Dateispeicherung ist eine wichtige Funktion, die in mehreren Prozessen für verschiedene Arten von Anwendungen benötigt wird. Das Vorhandensein von Prozessen wie Content Delivery Networks (CDNs), die über Cloud-Optionen von Drittanbietern wie Amazon Web Services und lokale Dateispeicheroptionen eingerichtet werden, hat es immer einfacher gemacht, eine solche Funktion zu erstellen.
Das Konzept, Dateien über einen einzigen API-Aufruf direkt in einer Datenbank zu speichern, hat mich jedoch schon seit geraumer Zeit fasziniert. An dieser Stelle kam GridFS für mich ins Spiel.

GridFS – A Layman’s Understanding
MongoDB verfügt über eine Treiberspezifikation zum Hochladen und Abrufen von Dateien namens GridFS. GridFS erlaubt es, Dateien zu speichern und abzurufen, auch solche, die die Größenbeschränkung des BSON-Dokuments von 16 MB überschreiten.
GridFS zerlegt eine Datei in mehrere Chunks, die als einzelne Dokumente in zwei Sammlungen gespeichert werden:
- die
chunk-Sammlung (speichert die Dokumentteile) und - die
file-Sammlung (speichert die dazugehörigen zusätzlichen Metadaten).
Jeder Chunk ist auf eine Größe von 255 KB begrenzt. Das bedeutet, dass der letzte Chunk normalerweise entweder gleich oder kleiner als 255 KB ist. Klingt recht ordentlich.
Beim Lesen aus GridFS setzt der Treiber alle Chunks nach Bedarf neu zusammen. Das bedeutet, dass Sie Abschnitte einer Datei entsprechend Ihrem Abfragebereich lesen können. So können Sie beispielsweise ein Segment einer Audiodatei anhören oder einen Abschnitt einer Videodatei abrufen.
Hinweis: Für die Speicherung von Dateien, die normalerweise die Größenbeschränkung von 16 MB überschreiten, wird vorzugsweise GridFS verwendet. Für kleinere Dateien wird empfohlen, das BinData-Format zu verwenden, um die Dateien in einzelnen Dokumenten zu speichern.
Dies fasst zusammen, wie GridFS im Allgemeinen funktioniert. Es ist an der Zeit, dass wir uns in einen funktionierenden Code vertiefen und sehen, wie man ein solches System implementiert.
Genug geredet, zeig mir den Code
Wir verwenden Node.js mit Zugriff auf eine Cloud-Instanz von MongoDB für unser Setup. Das Code-Repository für die Beispielanwendung finden Sie hier.
 tarique93102GitHub
tarique93102GitHub 
Wir werden uns voll und ganz auf Segmente des Codes konzentrieren, die sich auf die Funktionalitäten von GridFS beziehen. Wir werden lernen, wie man es einrichtet und verwendet, um Dateien zu speichern, Dateien oder eine bestimmte Datei abzurufen und eine bestimmte Datei zu löschen. Fangen wir also an.
Initialize the Storage Engine
Die Pakete, die zum Initialisieren der Engine benötigt werden, sind multer-gridfs-storage und multer. Außerdem verwenden wir method-override Middleware, um den Löschvorgang für Dateien zu ermöglichen. Das npm-Modul crypto wird verwendet, um die Dateinamen beim Speichern und Lesen aus der Datenbank zu verschlüsseln.
Nachdem die Speicher-Engine mit GridFS initialisiert wurde, muss sie nur noch über die Multer-Middleware aufgerufen werden. Sie wird dann an die jeweilige Route übergeben, die die verschiedenen Dateispeicheroperationen ausführt.
