Ukládání souborů je důležitou funkcí, která je vyžadována v mnoha procesech v různých typech aplikací. Existence procesů jako Content Delivery Networks (CDNs), nastavených prostřednictvím cloudových možností třetích stran, jako je Amazon Web Services, a lokálních možností ukládání souborů vždy usnadňovala vytvoření takové funkce.
Koncept ukládání souborů přímo do databáze prostřednictvím jediného volání API mě však zaujal již delší dobu. Tehdy mi přišel na mysl systém GridFS.

GridFS – laické pochopení
MongoDB má specifikaci ovladače pro nahrávání a načítání souborů z ní nazvanou GridFS. GridFS umožňuje ukládat a načítat soubory, což zahrnuje i ty, které přesahují limit velikosti dokumentu BSON 16 MB.
GridFS v podstatě vezme soubor a rozdělí ho na několik částí, které jsou uloženy jako jednotlivé dokumenty ve dvou kolekcích:
- kolekce
chunk(ukládá části dokumentu) a - kolekce
file(ukládá následná další metadata).
Každá část je omezena na velikost 255 KB. To znamená, že poslední chunk je obvykle buď rovný, nebo menší než 255 KB. To zní docela elegantně.
Při čtení ze systému GridFS ovladač znovu sestaví všechny chunky podle potřeby. To znamená, že můžete číst části souboru podle rozsahu dotazu. Například poslech úseku zvukového souboru nebo načtení úseku videosouboru.
Poznámka: Pro ukládání souborů běžně přesahujících limit velikosti 16 MB se upřednostňuje použití systému GridFS. Pro menší soubory se doporučuje použít formát BinData pro ukládání souborů v jednotlivých dokumentech.
Toto shrnuje, jak systém GridFS obecně funguje. Je čas ponořit se do funkčního kódu a podívat se, jak takový systém implementovat.
Dost bylo řečí, ukažte mi kód
Pro naše nastavení používáme Node.js s přístupem ke cloudové instanci MongoDB. Úložiště kódu ukázkové aplikace najdete zde.
 tarique93102GitHub
tarique93102GitHub 
Zcela se zaměříme na segmenty kódu, které se týkají funkcí systému GridFS. Naučíme se jej nastavit a používat k ukládání souborů, načítání souborů nebo konkrétního souboru a mazání konkrétního souboru. Začněme tedy.
