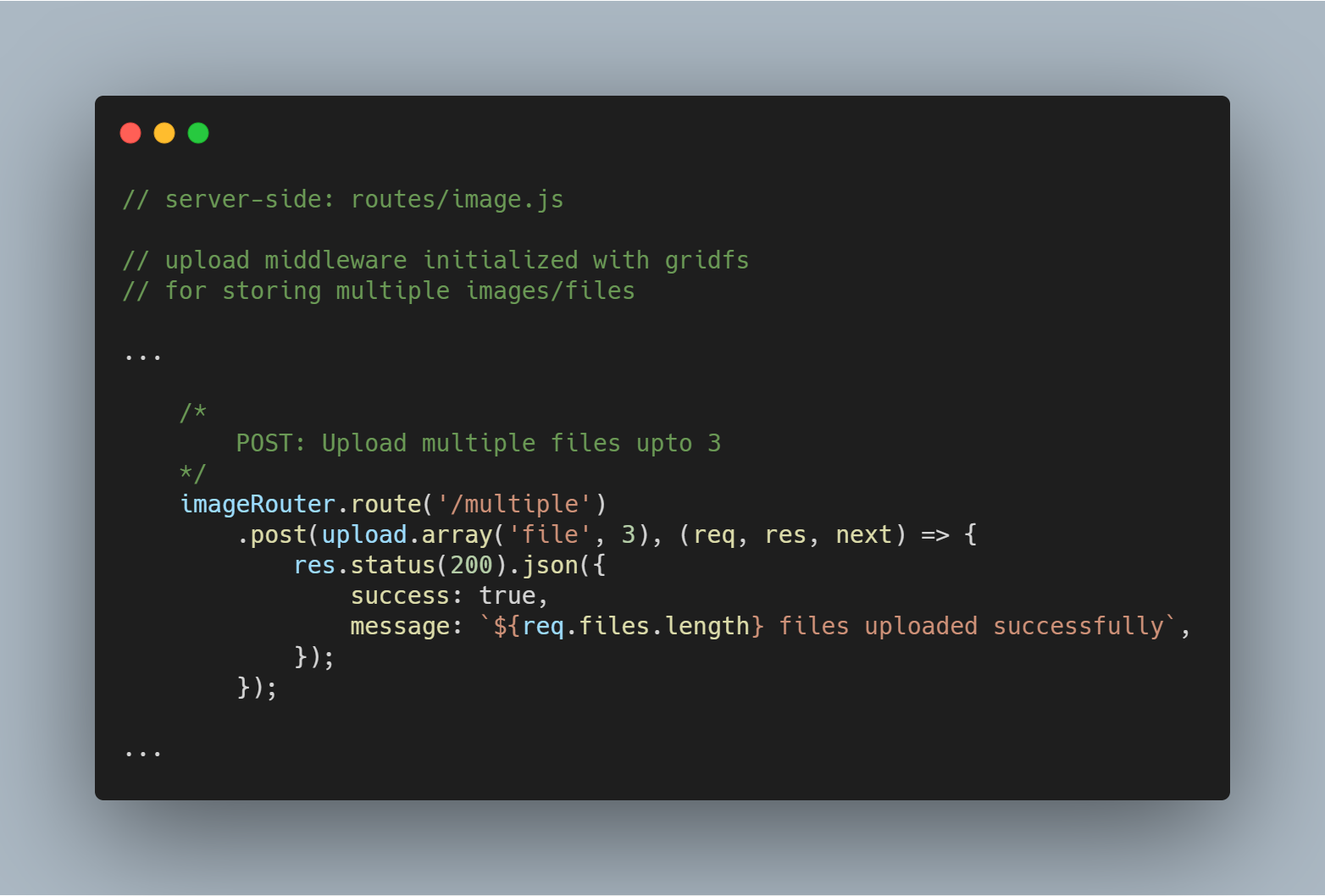
Subir varios archivos o imágenes
También podemos subir varios archivos a la vez. En lugar de upload.single(), tenemos que utilizar simplemente upload.multiple(<number of files>).
Nota: El número de archivos subidos puede ser menor que el número de archivos definido.
