Od Derricka Mwitiho, datového analytika

Poznámka redakce: Tento návod ukazuje, jak začít předpovídat časové řady pomocí modelů LSTM. Data z akciového trhu jsou pro tento účel skvělou volbou, protože jsou poměrně pravidelná a široce dostupná všem. Neberte to prosím jako finanční radu ani to nepoužívejte k provádění vlastních obchodů.
V tomto tutoriálu vytvoříme model hlubokého učení v jazyce Python, který bude předpovídat budoucí chování cen akcií. Předpokládáme, že čtenář je obeznámen s koncepty hlubokého učení v jazyce Python, zejména s dlouhodobou krátkodobou pamětí.
Předpovídat aktuální cenu akcií je sice obtížné, ale můžeme vytvořit model, který bude předpovídat, zda cena poroste, nebo klesne. Data a notebook použitý pro tento tutoriál naleznete zde. Je důležité si uvědomit, že vždy existují další faktory, které ovlivňují ceny akcií, například politická atmosféra a trh. Pro tento tutoriál se však na tyto faktory nebudeme zaměřovat.
Úvod
LSTM jsou velmi výkonné v problémech předpovídání posloupnosti, protože jsou schopny uchovávat minulé informace. To je v našem případě důležité, protože předchozí cena akcie je klíčová pro předpovídání její budoucí ceny.
Začneme importem NumPy pro vědecké výpočty, Matplotlib pro vykreslování grafů a Pandas pro pomoc při načítání a manipulaci s našimi soubory dat.
Načítání datové sady
Dalším krokem je načtení naší trénovací datové sady a výběr Open a Highsloupců, které budeme používat při modelování.
Zkontrolujeme záhlaví našeho souboru dat, abychom si udělali představu o tom, s jakým souborem dat pracujeme.
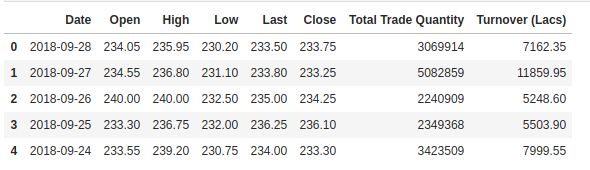
Sloupec Open je počáteční cena, zatímco sloupec Close je konečná cena akcie v určitý obchodní den. Sloupce High a Low představují nejvyšší a nejnižší cenu za určitý den.
Škálování funkcí
Z předchozích zkušeností s modely hlubokého učení víme, že pro optimální výkon musíme data škálovat. V našem případě použijeme funkci MinMaxScaler Scikit- Learn a škálujeme naši datovou sadu na čísla mezi nulou a jedničkou.
Vytváření dat pomocí časových kroků
LSTM očekávají, že naše data budou ve specifickém formátu, obvykle ve 3D poli. Začneme vytvořením dat v 60 časových krocích a jejich převedením do pole pomocí NumPy. Poté převedeme data do 3D rozměrového pole s X_train vzorky, 60 časovými značkami a jednou funkcí v každém kroku.
Sestavení LSTM
Pro sestavení LSTM musíme importovat několik modulů z Keras:
-
Sequentialpro inicializaci neuronové sítě -
Densepro přidání vrstvy hustě propojené neuronové sítě -
LSTMpro přidání vrstvy Long Short-Term Memory -
Dropoutpro přidání dropout vrstev, které zabraňují overfittingu
Přidáme vrstvu LSTM a později přidáme několik vrstev Dropout pro zabránění overfittingu. Přidáme vrstvu LSTM s následujícími argumenty:
- 50 jednotek, což je dimenzionalita výstupního prostoru
-
return_sequences=True, která určuje, zda vrátíme poslední výstup ve výstupní posloupnosti, nebo celou posloupnost -
input_shapejako tvar naší trénovací množiny.
Při definování vrstev Dropout zadáme 0,2, což znamená, že 20 % vrstev bude vypuštěno. Poté přidáme vrstvu Dense, která určuje výstup 1 jednotky. Poté sestavíme náš model pomocí oblíbeného optimalizátoru adam a nastavíme ztrátu jako mean_squarred_error. Tím se vypočítá střední hodnota čtvercových chyb. Poté model přizpůsobíme tak, aby běžel na 100 epochách s velikostí dávky 32. Mějte na paměti, že v závislosti na specifikacích vašeho počítače může dokončení běhu trvat několik minut.
Předpovídání budoucích zásob pomocí testovací množiny
Nejprve musíme importovat testovací množinu, na které budeme provádět předpovědi.
Abychom mohli předpovídat budoucí ceny akcií, musíme po načtení testovací množiny provést několik úkonů:
- Spojit trénovací a testovací množinu na ose 0.
- Předpovídat budoucí ceny akcií.
- Nastavit časový krok na 60 (jak jsme viděli dříve)
- Pomocí
MinMaxScalertransformovat novou množinu dat - Resetovat množinu dat, jak bylo provedeno dříve
Po provedení předpovědí použijeme
inverse_transform, abychom získali zpět ceny akcií v normálním čitelném formátu.Kreslení výsledků
Nakonec použijeme Matplotlib k vizualizaci výsledku předpovězené ceny akcií a skutečné ceny akcií.
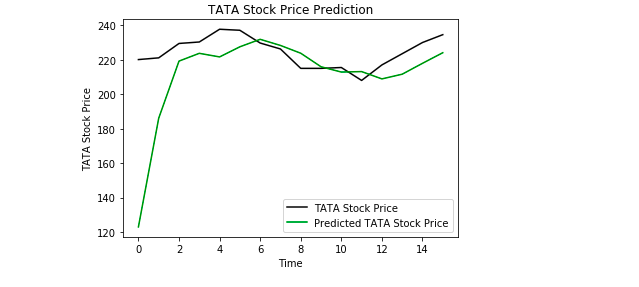
Z grafu vidíme, že skutečná cena akcií stoupla, zatímco náš model také předpověděl, že cena akcií stoupne. To jasně ukazuje, jak výkonné jsou LSTM pro analýzu časových řad a sekvenčních dat.
Závěr
Existuje několik dalších technik předpovídání cen akcií, například klouzavé průměry, lineární regrese, K-Nearest Neighbours, ARIMA a Prophet. Tyto techniky lze testovat samostatně a porovnat jejich výkonnost s Keras LSTM. Pokud se chcete o Kerasu a hlubokém učení dozvědět více, najdete mé články na toto téma zde a zde.
Diskutujte o tomto příspěvku na Redditu a Hacker News.
Bio: Derrick Mwiti je datový analytik, spisovatel a mentor. Jeho hnacím motorem je dosahování skvělých výsledků v každém úkolu a je mentorem ve společnosti Lapid Leaders Africa.
Původní text. Přetištěno se svolením autora.
Související:
- Úvod do hlubokého učení s Kerasem
- Úvod do PyTorchu pro hluboké učení
- Pracovní postup Keras 4 kroky
.