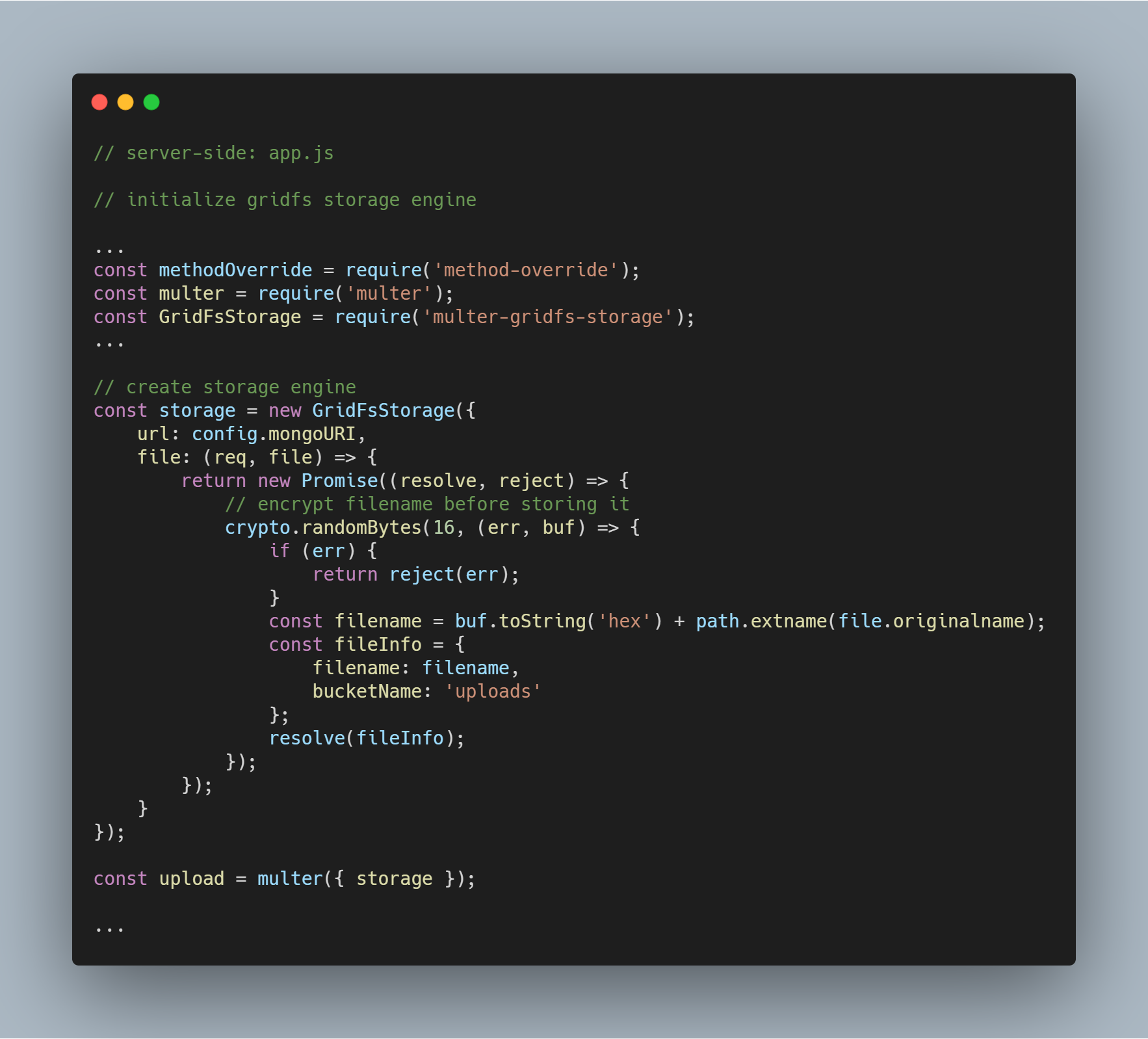
Inicializace úložného mechanismu
K inicializaci mechanismu jsou potřeba balíčky multer-gridfs-storage a multer. Použijeme také middleware method-override, abychom umožnili operaci mazání souborů. Modul npm crypto slouží k šifrování názvů souborů při ukládání a čtení z databáze.
Po inicializaci úložného enginu využívajícího GridFS jej stačí zavolat pomocí middlewaru multer. Ten je pak předán příslušné trase provádějící různé operace ukládání souborů.
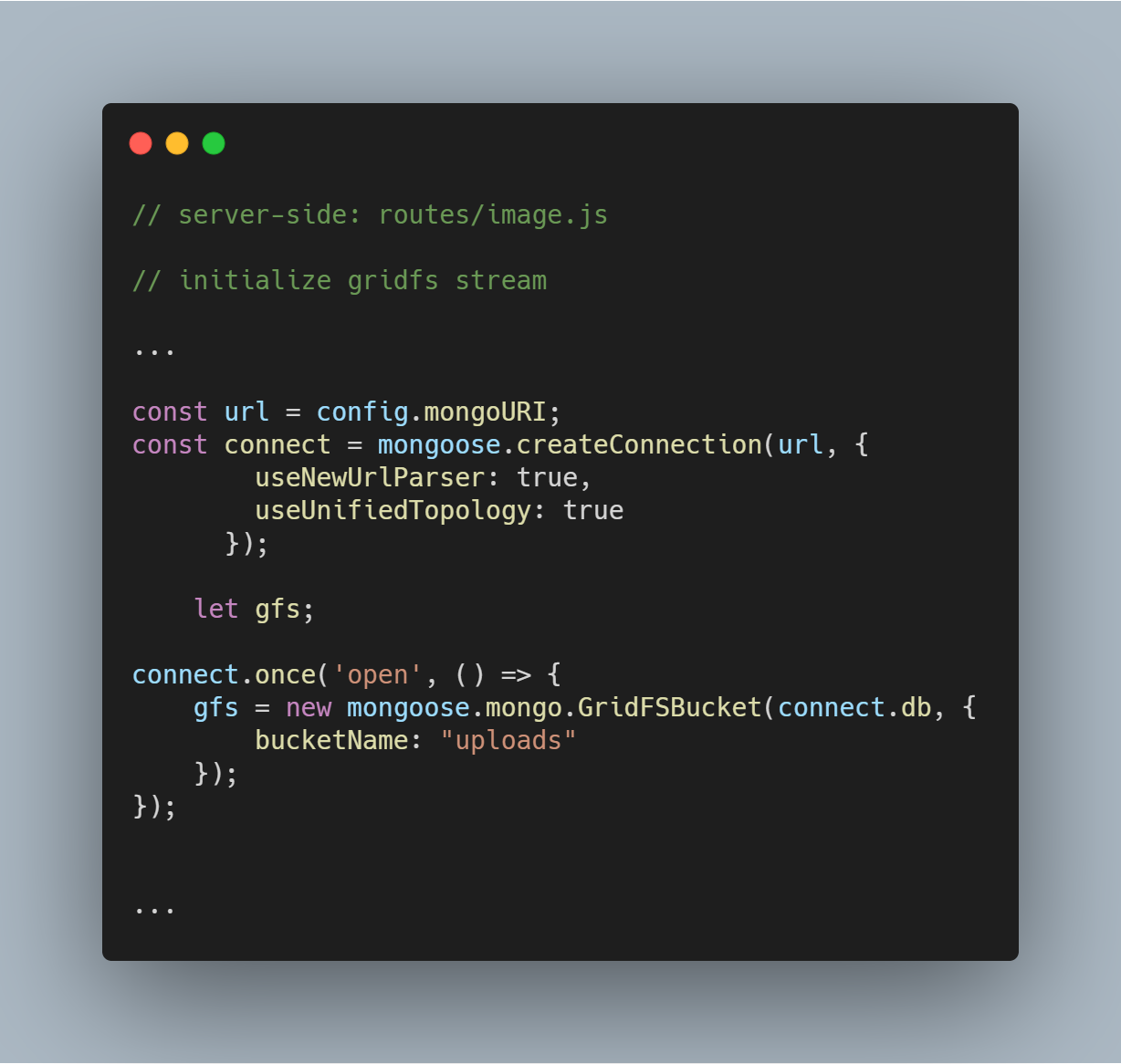
Inicializace proudu GridFS
Proud GridFS inicializujeme, jak je vidět v následujícím kódu. Proud je potřebný ke čtení souborů z databáze a také k tomu, aby v případě potřeby pomohl vykreslit obrázek do prohlížeče.
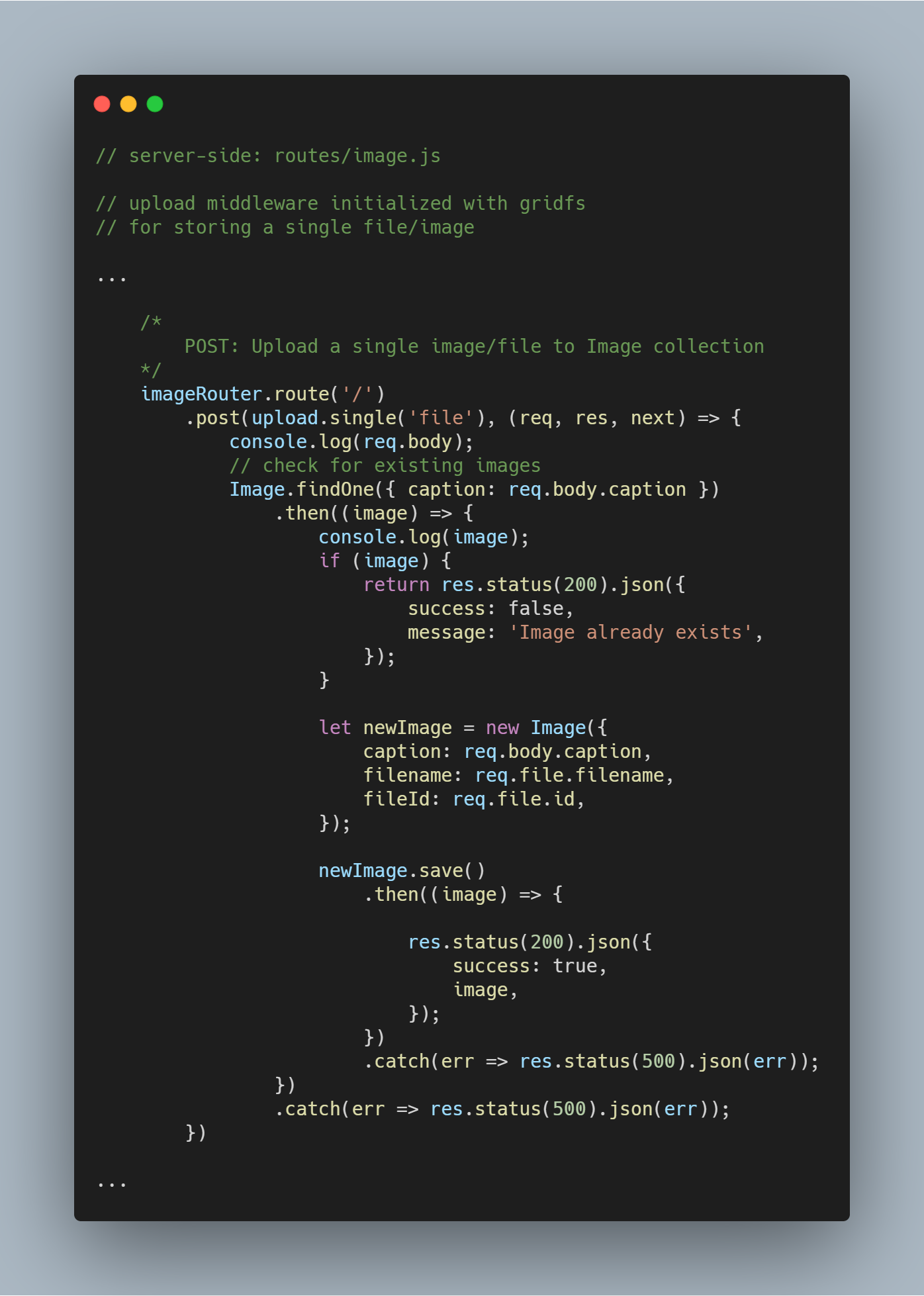
Nahrát jeden soubor nebo obrázek
Znovu použijeme middleware pro nahrávání, který jsme vytvořili dříve.