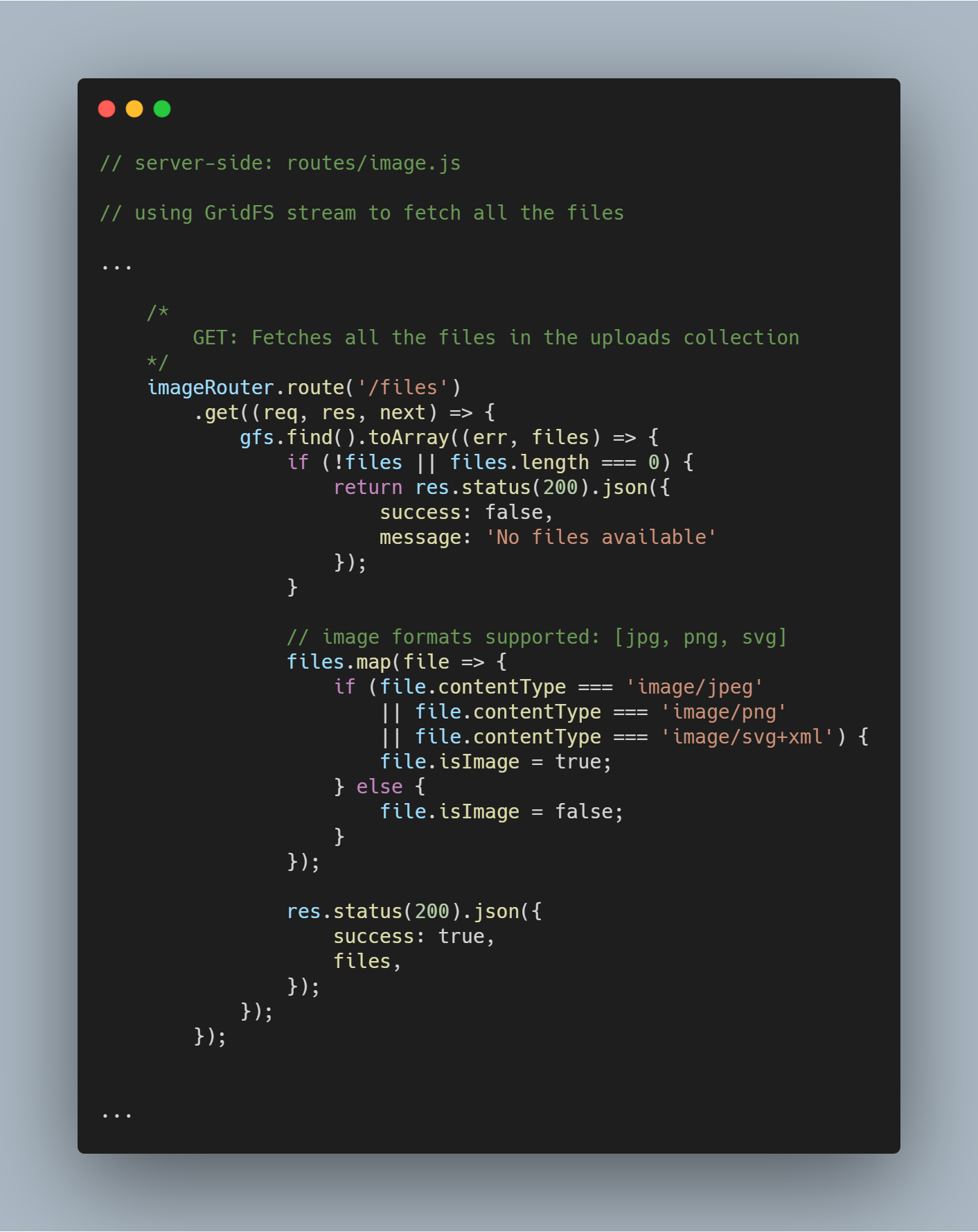
Obtener todos los archivos de la base de datos
Usando el flujo inicializado podemos obtener todos los archivos de la base de datos particular usando gfs.find().toArray(...). Una vez obtenidos los archivos los mapeamos a un array y enviamos la respuesta.