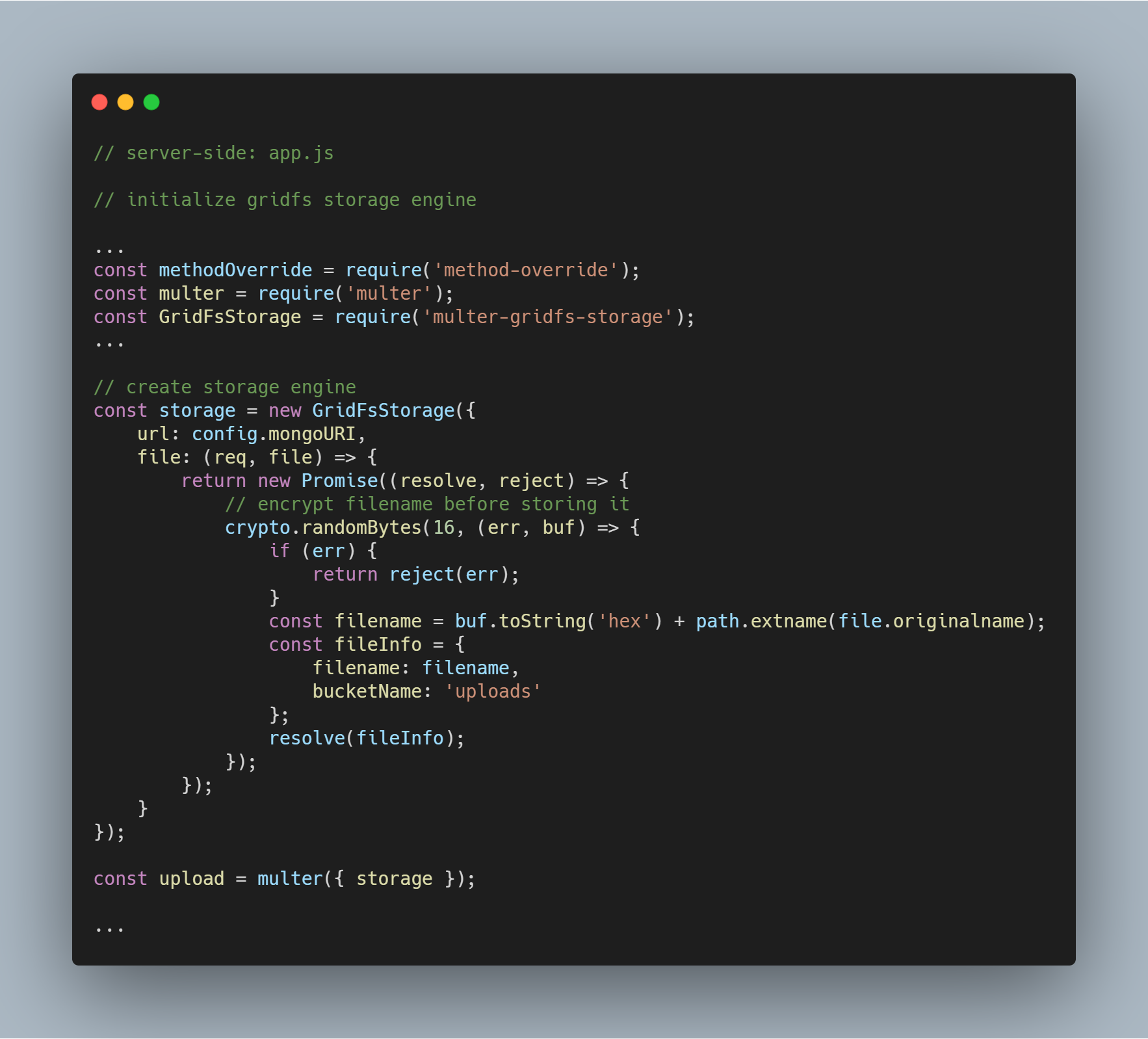
GridFS-Stream initialisieren
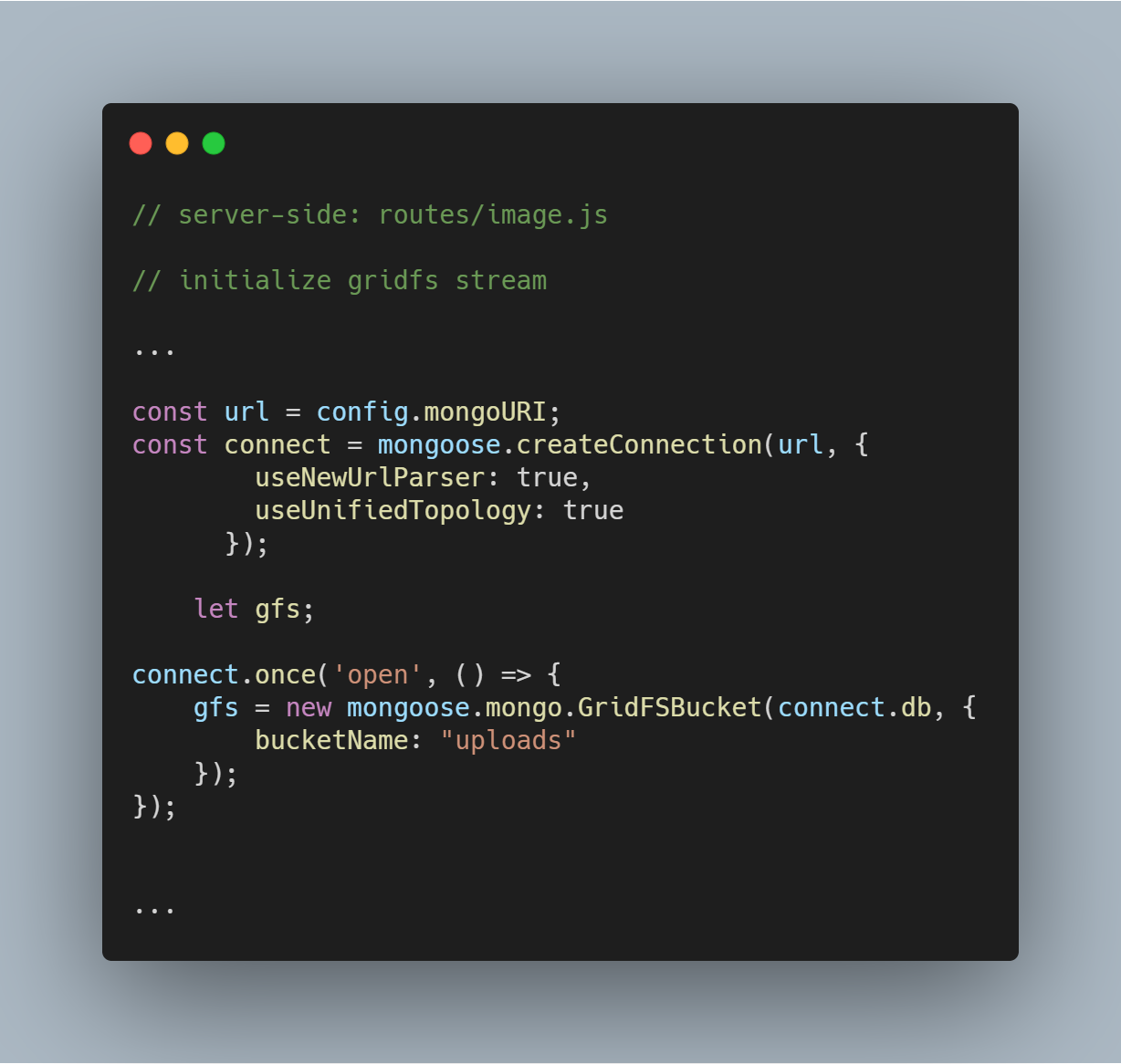
Wir initialisieren einen GridFS-Stream, wie im folgenden Code zu sehen. Der Stream wird benötigt, um die Dateien aus der Datenbank zu lesen und auch, um bei Bedarf ein Bild in einem Browser zu rendern.