Poznámka: Název file je použit jako parametr v upload.single(), protože máme klíč s podobným názvem nesoucí soubor odesílaný z klienta.
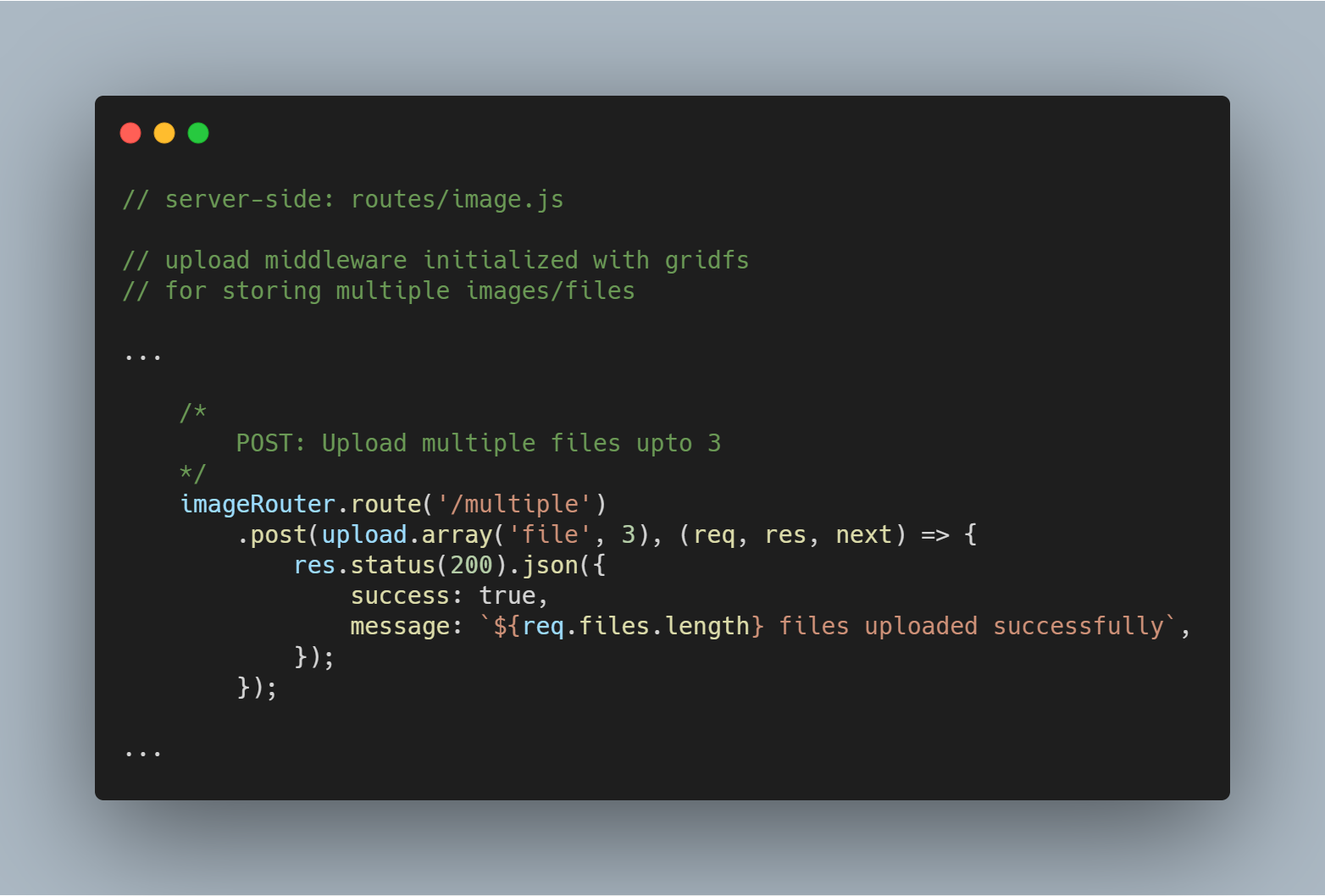
Nahrát více souborů nebo obrázků
Můžeme také nahrát více souborů najednou. Místo upload.single() musíme jednoduše použít upload.multiple(<number of files>).
