Von Derrick Mwiti, Datenanalyst

Anmerkung des Herausgebers: Dieses Tutorial zeigt, wie man mit LSTM-Modellen Zeitreihen vorhersagen kann. Börsendaten eignen sich hervorragend dafür, da sie ziemlich regelmäßig und für jedermann zugänglich sind. Bitte verstehen Sie dies nicht als Finanzberatung und nutzen Sie es nicht, um eigene Geschäfte zu machen.
In diesem Tutorial werden wir ein Python Deep Learning-Modell erstellen, das das zukünftige Verhalten von Aktienkursen vorhersagt. Wir gehen davon aus, dass der Leser mit den Konzepten des Deep Learning in Python vertraut ist, insbesondere mit dem Long Short-Term Memory.
Während die Vorhersage des tatsächlichen Kurses einer Aktie ein schwieriges Unterfangen ist, können wir ein Modell erstellen, das vorhersagt, ob der Kurs steigen oder fallen wird. Die Daten und das Notebook, die für dieses Tutorial verwendet wurden, finden Sie hier. Es ist wichtig zu wissen, dass es immer auch andere Faktoren gibt, die die Aktienkurse beeinflussen, wie z. B. die politische Atmosphäre und der Markt. In diesem Tutorium werden wir uns jedoch nicht auf diese Faktoren konzentrieren.
Einführung
LSTMs sind bei Sequenzvorhersageproblemen sehr leistungsfähig, da sie in der Lage sind, Informationen aus der Vergangenheit zu speichern. Das ist in unserem Fall wichtig, weil der frühere Preis einer Aktie entscheidend für die Vorhersage ihres zukünftigen Preises ist.
Wir beginnen mit dem Import von NumPy für wissenschaftliche Berechnungen, Matplotlib für das Plotten von Diagrammen und Pandas, um das Laden und Bearbeiten unserer Datensätze zu unterstützen.
Laden des Datensatzes
Der nächste Schritt besteht darin, unseren Trainingsdatensatz zu laden und die Open und HighSpalten auszuwählen, die wir für unsere Modellierung verwenden werden.
Wir überprüfen den Kopf unseres Datensatzes, um einen Einblick in die Art des Datensatzes zu erhalten, mit dem wir arbeiten.
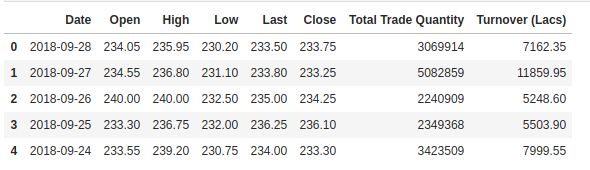
Die Spalte Open ist der Anfangskurs, während die Spalte Close der Endkurs einer Aktie an einem bestimmten Handelstag ist. Die Spalten High und Low stellen den höchsten und den niedrigsten Preis für einen bestimmten Tag dar.
Feature Scaling
Aus früheren Erfahrungen mit Deep-Learning-Modellen wissen wir, dass wir unsere Daten für eine optimale Leistung skalieren müssen. In unserem Fall verwenden wir das MinMaxScaler von Scikit-Learn und skalieren unseren Datensatz auf Zahlen zwischen null und eins.
Datenerstellung mit Zeitschritten
LSTMs erwarten, dass unsere Daten in einem bestimmten Format vorliegen, normalerweise ein 3D-Array. Wir beginnen mit der Erstellung von Daten in 60 Zeitschritten und konvertieren sie mit NumPy in ein Array. Als Nächstes konvertieren wir die Daten in ein 3D-Array mit X_train Stichproben, 60 Zeitstempeln und einem Merkmal in jedem Schritt.