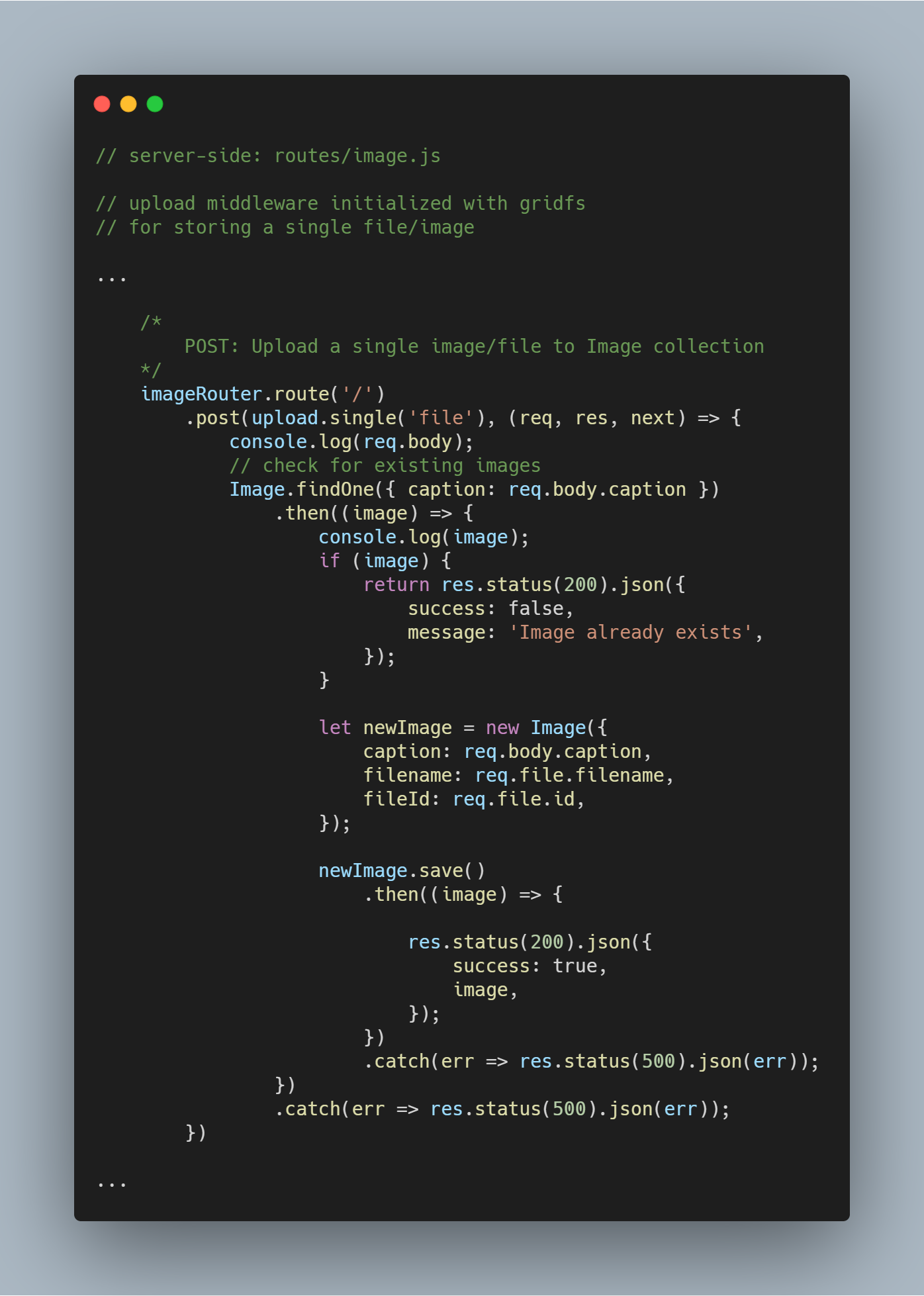
Hochladen einer einzelnen Datei oder eines Bildes
Wir verwenden die Upload-Middleware, die wir zuvor erstellt hatten, wieder.
Hinweis: Der Name file wird als Parameter in upload.single() verwendet, da wir den Schlüssel mit einem