Poznámka: Počet nahrávaných souborů může být menší než definovaný počet souborů.
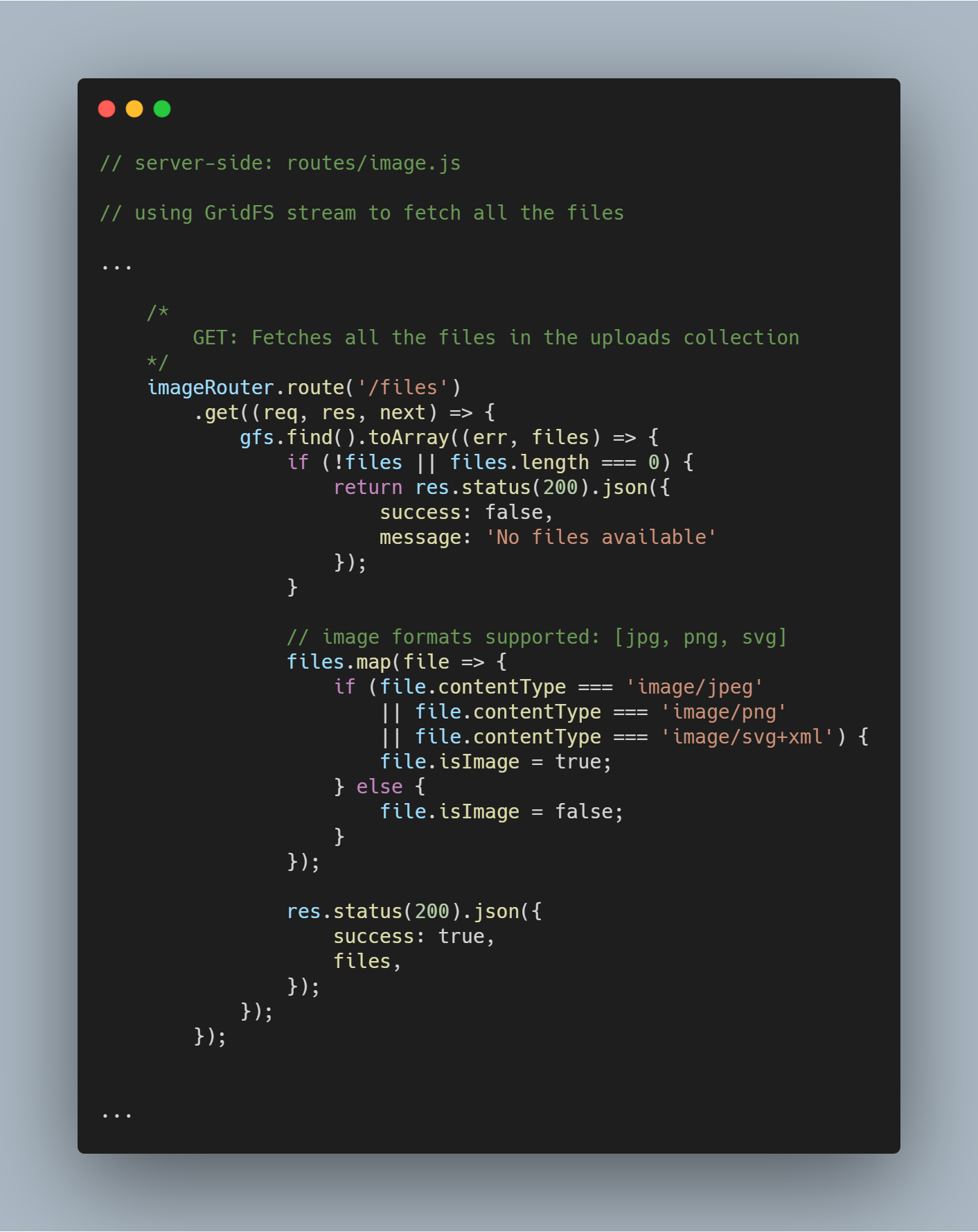
Vybrat všechny soubory z databáze
Pomocí inicializovaného streamu můžeme pomocí gfs.find().toArray(...) vybrat všechny soubory v dané databázi. Po získání souborů je namapujeme na pole a odešleme odpověď.