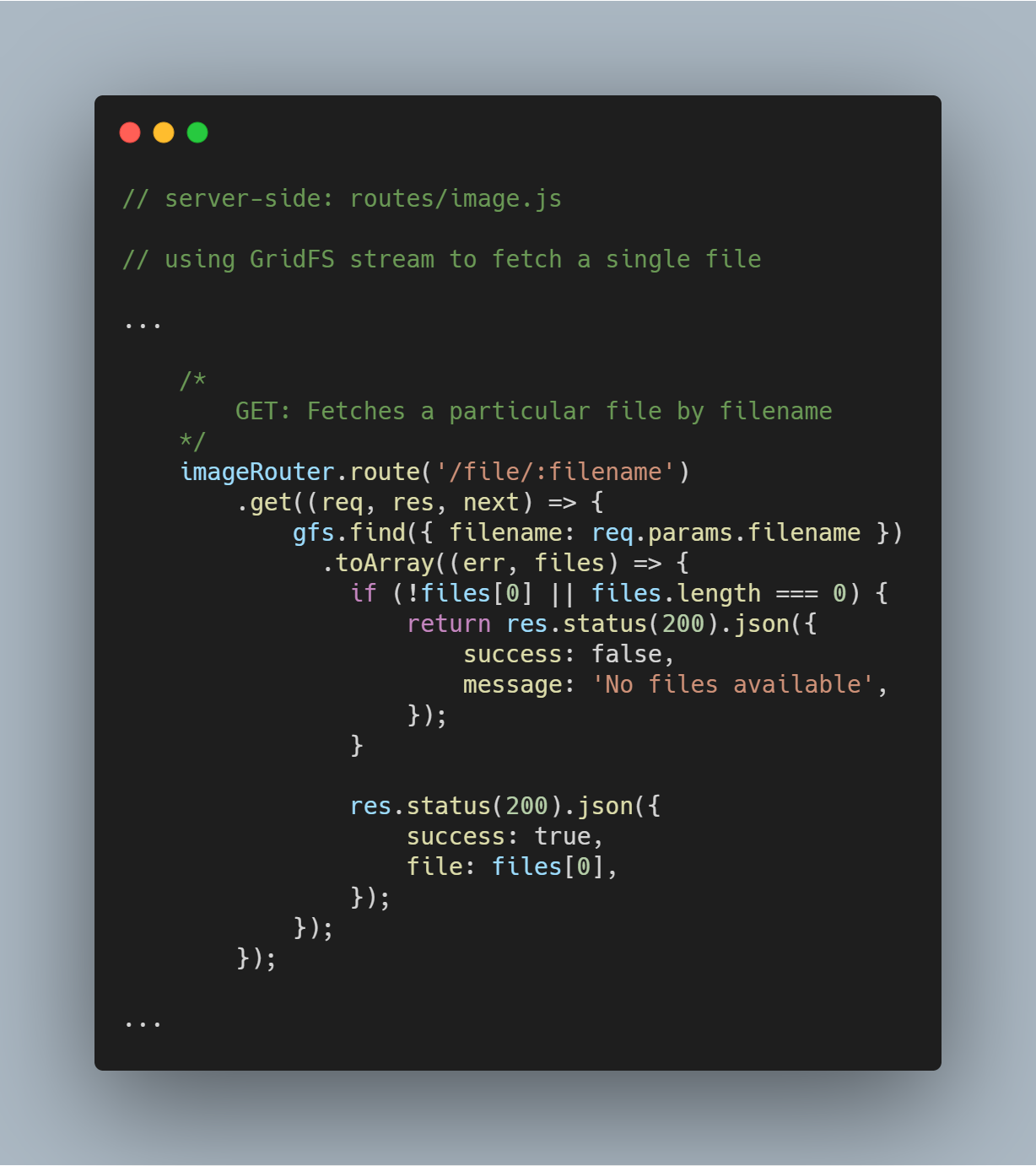
Fetch a Single File By Filename
Es súper sencillo consultar GridFS por un solo archivo basado en un atributo específico como filename. Usando el flujo de GridFS, puedes consultar la base de datos a través de la función gfs.find({<add query here>}).