ähnlichen Namen haben, der die vom Client gesendete Datei trägt.
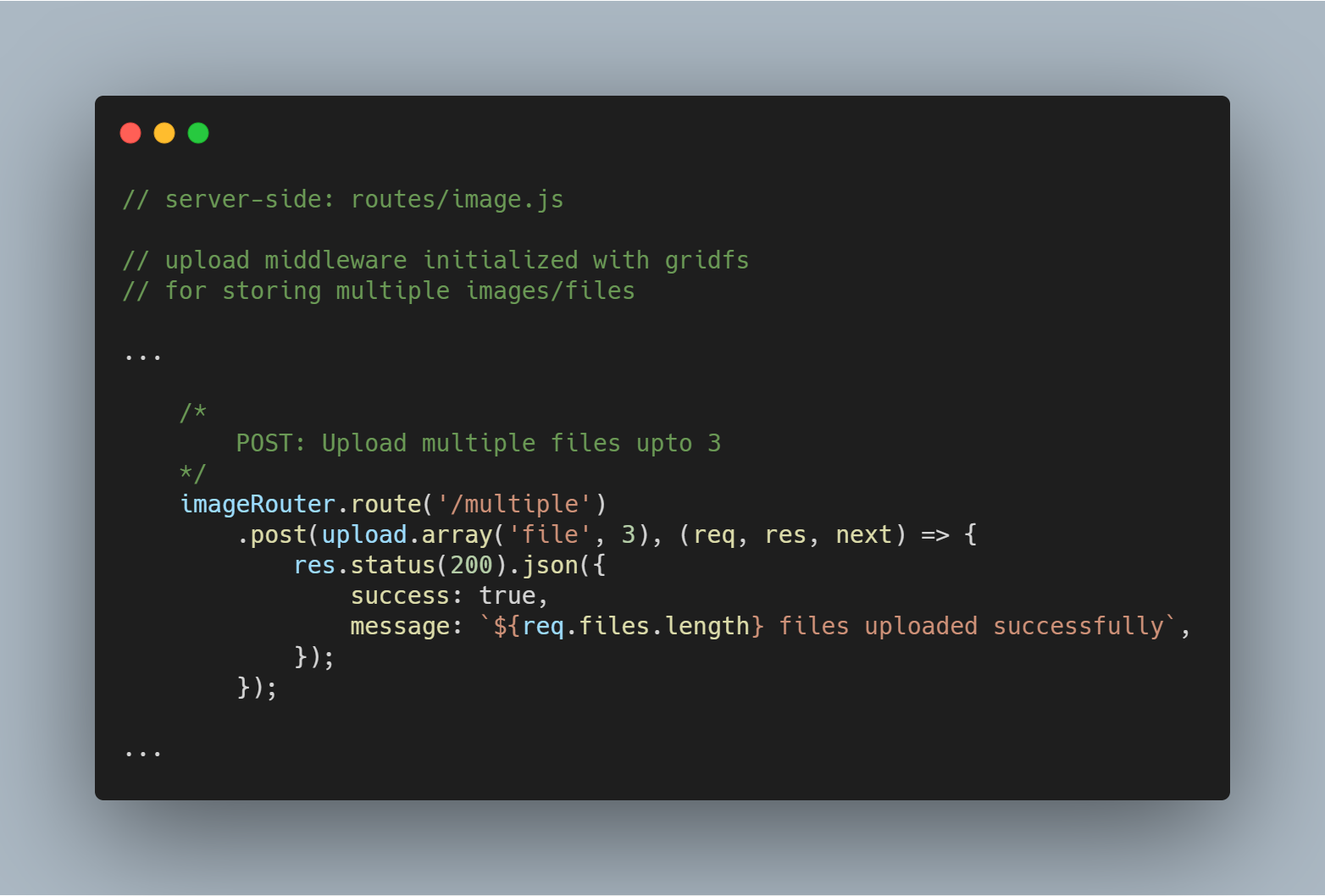
Mehrere Dateien oder Bilder hochladen
Wir können auch mehrere Dateien auf einmal hochladen. Anstelle von upload.single() müssen wir einfach upload.multiple(<number of files>) verwenden.