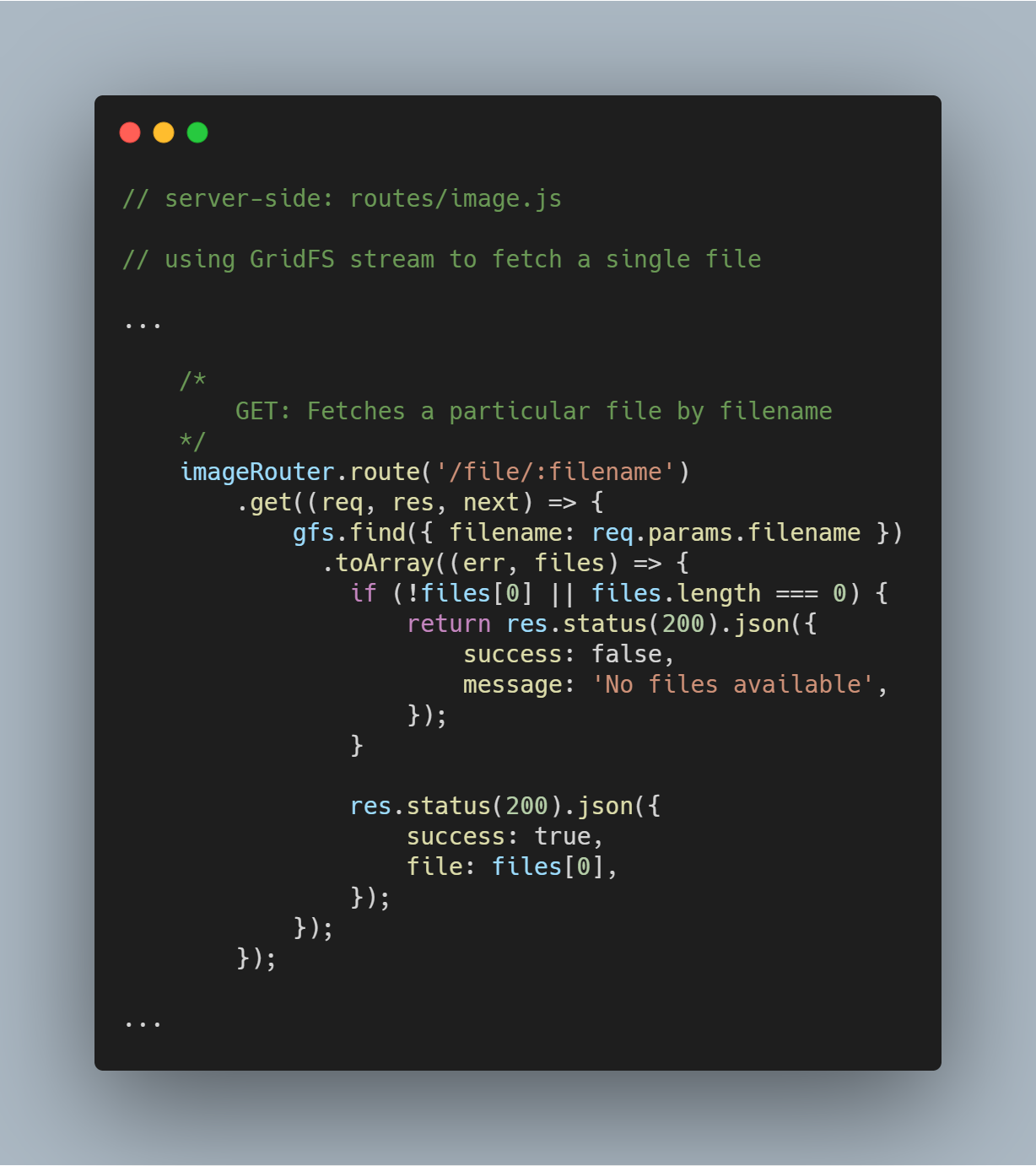
Vyhledání jednoho souboru podle názvu souboru
Je velmi jednoduché dotazovat se systému GridFS na jeden soubor na základě určitého atributu, například filename. Pomocí proudu GridFS se můžete dotazovat do databáze prostřednictvím funkce gfs.find({<add query here>}).