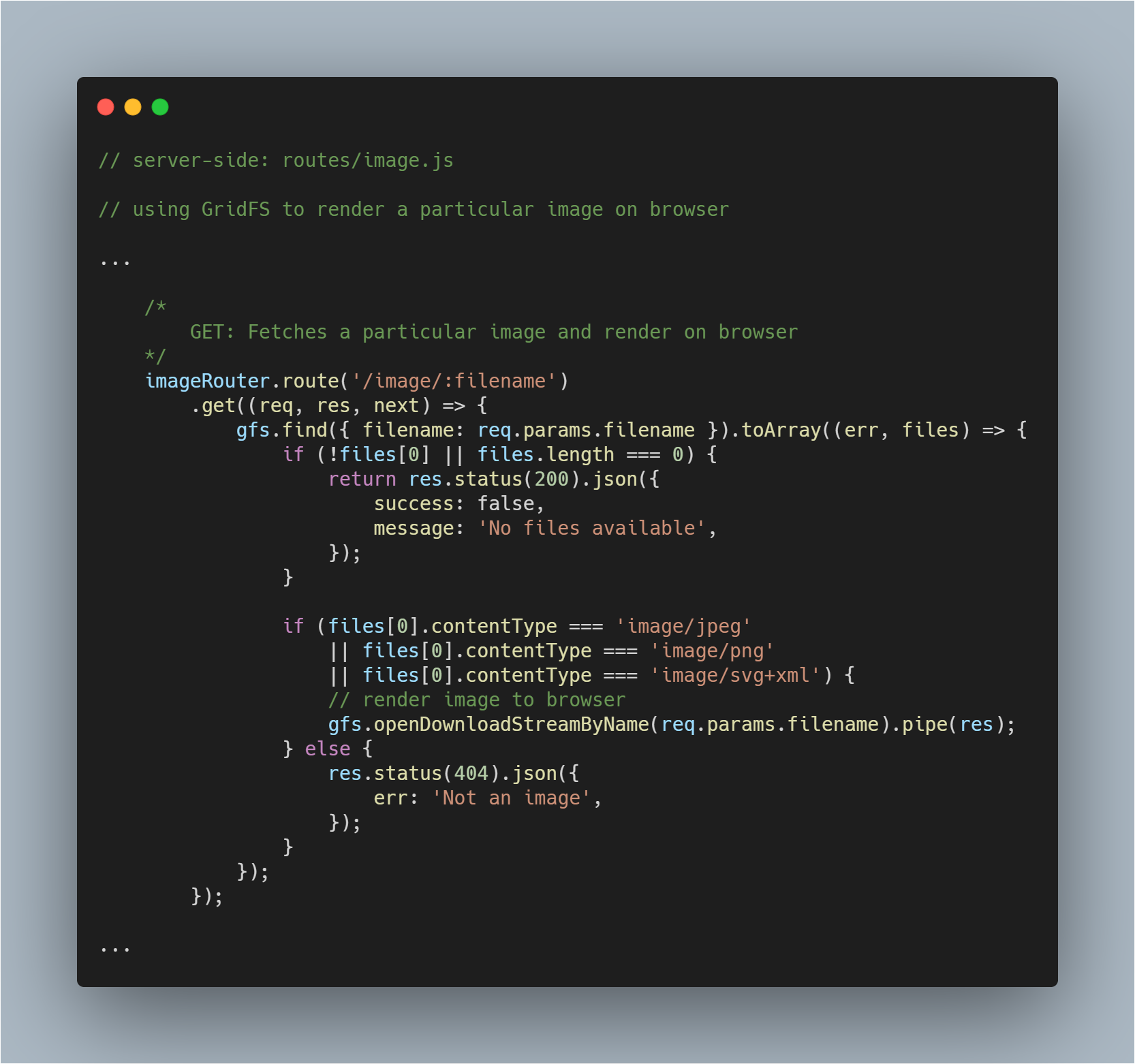
Renderizar una imagen obtenida en el navegador
Esta es una parte un poco más complicada ya que no sólo tienes que obtener un archivo de la base de datos sino también renderizarlo como una imagen en el navegador respectivo. Obtenemos el archivo normalmente. No hay cambios en ese proceso.
Entonces, con la ayuda del método openDownloadStreamByName() en gfs stream, podemos fácilmente renderizar una imagen ya que devuelve un stream legible. Una vez hecho esto, podemos utilizar el método pipe() de JavaScript para transmitir la respuesta.