Hinweis: Die Anzahl der hochgeladenen Dateien kann geringer sein als die festgelegte Anzahl der Dateien.
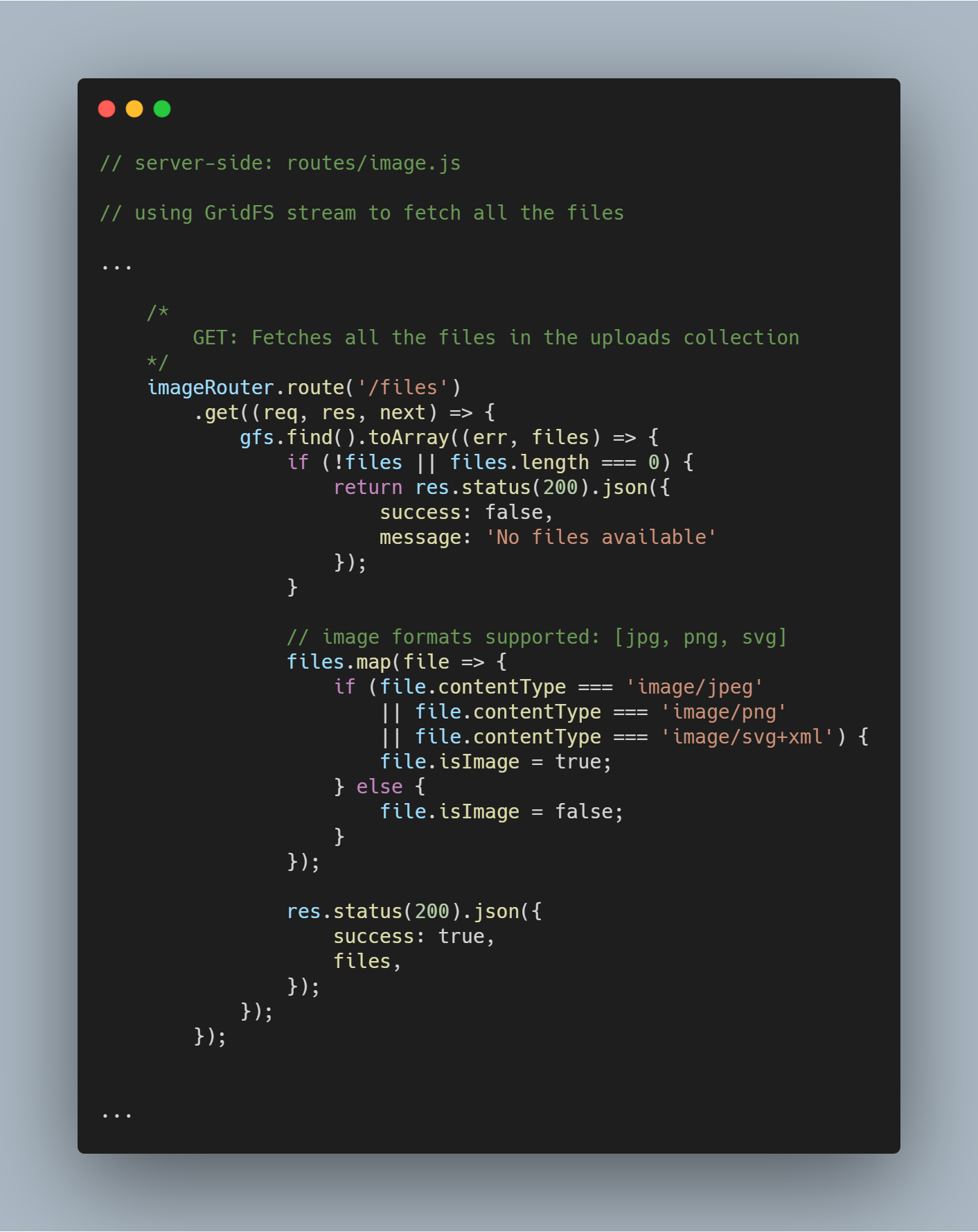
Alle Dateien aus der Datenbank abrufen
Mit Hilfe des initialisierten Streams können wir alle Dateien in der bestimmten Datenbank mit gfs.find().toArray(...) abrufen. Sobald die Dateien erhalten sind, ordnen wir sie einem Array zu und liefern die Antwort.