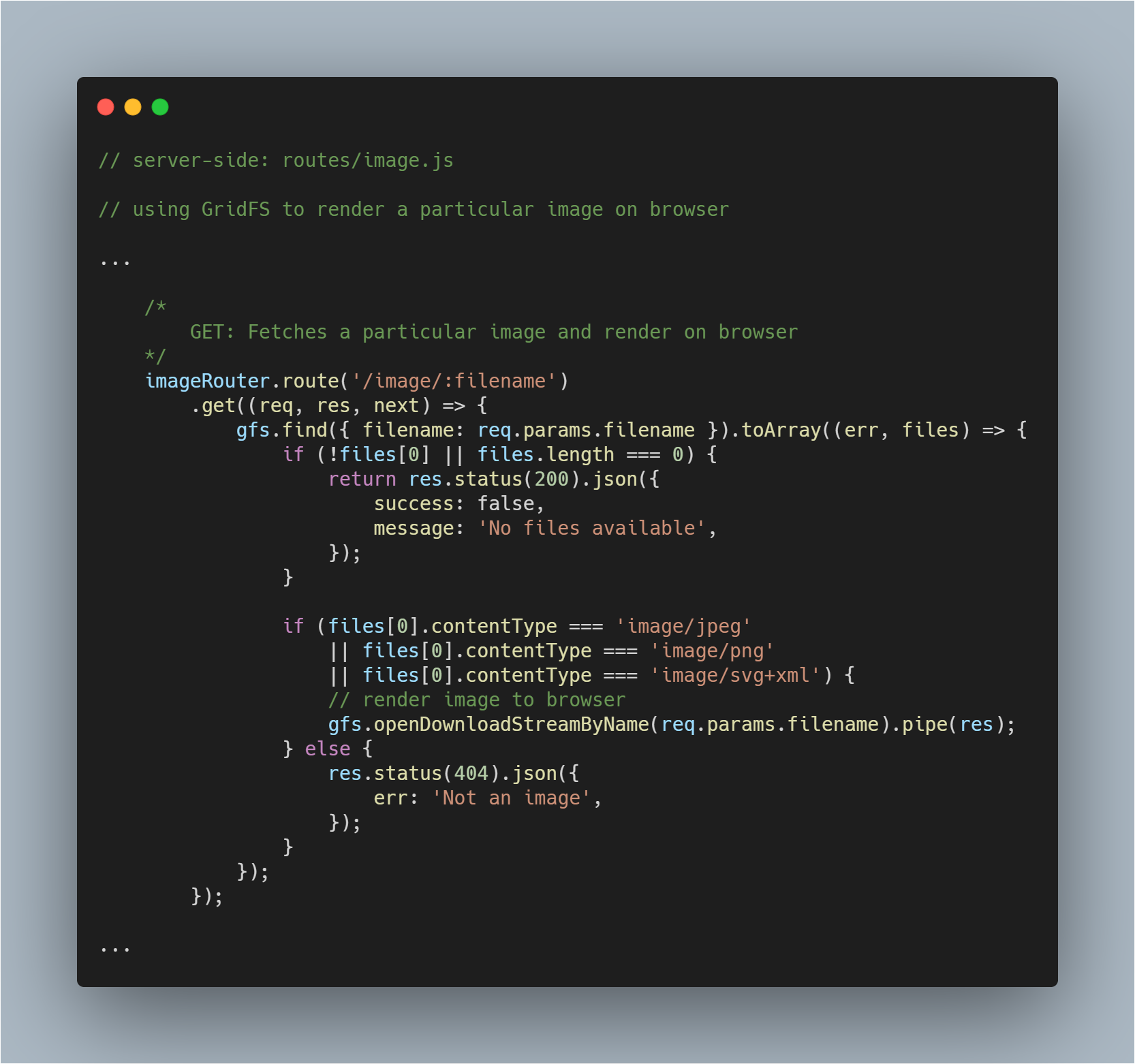
Vyrenderovat načtený obrázek do prohlížeče
Tato část je poněkud složitější, protože musíte nejen načíst soubor z databáze, ale také jej vykreslit jako obrázek v příslušném prohlížeči. Soubor načteme normálně. V tomto procesu se nic nemění.
Poté pomocí metody openDownloadStreamByName() na gfs stream můžeme snadno vykreslit obrázek, protože vrací čitelný stream. Poté, co jsme tak učinili, můžeme použít funkci pipe() jazyka JavaScript pro streamování odpovědi.