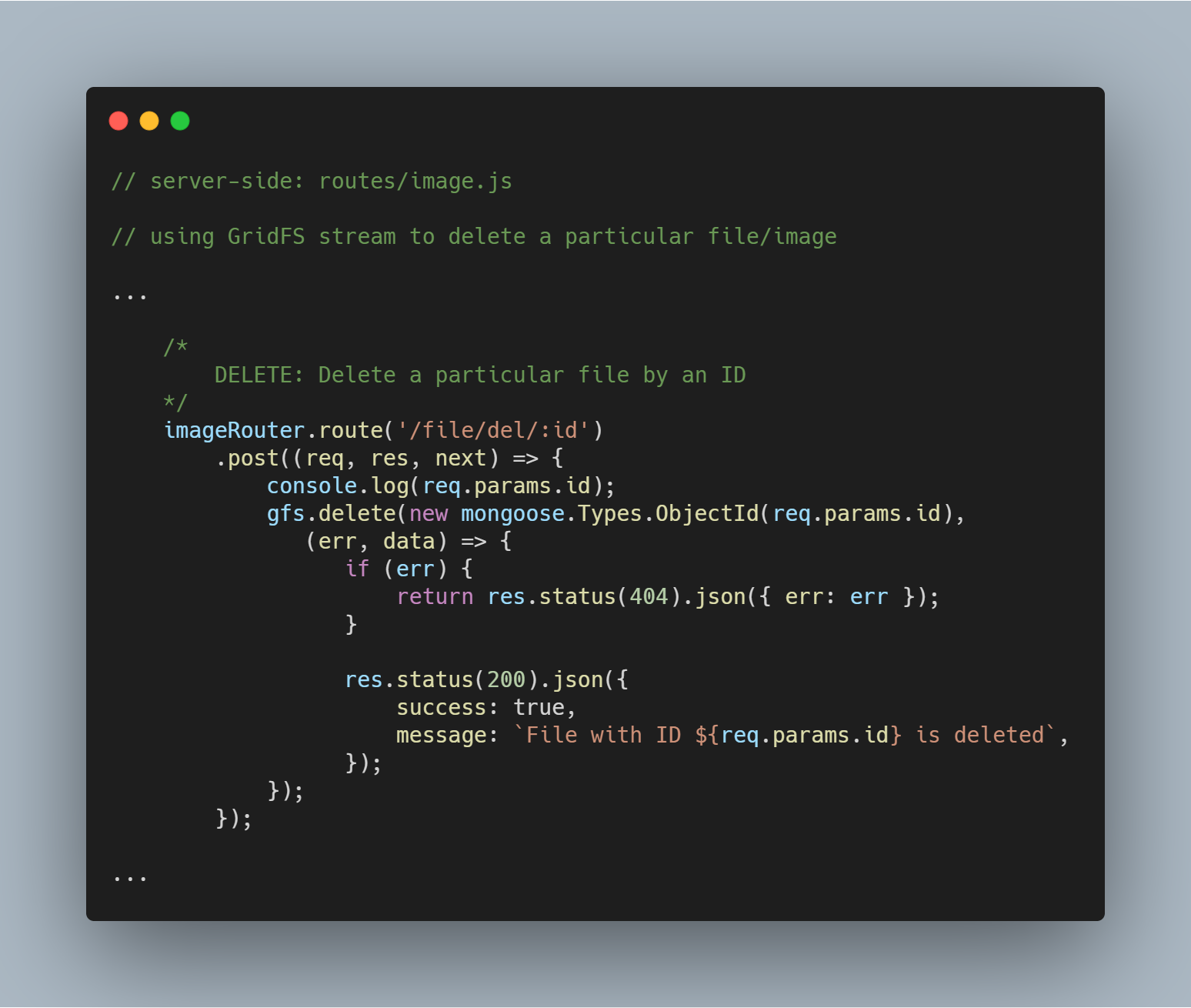
Borrar un archivo particular por Id
Borrar un archivo es igualmente sencillo. Utilizamos el método stream delete() con el parámetro _id para consultar y eliminar el archivo en cuestión.
Estas son las principales funcionalidades que ofrece el diseño del motor de almacenamiento. He aprovechado las funcionalidades de GridFS comentadas para crear una sencilla aplicación de subida de imágenes. Puedes profundizar en el código en el respositorio.
Conclusión
Me llevó algún tiempo y una cantidad decente de lucha entender cómo hacer uso de GridFS para un proyecto personal. Debido a esto, quería asegurarme de que al menos otra persona no tuviera que invertir la misma cantidad de tiempo.
Habiendo dicho esto, recomendaría usar GridFS con precaución. No es una bala de plata para todas sus preocupaciones de almacenamiento de archivos. Sin embargo, es una especificación ingeniosa para conocer y ser consciente de.