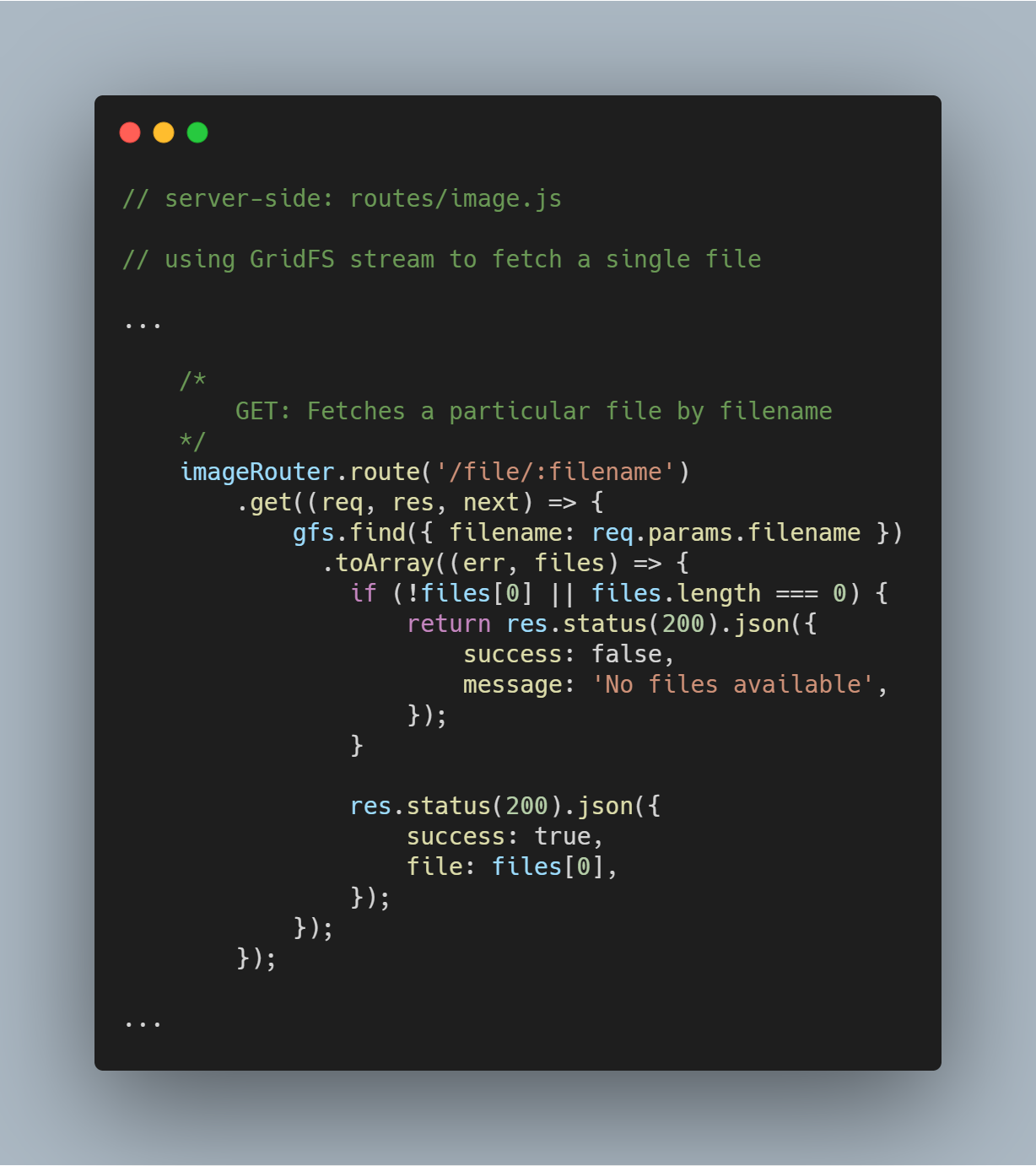
Eine einzelne Datei nach Dateiname abrufen
Es ist super einfach, GridFS nach einer einzelnen Datei auf der Grundlage eines bestimmten Attributs wie filename abzufragen. Mit dem GridFS-Stream kann man die Datenbank über die Funktion gfs.find({<add query here>}) abfragen.