Aufbau des LSTM
Um den LSTM aufzubauen, müssen wir einige Module aus Keras importieren:
-
Sequentialfür die Initialisierung des neuronalen Netzes -
Densefür das Hinzufügen einer dicht verbundenen neuronalen Netzschicht -
LSTMfür das Hinzufügen der Long Short-Term Memory-Schicht -
Dropoutfür das Hinzufügen von Dropout-Schichten, die ein Overfitting verhindern
Wir fügen die LSTM-Schicht hinzu und fügen später einige Dropout-Schichten hinzu, um ein Overfitting zu verhindern. Wir fügen die LSTM-Schicht mit den folgenden Argumenten hinzu:
- 50 Einheiten, das ist die Dimensionalität des Ausgaberaums
-
return_sequences=True, die bestimmt, ob die letzte Ausgabe in der Ausgabesequenz oder die gesamte Sequenz -
input_shapeals Form unseres Trainingssets zurückgegeben wird.
Bei der Definition der Dropout-Schichten geben wir 0,2 an, was bedeutet, dass 20 % der Schichten wegfallen. Danach fügen wir die Schicht Dense hinzu, die die Ausgabe von 1 Einheit angibt. Danach kompilieren wir unser Modell mit dem beliebten Adam-Optimierer und setzen den Verlust auf mean_squarred_error. Damit wird der Mittelwert der quadrierten Fehler berechnet. Als Nächstes passen wir das Modell so an, dass es über 100 Epochen mit einer Stapelgröße von 32 läuft. Beachten Sie, dass dies je nach den Spezifikationen Ihres Computers einige Minuten dauern kann.
Vorhersage zukünftiger Aktien mithilfe des Testsatzes
Zuerst müssen wir den Testsatz importieren, den wir für unsere Vorhersagen verwenden werden.
Um zukünftige Aktienkurse vorherzusagen, müssen wir nach dem Laden des Testsatzes einige Dinge tun:
- Mischen Sie den Trainingssatz und den Testsatz auf der 0-Achse.
- Setzen Sie den Zeitschritt auf 60 (wie zuvor gesehen)
- Verwenden Sie
MinMaxScaler, um den neuen Datensatz zu transformieren - Umformen Sie den Datensatz wie zuvor
Nach der Erstellung der Vorhersagen verwenden wir inverse_transform, um die Aktienkurse in einem normal lesbaren Format zu erhalten.
Darstellung der Ergebnisse
Abschließend verwenden wir Matplotlib, um das Ergebnis des vorhergesagten Aktienkurses und des realen Aktienkurses zu visualisieren.
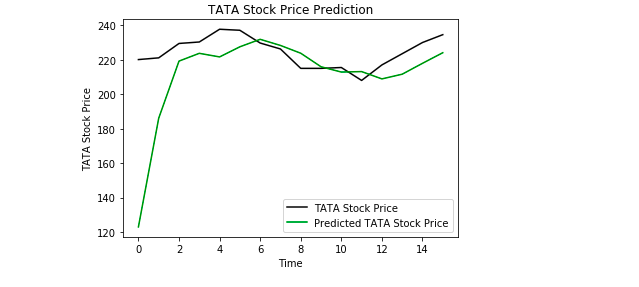
Aus der Darstellung können wir ersehen, dass der reale Aktienkurs gestiegen ist, während unser Modell auch vorhergesagt hat, dass der Aktienkurs steigen wird. Dies zeigt deutlich, wie leistungsfähig LSTMs bei der Analyse von Zeitreihen und sequentiellen Daten sind.
Schlussfolgerung
Es gibt eine Reihe anderer Techniken zur Vorhersage von Aktienkursen wie gleitende Durchschnitte, lineare Regression, K-Nearest Neighbours, ARIMA und Prophet. Diese Techniken kann man selbst testen und ihre Leistung mit der des Keras LSTM vergleichen. Wenn Sie mehr über Keras und Deep Learning erfahren möchten, finden Sie meine Artikel dazu hier und hier.
Diskutieren Sie diesen Beitrag auf Reddit und Hacker News.
Bio: Derrick Mwiti ist ein Datenanalytiker, ein Autor und ein Mentor. Sein Antrieb ist es, bei jeder Aufgabe großartige Ergebnisse zu liefern, und er ist Mentor bei Lapid Leaders Africa.
Original. Wiederveröffentlicht mit Erlaubnis.
Verwandt:
- Einführung in Deep Learning mit Keras
- Einführung in PyTorch für Deep Learning
- Der Keras 4 Step Workflow