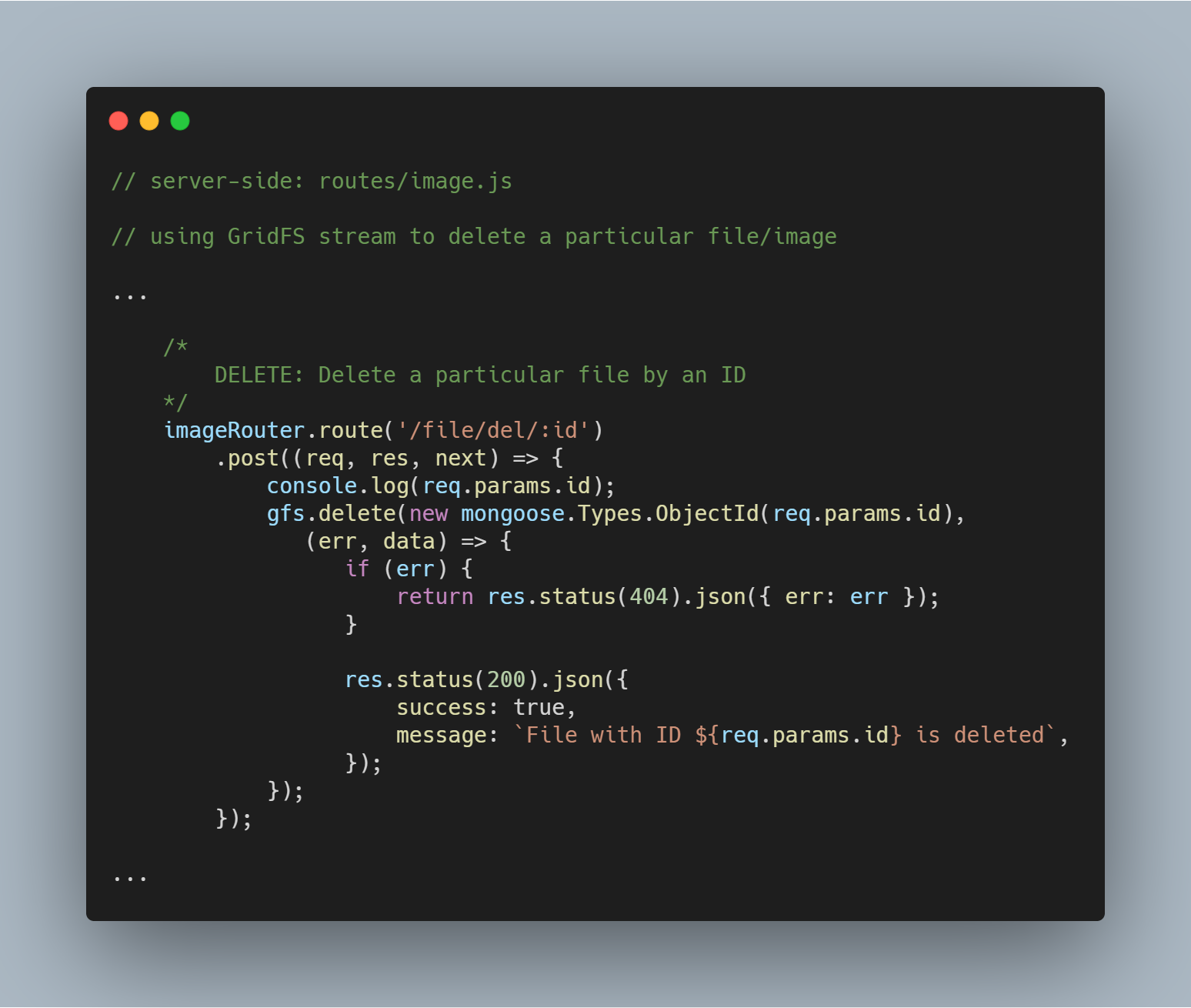
Odstranění konkrétního souboru podle ID
Stejně jednoduché je i odstranění souboru. K dotazu a smazání příslušného souboru použijeme proudovou metodu delete() s parametrem _id.
To jsou hlavní funkce, které nabízí návrh storage engine. Probírané funkce systému GridFS jsem využil k vytvoření jednoduché aplikace pro nahrávání obrázků. Do kódu se můžete hlouběji ponořit v respozitáři.
Závěr
Pochopit, jak využít GridFS pro osobní projekt, mi zabralo nějaký čas a slušnou námahu. Z tohoto důvodu jsem se chtěl ujistit, že alespoň jeden další člověk nemusí investovat stejné množství času.
Přesto bych doporučil používat GridFS s rozvahou. Není to stříbrná kulka na všechny vaše starosti s ukládáním souborů. Přesto je to šikovná specifikace, kterou je třeba znát a vědět o ní.