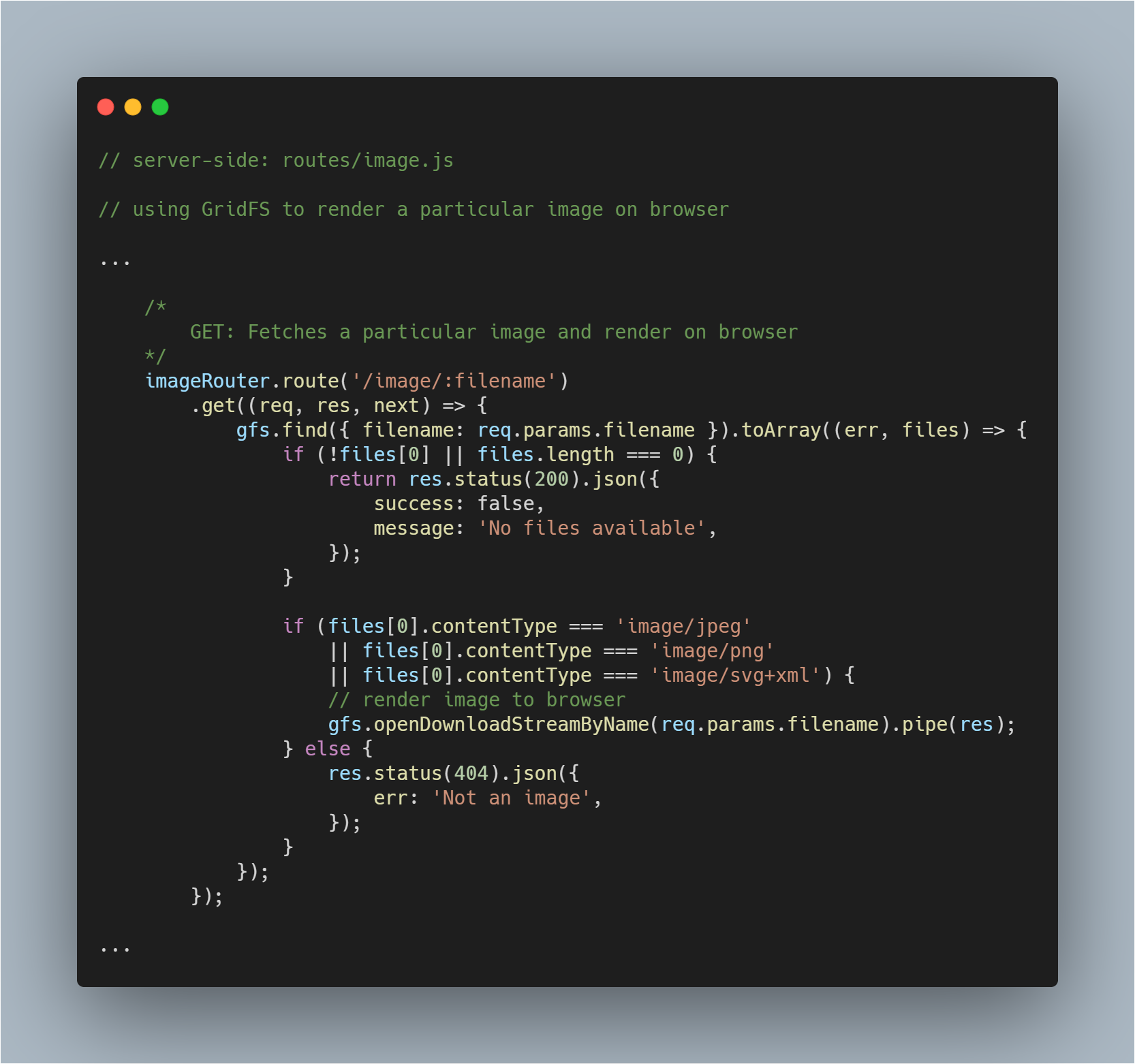
Rendering a Fetched Image to Browser
Dies ist ein etwas schwierigerer Teil, da man nicht nur eine Datei aus der Datenbank holen muss, sondern sie auch als Bild auf dem jeweiligen Browser rendern muss. Wir rufen die Datei ganz normal ab.
Dann können wir mit Hilfe der Methode openDownloadStreamByName() auf gfs stream ein Bild einfach rendern, da sie einen lesbaren Stream zurückgibt. Danach können wir die JavaScript-Methode pipe() verwenden, um die Antwort zu streamen.
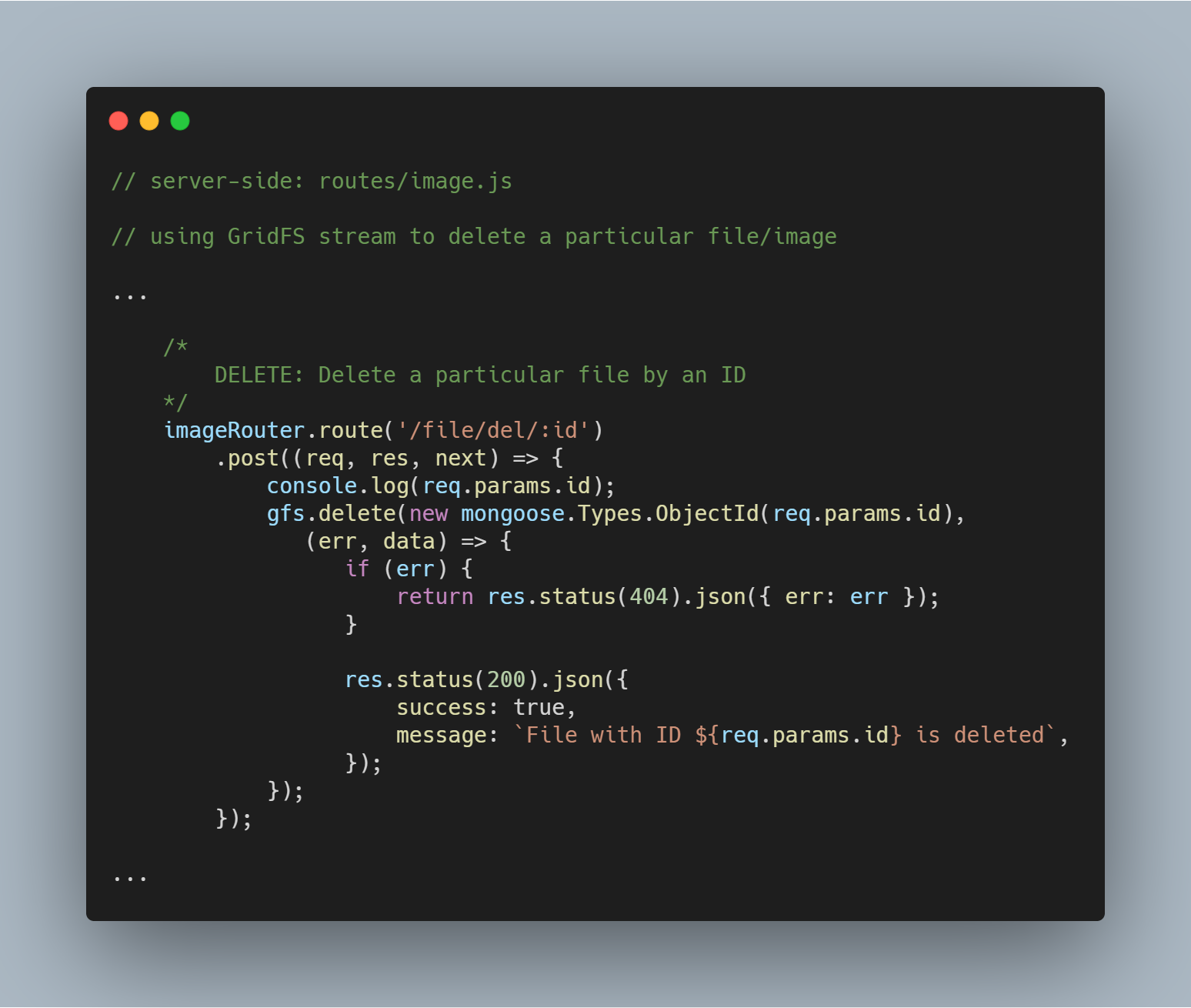
Löschen einer bestimmten Datei nach Id
Das Löschen einer Datei ist ebenso einfach. Wir verwenden die Stream-Methode delete() mit dem Parameter _id, um die betreffende Datei abzufragen und zu löschen.
Das sind die wichtigsten Funktionen, die das Design der Storage Engine bietet. Ich habe die besprochenen GridFS-Funktionen genutzt, um eine einfache Anwendung zum Hochladen von Bildern zu erstellen. Sie können sich den Code im Respository genauer ansehen.
Abschluss
Es hat mich einige Zeit und einige Mühe gekostet zu verstehen, wie man GridFS für ein persönliches Projekt nutzen kann. Aus diesem Grund wollte ich sicherstellen, dass zumindest eine andere Person nicht die gleiche Zeit investieren muss.
Dennoch würde ich empfehlen, GridFS mit Vorsicht zu genießen. Es ist kein Allheilmittel für alle Ihre Dateispeicherprobleme. Dennoch ist es eine nützliche Spezifikation, die man kennen und beachten sollte.